

Los días 19 y 20 de noviembre de 2025, OpenAI lanzó dos actualizaciones relacionadas pero distintas: GPT-5.1-Codex-Max, un nuevo modelo de codificación agentiva para Codex que enfatiza la codificación de largo plazo, la eficiencia de tokens y la “compactación” para mantener sesiones multiventana; y GPT-5.1 Pro, un modelo ChatGPT de nivel Pro actualizado y optimizado para brindar respuestas más claras y eficaces en trabajos complejos y profesionales.
¿Qué es GPT-5.1-Codex-Max y qué problema intenta resolver?
GPT-5.1-Codex-Max es un modelo Codex especializado de OpenAI optimizado para flujos de trabajo de codificación que requieren razonamiento y ejecución sostenidos a largo plazoMientras que los modelos ordinarios pueden verse afectados por contextos extremadamente largos —por ejemplo, refactorizaciones de varios archivos, bucles de agentes complejos o tareas persistentes de CI/CD— Codex-Max está diseñado para Compactar y gestionar automáticamente el estado de la sesión en múltiples ventanas de contextoEsto le permite seguir funcionando de forma coherente a medida que un único proyecto abarca miles (o más) de tokens. OpenAI posiciona Codex-Max como el siguiente paso para lograr que los agentes con capacidad de codificación sean realmente útiles para trabajos de ingeniería a largo plazo.
¿Qué es GPT-5.1-Codex-Max y qué problema intenta resolver?
GPT-5.1-Codex-Max es un modelo Codex especializado de OpenAI optimizado para flujos de trabajo de codificación que requieren razonamiento y ejecución sostenidos a largo plazoMientras que los modelos ordinarios pueden verse afectados por contextos extremadamente largos —por ejemplo, refactorizaciones de varios archivos, bucles de agentes complejos o tareas persistentes de CI/CD— Codex-Max está diseñado para Compactar y gestionar automáticamente el estado de la sesión en múltiples ventanas de contexto, lo que le permite seguir funcionando de forma coherente como un único proyecto que abarca miles (o más) de tokens.
OpenAI lo describe como “más rápido, más inteligente y más eficiente en cuanto a tokens en cada etapa del ciclo de desarrollo”, y está explícitamente destinado a reemplazar a GPT-5.1-Codex como el modelo predeterminado en las superficies Codex.
Resumen de funciones
- Compactación para continuidad multiventana: Recorta y conserva el contexto crítico para funcionar de forma coherente a lo largo de millones de tokens y horas. 0
- Mejora de la eficiencia de los tokens en comparación con GPT-5.1-Codex: Hasta un 30% menos de tokens de pensamiento para un esfuerzo de razonamiento similar en algunas pruebas de referencia de código.
- Durabilidad agentiva de largo plazo: Internamente se ha observado que mantiene bucles de agentes de varias horas/varios días (OpenAI documentó ejecuciones internas de >24 horas).
- Integraciones de plataforma: Disponible hoy mismo en Codex CLI, extensiones de IDE, la nube y herramientas de revisión de código; acceso a la API próximamente.
- Compatibilidad con el entorno Windows: OpenAI destaca específicamente que Windows es compatible por primera vez en los flujos de trabajo de Codex, ampliando así el alcance de los desarrolladores en el mundo real.
¿Cómo se compara con productos de la competencia (por ejemplo, GitHub Copilot, otras IA de programación)?
GPT-5.1-Codex-Max se presenta como un colaborador más autónomo y con una visión a largo plazo, en comparación con las herramientas de autocompletado por solicitud. Si bien Copilot y asistentes similares destacan en la finalización de tareas a corto plazo dentro del editor, las fortalezas de Codex-Max radican en la orquestación de tareas de varios pasos, el mantenimiento de un estado coherente entre sesiones y la gestión de flujos de trabajo que requieren planificación, pruebas e iteración. Dicho esto, el mejor enfoque para la mayoría de los equipos será híbrido: usar Codex-Max para la automatización compleja y las tareas sostenidas de los agentes, y usar asistentes más ligeros para la finalización de tareas a nivel de línea.
¿Cómo funciona GPT-5.1-Codex-Max?
¿Qué es la “compactación” y cómo permite realizar trabajos de larga duración?
Un avance técnico fundamental es compactación—un mecanismo interno que elimina el historial de sesiones al tiempo que conserva los elementos de contexto más relevantes para que el modelo pueda seguir funcionando de forma coherente. una variedad Ventanas de contexto. En la práctica, esto significa que las sesiones de Codex que se acercan a su límite de contexto se compactarán (los tokens más antiguos o de menor valor se resumirán y conservarán) para que el agente tenga una ventana nueva y pueda seguir iterando repetidamente hasta que se complete la tarea. OpenAI informa sobre ejecuciones internas en las que el modelo trabajó en tareas de forma continua durante más de 24 horas.
Razonamiento adaptativo y eficiencia de tokens
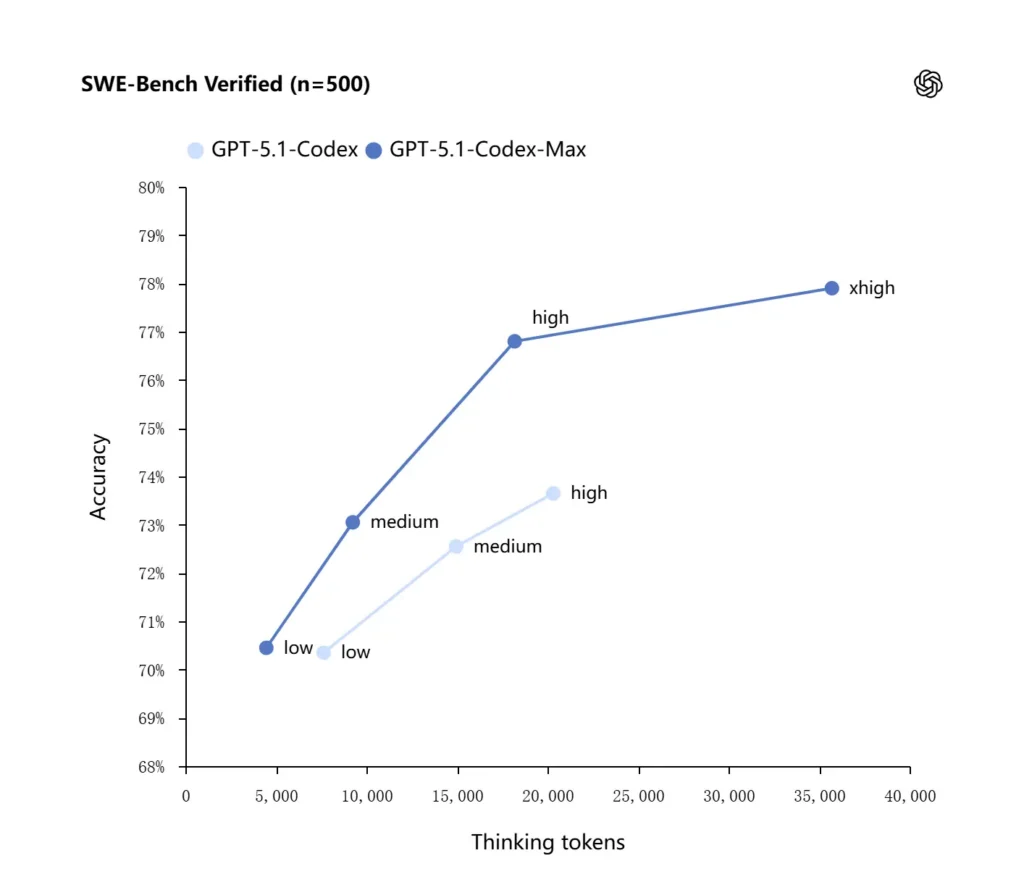
GPT-5.1-Codex-Max aplica estrategias de razonamiento mejoradas que lo hacen más eficiente en el uso de tokens: en las pruebas de rendimiento internas reportadas por OpenAI, el modelo Max logra un rendimiento similar o superior al de GPT-5.1-Codex utilizando significativamente menos tokens de "pensamiento" (OpenAI cita aproximadamente...). 30% menos Se verificó el rendimiento de los tokens de razonamiento en SWE-bench al ejecutarse con el mismo esfuerzo de razonamiento. El modelo también introduce un modo de esfuerzo de razonamiento "Extra Alto (xhigh)" para tareas que no son sensibles a la latencia, lo que le permite emplear más razonamiento interno para obtener resultados de mayor calidad.
Integraciones de sistemas y herramientas de agentes
Codex-Max se está distribuyendo dentro de los flujos de trabajo de Codex (CLI, extensiones de IDE, nube y plataformas de revisión de código) para que pueda interactuar con las herramientas de desarrollo reales. Las primeras integraciones incluyen la CLI de Codex y los agentes de IDE (VS Code, JetBrains, etc.), y se prevé que el acceso a la API se habilite posteriormente. El objetivo de diseño no es solo una síntesis de código más inteligente, sino una IA capaz de ejecutar flujos de trabajo de varios pasos: abrir archivos, ejecutar pruebas, corregir errores, refactorizar y volver a ejecutar.
¿Cómo se comporta GPT-5.1-Codex-Max en pruebas de referencia y en trabajos reales?
Razonamiento sostenido y tareas a largo plazo
Las evaluaciones señalan mejoras cuantificables en el razonamiento sostenido y en las tareas a largo plazo:
- Evaluaciones internas de OpenAIEn experimentos internos, Codex-Max pudo trabajar en tareas durante más de 24 horas, y su integración con las herramientas de desarrollo incrementó las métricas internas de productividad de ingeniería (por ejemplo, el uso y el rendimiento de las solicitudes de extracción). Estas afirmaciones internas de OpenAI indican mejoras en la productividad real a nivel de tareas.
- **Evaluaciones independientes (METR)**El informe independiente de METR midió el horizonte temporal observado del 50% (una estadística que representa el tiempo medio que el modelo puede mantener de forma coherente una tarea larga) para GPT-5.1-Codex-Max en aproximadamente 2 horas y 40 minutos (con un amplio intervalo de confianza), superior a las 2 horas y 17 minutos del GPT-5 en mediciones comparables, lo que representa una mejora significativa en la coherencia sostenida. La metodología y el intervalo de confianza de METR enfatizan la variabilidad, pero el resultado respalda la idea de que Codex-Max mejora el rendimiento práctico a largo plazo.
Puntos de referencia de código
OpenAI informa de mejores resultados en evaluaciones de codificación de vanguardia, especialmente en SWE-bench Verified, donde GPT-5.1-Codex-Max supera a GPT-5.1-Codex con una mayor eficiencia de tokens. La compañía destaca que, con el mismo esfuerzo de razonamiento "medio", el modelo Max produce mejores resultados utilizando aproximadamente un 30 % menos de tokens de razonamiento. Para los usuarios que permiten un razonamiento interno más prolongado, el modo xhigh puede mejorar aún más las respuestas, a costa de una mayor latencia.
| Códice GPT-5.1 (alto) | GPT-5.1-Codex-Max (xhigh) | |
| SWE-bench verificado (n=500) | 73.7% | 77.9% |
| SWE-Lancer IC SWE | 66.3% | 79.9% |
| Terminal-Banco 2.0 | 52.8% | 58.1% |
¿Cómo se compara GPT-5.1-Codex-Max con GPT-5.1-Codex?
diferencias de rendimiento y propósito
- Alcance: GPT-5.1-Codex era una variante de codificación de alto rendimiento de la familia GPT-5.1; Codex-Max es explícitamente un sucesor con capacidad de agencia y de largo plazo, destinado a ser la opción predeterminada recomendada para entornos Codex y similares a Codex.
- Eficiencia del token: Codex-Max muestra importantes mejoras en la eficiencia de los tokens (la afirmación de OpenAI de que se utilizan aproximadamente un 30 % menos de tokens de pensamiento) en SWE-bench y en el uso interno.
- Gestión del contexto: Codex-Max introduce la compactación y el manejo nativo de múltiples ventanas para soportar tareas que exceden una sola ventana de contexto; Codex no proporcionaba esta capacidad de forma nativa a la misma escala.
- Preparación de las herramientas: Codex-Max se distribuye como el modelo Codex predeterminado en la CLI, el IDE y las superficies de revisión de código, lo que indica una migración para los flujos de trabajo de los desarrolladores de producción.
¿Cuándo usar cada modelo?
- Utilice el códec GPT-5.1. para asistencia interactiva en la codificación, ediciones rápidas, pequeñas refactorizaciones y casos de uso de baja latencia donde todo el contexto relevante cabe fácilmente en una sola ventana.
- Utilice GPT-5.1-Codex-Max para refactorizaciones de varios archivos, tareas automatizadas de agentes que requieren muchos ciclos de iteración, flujos de trabajo tipo CI/CD, o cuando se necesita que el modelo mantenga una perspectiva a nivel de proyecto a través de muchas interacciones.
¿Patrones prácticos de indicaciones y ejemplos para obtener los mejores resultados?
Patrones de indicaciones que funcionan bien
- Sea explícito sobre los objetivos y las limitaciones: “Refactoriza X, conserva la API pública, mantén los nombres de las funciones y asegúrate de que las pruebas A, B y C se superen.”
- Proporcionar un contexto mínimo reproducible: En lugar de volcar repositorios completos, incluya un enlace a la prueba que falló, los seguimientos de pila y fragmentos de archivos relevantes. Codex-Max compactará el historial según sea necesario.
- Utilice instrucciones paso a paso para tareas complejas: Divide los trabajos grandes en una secuencia de subtareas y deja que Codex-Max las recorra (por ejemplo, “1) ejecutar pruebas 2) corregir las 3 pruebas que fallan más 3) ejecutar el linter 4) resumir los cambios”).
- Solicitar explicaciones y diferencias: Solicitar tanto el parche como una breve justificación para que los revisores humanos puedan evaluar rápidamente la seguridad y la intención.
Ejemplos de plantillas de solicitud
Tarea de refactorización
“Refactorizar el
payment/módulo para extraer el procesamiento de pagos enpayment/processor.pyMantén estables las firmas de las funciones públicas para las funciones que ya las llaman. Crea pruebas unitarias paraprocess_payment()que cubran el éxito, el fallo de red y la tarjeta no válida. Ejecute el conjunto de pruebas y devuelva las pruebas fallidas y un parche en formato diff unificado.
Corrección de errores + prueba
“Una prueba
tests/test_user_auth.py::test_token_refreshFalla con el siguiente error: . Investigue la causa raíz, proponga una solución con cambios mínimos y agregue una prueba unitaria para evitar regresiones. Aplique el parche y ejecute las pruebas.
Generación iterativa de relaciones públicas
Implementar la función X: agregar un punto de conexión
POST /api/exportque transmite los resultados de exportación y está autenticado. Crea el punto de conexión, agrega la documentación, crea las pruebas y abre una solicitud de extracción con un resumen y una lista de verificación de los elementos manuales.
Para la mayoría de estos, comience con mediano esfuerzo; cambiar a extra alto cuando necesitas que el modelo realice un razonamiento profundo en muchos archivos y múltiples iteraciones de prueba.
¿Cómo se accede a GPT-5.1-Codex-Max?
Dónde está disponible hoy
OpenAI ha integrado GPT-5.1-Codex-Max en Herramientas del Codex Actualmente, la CLI de Codex, las extensiones del IDE, la nube y los flujos de revisión de código utilizan Codex-Max de forma predeterminada (se puede optar por Codex-Mini). La disponibilidad de la API está en preparación; GitHub Copilot cuenta con versiones preliminares públicas que incluyen GPT-5.1 y modelos de la serie Codex.
Los desarrolladores pueden acceder a GPT-5.1-Codex-Max y API del códice GPT-5.1 a través de CometAPI. Para empezar, explore las capacidades del modelo deCometAPI en el cuadro Playground Consulte la guía de la API para obtener instrucciones detalladas. Antes de acceder, asegúrese de haber iniciado sesión en CometAPI y de haber obtenido la clave de API. ComoeAPI Ofrecemos un precio muy inferior al oficial para ayudarte a integrarte.
¿Listo para ir?→ Regístrate en CometAPI hoy !
Si quieres conocer más consejos, guías y novedades sobre IA síguenos en VK, X y Discord!
Guía de inicio rápido (paso a paso práctico)
- Asegúrese de tener acceso: Confirme que su plan de producto ChatGPT/Codex (Plus, Pro, Business, Edu, Enterprise) o su plan de API para desarrolladores admite los modelos de la familia GPT-5.1/Codex.
- Instala la extensión Codex CLI o IDE: Si deseas ejecutar tareas de código localmente, instala la CLI de Codex o la extensión del IDE de Codex para VS Code, JetBrains o Xcode, según corresponda. En las configuraciones compatibles, la herramienta utilizará por defecto GPT-5.1-Codex-Max.
- Elija el esfuerzo de razonamiento: Empezar con mediano El esfuerzo es suficiente para la mayoría de las tareas. Para depuración profunda, refactorizaciones complejas o cuando se desea que el modelo procese más información y no importa la latencia de respuesta, cambie a high or extra alto modos. Para pequeñas correcciones rápidas, low es razonable.
- Proporcionar contexto del repositorio: Proporcione al modelo un punto de partida claro: una URL de repositorio o un conjunto de archivos y una breve instrucción (p. ej., «refactorice el módulo de pago para usar E/S asíncrona y agregue pruebas unitarias, manteniendo los contratos a nivel de función»). Codex-Max compactará el historial a medida que se acerque a los límites del contexto y continuará con la tarea.
- Iterar con pruebas: Tras generar las correcciones, el modelo ejecuta las pruebas y reporta los fallos como parte de la sesión en curso. La compactación y la continuidad en múltiples ventanas permiten a Codex-Max conservar el contexto importante de las pruebas fallidas e iterar.
Conclusión:
GPT-5.1-Codex-Max representa un avance significativo hacia asistentes de codificación con capacidad de análisis, capaces de gestionar tareas de ingeniería complejas y prolongadas con mayor eficiencia y razonamiento. Sus avances técnicos (compactación, modos de razonamiento, entrenamiento en entorno Windows) lo hacen idóneo para las organizaciones de ingeniería modernas, siempre que los equipos lo combinen con controles operativos rigurosos, políticas claras de intervención humana y una monitorización robusta. Para los equipos que lo adopten con cautela, Codex-Max tiene el potencial de transformar la forma en que se diseña, prueba y mantiene el software, convirtiendo las tareas repetitivas de ingeniería en una colaboración de mayor valor entre humanos y modelos.