

En el cambiante panorama de la inteligencia artificial, 2025 ha sido testigo de avances significativos en los modelos de lenguaje de gran tamaño (LLM). Entre los pioneros se encuentran Qwen2.5 de Alibaba, los modelos V3 y R1 de DeepSeek y ChatGPT de OpenAI. Cada uno de estos modelos aporta capacidades e innovaciones únicas. Este artículo profundiza en los últimos avances en torno a Qwen2.5, comparando sus características y rendimiento con DeepSeek y ChatGPT para determinar qué modelo lidera actualmente la carrera de la IA.
¿Qué es Qwen2.5?
Descripción general
Qwen 2.5 es el último modelo de lenguaje denso y de gran tamaño de Alibaba Cloud, basado únicamente en decodificador, disponible en varios tamaños, desde 0.5 B hasta 72 B de parámetros. Está optimizado para el seguimiento de instrucciones, la generación de salidas estructuradas (p. ej., JSON, tablas), la codificación y la resolución de problemas matemáticos. Compatible con más de 29 idiomas y con una longitud de contexto de hasta 128 2.5 tokens, Qwen XNUMX está diseñado para aplicaciones multilingües y específicas de cada dominio.
Características clave
- Soporte multilingüe:Admite más de 29 idiomas y satisface las necesidades de una base de usuarios global.
- Longitud del contexto extendido:Maneja hasta 128K tokens, lo que permite el procesamiento de documentos y conversaciones largos.
- Variantes especializadas:Incluye modelos como Qwen2.5-Coder para tareas de programación y Qwen2.5-Math para la resolución de problemas matemáticos.
- Accesibilidad:Disponible a través de plataformas como Hugging Face, GitHub y una interfaz web recientemente lanzada en chat.qwenlm.ai.
¿Cómo utilizar Qwen 2.5 localmente?
A continuación se muestra una guía paso a paso para 7 B Chat punto de control; los tamaños más grandes difieren solo en los requisitos de GPU.
1. Requisitos previos del hardware
| Modelo | vRAM para 8 bits | vRAM para 4 bits (QLoRA) | Tamaño del disco |
|---|---|---|---|
| Qwen 2.5‑7B | 14 GB | 10 GB | 13 GB |
| Qwen 2.5‑14B | 26 GB | 18 GB | 25 GB |
Una sola RTX 4090 (24 GB) es suficiente para una inferencia de 7 B con una precisión completa de 16 bits; dos tarjetas de este tipo o la descarga de CPU más la cuantificación pueden manejar 14 B.
2. Instalación
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. Guión de inferencia rápida
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
El elemento trust_remote_code=True Se requiere la bandera porque Qwen envía una personalizada Incrustación de posición rotatoria envoltura.
4. Ajuste fino con LoRA
Gracias a los adaptadores LoRA con parámetros eficientes, puede entrenar Qwen de manera especializada en ~50 K pares de dominios (por ejemplo, médicos) en menos de cuatro horas en una sola GPU de 24 GB:
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
El archivo adaptador resultante (~120 MB) se puede volver a fusionar o cargar a pedido.
Opcional: Ejecute Qwen 2.5 como API
CometAPI actúa como un centro centralizado para las API de varios modelos de IA líderes, lo que elimina la necesidad de interactuar con múltiples proveedores de API por separado. CometAPI Ofrece un precio mucho más bajo que el oficial para ayudarte a integrar Qwen API. ¡Recibirás $1 en tu cuenta tras registrarte e iniciar sesión! Bienvenido a registrarte y probar CometAPI. Para desarrolladores que buscan integrar Qwen 2.5 en sus aplicaciones:
Paso 1: Instalar las bibliotecas necesarias:
bash
pip install requests
Paso 2: obtener la clave API
- Navegue a CometAPI.
- Inicie sesión con su cuenta de CometAPI.
- Seleccione la opción Panel.
- Haga clic en “Obtener clave API” y siga las instrucciones para generar su clave.
Paso 3: Implementar llamadas API
Utilice las credenciales de la API para realizar solicitudes a Qwen 2.5. Reemplazar con su clave CometAPI real de su cuenta.
Por ejemplo, en Python:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
Esta integración permite la incorporación perfecta de las capacidades de Qwen 2.5 en varias aplicaciones, mejorando la funcionalidad y la experiencia del usuario.Seleccione el “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” Punto final para enviar la solicitud de API y configurar el cuerpo de la solicitud. El método y el cuerpo de la solicitud se obtienen de la documentación de la API de nuestro sitio web. Nuestro sitio web también ofrece la prueba de Apifox para su comodidad.
Por favor, consulte API máxima de Qwen 2.5 Para obtener detalles de integración, CometAPI ha actualizado la última versión. API QwQ-32BPara obtener más información sobre el modelo en Comet API, consulte Documento API.
Mejores prácticas y consejos
| Guión | Recomendación |
|---|---|
| Preguntas y respuestas sobre documentos extensos | Divida los pasajes en ≤16 K tokens y utilice indicaciones de recuperación aumentada en lugar de contextos ingenuos de 100 K para reducir la latencia. |
| Productos estructurados | Anteponga al mensaje del sistema lo siguiente: You are an AI that strictly outputs JSON. El entrenamiento de alineación de Qwen 2.5 se destaca en la generación restringida. |
| Completar código | Establecer temperature=0.0 y top_p=1.0 Para maximizar el determinismo, entonces muestree múltiples haces (num_return_sequences=4) para la clasificación. |
| Filtrado de seguridad | Utilice el paquete de expresiones regulares “Qwen-Guardrails” de código abierto de Alibaba o text-moderation-004 de OpenAI como primer paso. |
Limitaciones conocidas de Qwen 2.5
- Susceptibilidad inmediata a la inyección. Las auditorías externas muestran índices de éxito de jailbreak del 18 % en Qwen 2.5-VL, un recordatorio de que el tamaño del modelo por sí solo no inmuniza contra instrucciones adversas.
- Ruido OCR no latino. Cuando se ajusta para tareas de visión y lenguaje, la cadena de procesamiento de extremo a extremo del modelo a veces confunde los glifos chinos tradicionales con los simplificados, lo que requiere capas de corrección específicas del dominio.
- Acantilado de memoria de GPU a 128 K. FlashAttention‑2 compensa la RAM, pero un paso hacia adelante denso de 72 B a través de 128 K tokens aún exige >120 GB de vRAM; los profesionales deben utilizar window-attend o KV-cache.
Hoja de ruta y ecosistema comunitario
El equipo de Qwen ha insinuado Qwen 3.0, con el objetivo de una red troncal de enrutamiento híbrido (Dense + MoE) y un preentrenamiento unificado de voz, visión y texto. Mientras tanto, el ecosistema ya alberga:
- Q-Agente – un agente de cadena de pensamiento de estilo ReAct que utiliza Qwen 2.5‑14B como política.
- Alpaca financiera china – un LoRA en Qwen2.5‑7B entrenado con 1 millón de presentaciones regulatorias.
- Complemento Open Interpreter – intercambia GPT‑4 por un punto de control Qwen local en VS Code.
Consulta la página “Colección Qwen2.5” de Hugging Face para obtener una lista continuamente actualizada de puntos de control, adaptadores y arneses de evaluación.
Análisis comparativo: Qwen2.5 vs. DeepSeek y ChatGPT
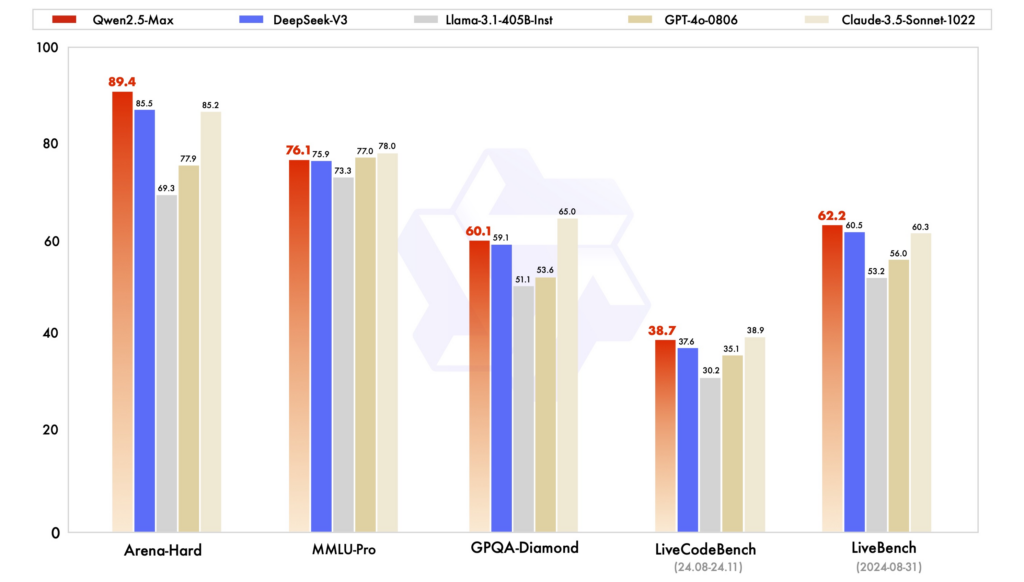
Puntos de referencia de rendimiento: En diversas evaluaciones, Qwen2.5 ha demostrado un excelente rendimiento en tareas que requieren razonamiento, codificación y comprensión multilingüe. DeepSeek-V3, con su arquitectura MoE, destaca por su eficiencia y escalabilidad, ofreciendo un alto rendimiento con recursos computacionales reducidos. ChatGPT sigue siendo un modelo robusto, especialmente en tareas lingüísticas de propósito general.
Eficiencia y costo: Los modelos de DeepSeek destacan por su entrenamiento e inferencia rentables, aprovechando las arquitecturas MoE para activar únicamente los parámetros necesarios por token. Qwen2.5, si bien es denso, ofrece variantes especializadas para optimizar el rendimiento en tareas específicas. El entrenamiento de ChatGPT requirió considerables recursos computacionales, lo que se reflejó en sus costos operativos.
Accesibilidad y disponibilidad de código abierto: Qwen2.5 y DeepSeek han adoptado los principios de código abierto en distintos grados, con modelos disponibles en plataformas como GitHub y Hugging Face. El reciente lanzamiento de una interfaz web en Qwen2.5 mejora su accesibilidad. ChatGPT, si bien no es de código abierto, es ampliamente accesible a través de la plataforma y las integraciones de OpenAI.
Conclusión
Qwen 2.5 se sitúa en un punto ideal entre servicios premium de peso cerrado y modelos de aficionados completamente abiertosSu combinación de licencias permisivas, solidez multilingüe, competencia en contextos amplios y una amplia gama de escalas de parámetros lo convierten en una base convincente tanto para la investigación como para la producción.
A medida que el panorama de LLM de código abierto avanza rápidamente, el proyecto Qwen demuestra que La transparencia y el rendimiento pueden coexistirTanto para desarrolladores, científicos de datos como para legisladores, dominar Qwen 2.5 hoy es una inversión en un futuro de IA más pluralista y favorable a la innovación.