
Qwen3-Max-Preview es el último modelo insignia de vista previa de Alibaba en la familia Qwen3: un modelo de tipo Mezcla de Expertos (MoE) con más de un billón de parámetros y una ventana de contexto de tokens ultralarga de 262k, disponible en versión preliminar para uso empresarial/en la nube. Está dirigido a *razonamiento profundo, comprensión de documentos extensos, codificación y flujos de trabajo agentes.
Información básica y características del titular
- Nombre / Etiqueta:
qwen3-max-preview(Instruir). - Escala: Más de un billón de parámetros (buque insignia de un billón de parámetros). Este es el hito clave de marketing y estadísticas para el lanzamiento.
- Ventana de contexto: Tokens 262,144 (admite entradas muy largas y transcripciones de múltiples archivos).
- Modo (s): Variante “Instruct” optimizada para instrucciones con soporte para pensando (cadena deliberada de pensamiento) y no pensar Modos rápidos en la familia Qwen3.
- Disponibilidad: Acceso a vista previa mediante Chat de Qwen, Estudio de modelos de Alibaba Cloud (Puntos finales compatibles con OpenAI o DashScope) y proveedores de enrutamiento como CometAPI.
Detalles técnicos (arquitectura y modos)
- arquitectura: Qwen3-Max sigue el linaje de diseño de Qwen3 que utiliza una combinación de densa + Mezcla de expertos (MoE) componentes en variantes más grandes, además de opciones de ingeniería para optimizar la eficiencia de la inferencia para recuentos de parámetros muy grandes.
- Modo de pensamiento vs modo de no pensamiento: La serie Qwen3 introdujo una modo de pensamiento (para resultados de estilo de cadena de pensamiento de varios pasos) y modo no pensante Para obtener respuestas más rápidas y concisas, la plataforma expone parámetros para alternar estos comportamientos.
- Características de rendimiento y almacenamiento en caché de contexto: Listas de Model Studio caché de contexto Soporte para solicitudes grandes para reducir costos de entrada repetida y mejorar el rendimiento en contextos repetidos.
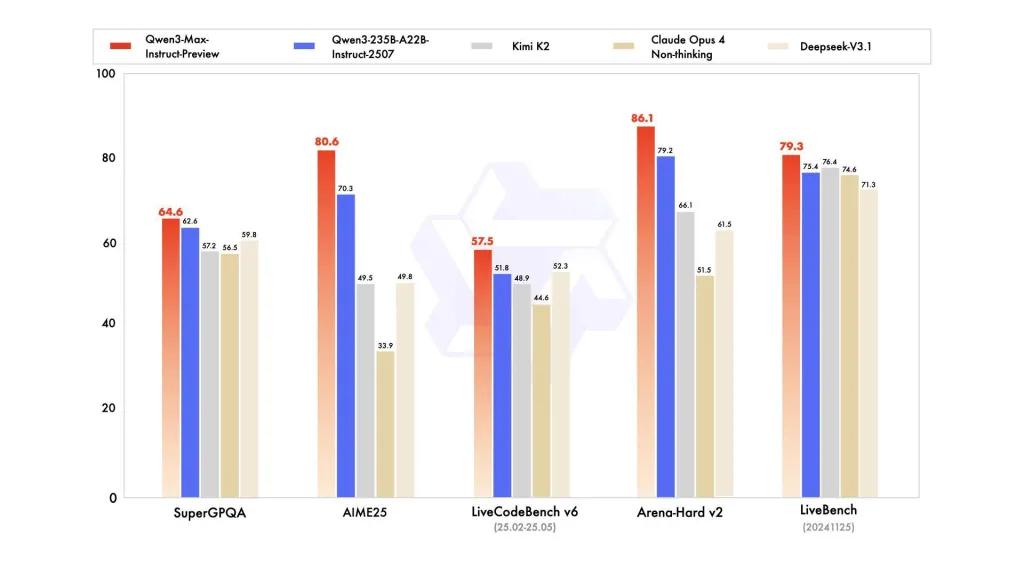
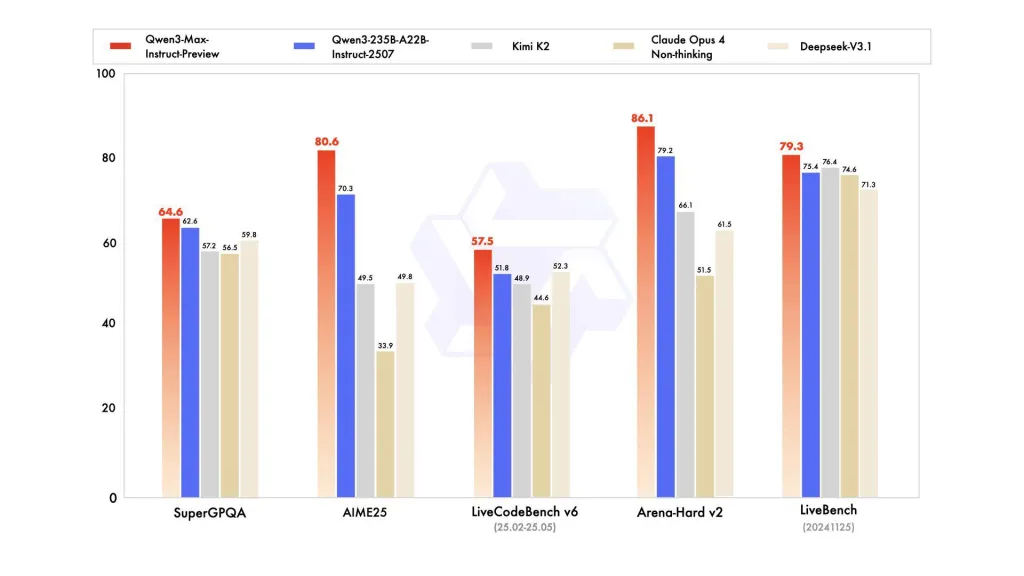
Rendimiento de referencia
Los informes hacen referencia a SuperGPQA, variantes de LiveCodeBench, AIME25 y otras suites de concurso/referencia donde Qwen3-Max parece competitivo o líder.
Limitaciones y riesgos (notas prácticas y de seguridad)
- Opacidad para receta de entrenamiento completa/pesos: Como vista previa, la publicación completa de entrenamiento, datos y pesos, así como los materiales de reproducibilidad, podrían ser limitados en comparación con versiones anteriores de Qwen3 de peso abierto. Algunos modelos de la familia Qwen3 se lanzaron de peso abierto, pero Qwen3-Max se entrega como una vista previa controlada para acceso en la nube. reduce la reproducibilidad para investigadores independientes.
- Alucinaciones y factualidad: Los informes de los proveedores afirman una reducción de las alucinaciones, pero en la práctica aún se encontrarán errores factuales y afirmaciones excesivamente confiadas; se aplican las advertencias estándar de LLM. Es necesaria una evaluación independiente antes de una implementación de alto riesgo.
- Costo a escala: Con una enorme ventana de contexto y gran capacidad, costos simbólicos Puede ser considerable para solicitudes muy largas o para un alto rendimiento de producción. Utilice el almacenamiento en caché, la fragmentación y los controles de presupuesto.
- Consideraciones regulatorias y de soberanía de datos: Los usuarios empresariales deben consultar las regiones de Alibaba Cloud, la residencia de datos y las implicaciones de cumplimiento normativo antes de procesar información confidencial. (La documentación de Model Studio incluye puntos de conexión y notas específicos de cada región).
Casos de uso
- Comprensión/resumen de documentos a escala: resúmenes legales, especificaciones técnicas y bases de conocimiento de múltiples archivos (beneficio: Ficha de 262K ventana).
- Razonamiento de código de contexto largo y asistencia de código a escala de repositorio: comprensión de código de múltiples archivos, grandes revisiones de relaciones públicas, sugerencias de refactorización a nivel de repositorio.
- Tareas de razonamiento complejo y de cadena de pensamiento: competiciones de matemáticas, planificación de varios pasos, flujos de trabajo agentes donde los rastros de “pensamiento” ayudan a la trazabilidad.
- Preguntas y respuestas empresariales multilingües y extracción de datos estructurados: Soporte para grandes corpus multilingües y capacidades de salida estructurada (JSON/tablas).
Cómo llamar a la API Qqwen3-max-preview desde CometAPI
qwen3-max-preview Precios de API en CometAPI: 20 % de descuento sobre el precio oficial.
| Tokens de entrada | $0.24 |
| Fichas de salida | $2.42 |
Pasos requeridos
- Inicia sesión en cometapi.comSi aún no eres nuestro usuario, por favor regístrate primero.
- Obtenga la clave API de credenciales de acceso de la interfaz. Haga clic en "Agregar token" en el token API del centro personal, obtenga la clave del token: sk-xxxxx y envíe.
- Obtenga la URL de este sitio: https://api.cometapi.com/
Método de uso
- Seleccione el punto final "qwen3-max-preview" para enviar la solicitud de API y configure el cuerpo de la solicitud. El método y el cuerpo de la solicitud se obtienen de la documentación de la API de nuestro sitio web. Nuestro sitio web también ofrece la prueba de Apifox para su comodidad.
- Reemplazar con su clave CometAPI real de su cuenta.
- Inserte su pregunta o solicitud en el campo de contenido: esto es lo que responderá el modelo.
- . Procesa la respuesta de la API para obtener la respuesta generada.
Llamada API
CometAPI proporciona una API REST totalmente compatible para una migración fluida. Detalles clave para Documento API:
- Parámetros centrales:
prompt,max_tokens_to_sample,temperature,stop_sequences - Punto final:
https://api.cometapi.com/v1/chat/completions - Parámetro del modelo: qwen3-max-vista previa
- Autenticación:
Bearer YOUR_CometAPI_API_KEY - Tipo de contenido:
application/json.
Reemplace
CometAPI_API_KEYcon su llave; tenga en cuenta la URL base.
Python (solicitudes): compatible con OpenAI
import os, requests
API_KEY = os.getenv("CometAPI_API_KEY")
url = "https://api.cometapi.com/v1/chat/completions"
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
payload = {
"model": "qwen3-max-preview",
"messages": [
{"role":"system","content":"You are a concise assistant."},
{"role":"user","content":"Explain the pros and cons of using an MoE model for summarization."}
],
"max_tokens": 512,
"temperature": 0.1,
"enable_thinking": True
}
resp = requests.post(url, headers=headers, json=payload)
print(resp.status_code, resp.json())
Consejo: use max_input_tokens, max_output_tokensy Model Studio caché de contexto Características al enviar contextos muy grandes para controlar el costo y el rendimiento.
Vea también Codificador Qwen3