

El 17 de junio de 2025, MiniMax, líder en IA con sede en Shanghái (también conocido como Xiyu Technology), lanzó oficialmente MiniMax-M1 (en adelante, "M1"), el primer modelo de razonamiento de atención híbrida, de peso abierto y a gran escala del mundo. Al combinar una arquitectura de Mezcla de Expertos (MoE) con un innovador mecanismo de Atención Relámpago, M1 logra un rendimiento líder en la industria en tareas orientadas a la productividad, rivalizando con los mejores sistemas de código cerrado, a la vez que mantiene una rentabilidad inigualable. En este artículo detallado, exploramos qué es M1, cómo funciona, sus características distintivas y ofrecemos orientación práctica para acceder y usar el modelo.
¿Qué es MiniMax-M1?
MiniMax-M1 representa la culminación de la investigación de MiniMaxAI sobre mecanismos de atención escalables y eficientes. Basándose en la base de MiniMax-Text-01, la iteración M1 integra la atención ultrarrápida con un marco MoE para lograr una eficiencia sin precedentes tanto durante el entrenamiento como durante la inferencia. Esta combinación permite que el modelo mantenga un alto rendimiento incluso al procesar secuencias extremadamente largas, un requisito clave para tareas que involucran bases de código extensas, documentos legales o literatura científica.
Arquitectura central y parametrización
En esencia, MiniMax-M1 utiliza un sistema híbrido MoE que enruta dinámicamente tokens a través de un subconjunto de subredes expertas. Si bien el modelo comprende 456 mil millones de parámetros en total, solo 45.9 mil millones se activan para cada token, lo que optimiza el uso de recursos. Este diseño se inspira en implementaciones anteriores de MoE, pero perfecciona la lógica de enrutamiento para minimizar la sobrecarga de comunicación entre GPU durante la inferencia distribuida.
Atención relámpago y soporte de contexto largo
Una característica distintiva de MiniMax-M1 es su mecanismo de atención ultrarrápida, que reduce drásticamente la carga computacional de la autoatención en secuencias largas. Al aproximar las matrices de atención mediante una combinación de núcleos locales y globales, el modelo reduce los FLOP hasta en un 75 % en comparación con los transformadores tradicionales al procesar secuencias de 100 XNUMX tokens. Esta eficiencia no solo acelera la inferencia, sino que también permite gestionar ventanas de contexto de hasta un millón de tokens sin requisitos de hardware excesivos.
¿Cómo logra MiniMax-M1 eficiencia computacional?
Las mejoras en la eficiencia de MiniMax-M1 se deben a dos innovaciones principales: su arquitectura híbrida de mezcla de expertos y el novedoso algoritmo de aprendizaje por refuerzo CISPO utilizado durante el entrenamiento. En conjunto, estos elementos reducen tanto el tiempo de entrenamiento como el coste de inferencia, lo que permite una rápida experimentación e implementación.
Enrutamiento híbrido de mezcla de expertos
El componente MoE emplea 32 subredes expertas, cada una especializada en diferentes aspectos del razonamiento o tareas específicas del dominio. Durante la inferencia, un mecanismo de control aprendido selecciona dinámicamente a los expertos más relevantes para cada token, activando únicamente las subredes necesarias para procesar la entrada. Esta activación selectiva reduce drásticamente los cálculos redundantes y la demanda de ancho de banda de memoria, lo que otorga a MiniMax-M1 una ventaja sustancial en cuanto a rentabilidad frente a los modelos de transformadores monolíticos.
CISPO: Un nuevo algoritmo de aprendizaje por refuerzo
Para optimizar la eficiencia del entrenamiento, MiniMaxAI desarrolló CISPO (Muestreo de Importancia Recortado con Anulaciones Parciales), un algoritmo de RL que reemplaza las actualizaciones de peso a nivel de token con recorte basado en el muestreo de importancia. CISPO mitiga los problemas de explosión de peso comunes en configuraciones de RL a gran escala, acelera la convergencia y garantiza una mejora estable de las políticas en diversos benchmarks. Como resultado, el entrenamiento completo de RL de MiniMax-M1 en 512 GPU H800 se completa en tan solo tres semanas, con un costo aproximado de $534,700, una fracción del costo reportado para ejecuciones de entrenamiento comparables con GPT-4.
¿Cuáles son los puntos de referencia de rendimiento del MiniMax-M1?
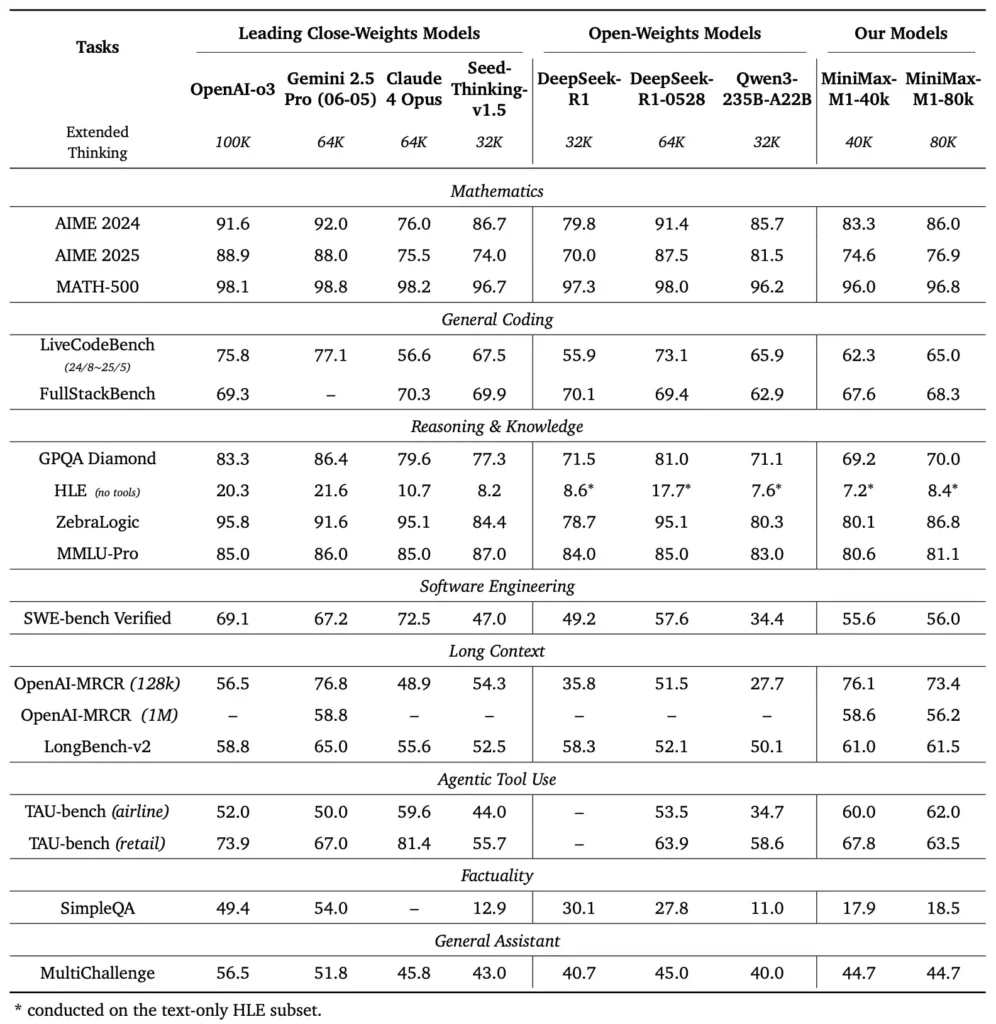
MiniMax-M1 se destaca en una variedad de puntos de referencia estándar y específicos del dominio, lo que demuestra su destreza en el manejo del razonamiento de contexto largo, la resolución de problemas matemáticos y la generación de código.
Tareas de razonamiento de contexto largo
En pruebas exhaustivas de comprensión de documentos, MiniMax-M1 procesa ventanas de contexto de hasta 1,000,000 1 100 de tokens, superando a DeepSeek-RXNUMX por ocho en longitud máxima de contexto y reduciendo a la mitad los requisitos de cómputo para secuencias de XNUMX XNUMX tokens. En pruebas de referencia como la evaluación de contexto extendido de NarrativeQA, el modelo alcanza puntuaciones de comprensión de vanguardia, gracias a la capacidad de su atención ultrarrápida para capturar dependencias locales y globales de manera eficiente.
Ingeniería de software y utilización de herramientas
MiniMax-M1 se entrenó específicamente en entornos de ingeniería de software con espacio aislado mediante aprendizaje automático a gran escala, lo que le permitió generar y depurar código con una precisión excepcional. En pruebas de código como HumanEval y MBPP, el modelo alcanza tasas de aprobación comparables o superiores a las de Qwen3-235B y DeepSeek-R1, especialmente en bases de código con múltiples archivos y tareas que requieren referencias cruzadas de segmentos de código extensos. Además, las primeras demostraciones de MiniMaxAI demuestran la capacidad del modelo para integrarse con herramientas de desarrollo, desde la generación de pipelines de CI/CD hasta flujos de trabajo de documentación automática.
¿Cómo pueden los desarrolladores acceder a MiniMax-M1?
Para fomentar su adopción generalizada, MiniMaxAI ha puesto MiniMax-M1 a disposición del público como modelo de peso abierto. Los desarrolladores pueden acceder a puntos de control preentrenados, pesos del modelo y código de inferencia a través del repositorio oficial de GitHub.
Versión de peso abierto en GitHub
MiniMaxAI publicó los archivos del modelo de MiniMax-M1 y los scripts que los acompañan bajo una licencia de código abierto permisiva en GitHub. Los usuarios interesados pueden clonar el repositorio en https://github.com/MiniMax-AI/MiniMax-M1, que alberga puntos de control para las variantes de presupuesto de tokens de 40 80 y XNUMX XNUMX, así como ejemplos de integración para frameworks de aprendizaje automático comunes como PyTorch y TensorFlow.
Puntos finales de API e integración en la nube
Además de la implementación local, MiniMaxAI se ha asociado con importantes proveedores de nube para ofrecer servicios de API gestionados. Gracias a estas alianzas, los desarrolladores pueden acceder a MiniMax-M1 mediante endpoints RESTful, con SDK disponibles para Python, JavaScript y Java. Las API incluyen parámetros configurables para la longitud del contexto, umbrales de enrutamiento experto y presupuestos de tokens, lo que permite a los usuarios adaptar el rendimiento a sus casos de uso mientras monitorizan el consumo de cómputo en tiempo real.
¿Cómo integrar y utilizar MiniMax-M1 en aplicaciones reales?
Para aprovechar las capacidades de MiniMax-M1 es necesario comprender sus patrones de API, las mejores prácticas para indicaciones de contexto largo y las estrategias para la orquestación de herramientas.
Ejemplo de uso básico de API
Una llamada API típica implica el envío de una carga útil JSON que contiene el texto de entrada y las modificaciones de configuración opcionales. Por ejemplo:
POST /v1/minimax-m1/generate
{
"input": "Analyze the following 500K token legal document and summarize the key obligations:",
"max_output_tokens": 1024,
"context_window": 500000,
"expert_threshold": 0.6
}
La respuesta devuelve un JSON estructurado con texto generado, estadísticas de uso de tokens y registros de enrutamiento, lo que permite un monitoreo detallado de las activaciones de expertos.
Uso de herramientas y agente MiniMax
Además del modelo principal, MiniMaxAI ha presentado MiniMax Agent, un framework de agente beta que puede invocar herramientas externas, desde entornos de ejecución de código hasta raspadores web, de forma interna. Los desarrolladores pueden instanciar una sesión de agente que encadena el razonamiento del modelo con la invocación de herramientas, por ejemplo, para recuperar datos en tiempo real, realizar cálculos o actualizar bases de datos. Este paradigma de agente simplifica el desarrollo integral de aplicaciones, permitiendo que MiniMax-M1 funcione como orquestador en flujos de trabajo complejos.
Mejores prácticas y trampas
- Ingeniería rápida para contextos largos:Divida las entradas en segmentos coherentes, incorpore resúmenes a intervalos lógicos y utilice estrategias de “resumir y luego razonar” para mantener el enfoque del modelo.
- Compensación entre computación y rendimiento:Experimente con umbrales de expertos más bajos o presupuestos de pensamiento reducidos (por ejemplo, la variante 40K) para aplicaciones sensibles a la latencia.
- Monitoreo y gobernanza:Utilice registros de enrutamiento y estadísticas de tokens para auditar la utilización de expertos y garantizar el cumplimiento de los presupuestos de costos, especialmente en entornos de producción.
Al seguir estas pautas, los desarrolladores pueden aprovechar las fortalezas de MiniMax-M1 (manejo de amplio contexto y razonamiento eficiente) y al mismo tiempo mitigar los riesgos asociados con las implementaciones de modelos a gran escala.
¿Cómo se utiliza MiniMax-M1?
Una vez instalado, M1 se puede invocar a través de scripts de Python simples o cuadernos interactivos.
¿Cómo es un script de inferencia básico?
from minimax_m1 import MiniMaxM1Tokenizer, MiniMaxM1ForCausalLM
tokenizer = MiniMaxM1Tokenizer.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
model = MiniMaxM1ForCausalLM.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
inputs = tokenizer("Translate the following paragraph to French: ...", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs))
Esta muestra invoca la variante de presupuesto de 40k; cambiando a "MiniMax-AI/MiniMax-M1-80k" desbloquea el presupuesto de razonamiento completo de 80 k ().
¿Cómo manejar contextos ultra largos?
Para entradas que exceden los tamaños de búfer habituales, M1 admite la tokenización de streaming. Utilice stream=True bandera en el tokenizador para alimentar tokens en fragmentos y aprovechar la inferencia de reinicio del punto de control para mantener el rendimiento en secuencias de millones de tokens.
¿Cómo se puede ajustar o adaptar el M1?
Si bien los puntos de control básicos son suficientes para la mayoría de las tareas, los investigadores pueden aplicar ajustes de RL mediante el código CISPO incluido en el repositorio. Al proporcionar funciones de recompensa personalizadas, que abarcan desde la corrección del código hasta la fidelidad semántica, los profesionales pueden adaptar M1 a flujos de trabajo específicos del dominio.
Conclusión
MiniMax-M1 destaca como un modelo de IA innovador que revoluciona la comprensión y el razonamiento del lenguaje en contextos extensos. Gracias a su arquitectura híbrida MoE, su mecanismo de atención ultrarrápida y su programa de entrenamiento con respaldo CISPO, el modelo ofrece un alto rendimiento en tareas que abarcan desde el análisis legal hasta la ingeniería de software, a la vez que reduce drásticamente el gasto computacional. Gracias a su versión de peso abierto y a sus API en la nube, MiniMax-M1 es accesible para un amplio espectro de desarrolladores y organizaciones deseosos de crear aplicaciones de IA de última generación. A medida que la comunidad de IA continúa explorando el potencial de los modelos de contexto extenso, las innovaciones de MiniMax-M1 están preparadas para influir en la investigación y el desarrollo de productos futuros en toda la industria.
Primeros Pasos
CometAPI proporciona una interfaz REST unificada que integra cientos de modelos de IA, incluida la familia ChatGPT, en un punto final consistente, con gestión de claves API integrada, cuotas de uso y paneles de facturación. En lugar de tener que gestionar múltiples URL y credenciales de proveedores.
Para comenzar, explore las capacidades de los modelos en el Playground y consultar el Guía de API Para obtener instrucciones detalladas, consulte la sección "Antes de acceder, asegúrese de haber iniciado sesión en CometAPI y de haber obtenido la clave API".
La última integración de la API MiniMax-M1 pronto aparecerá en CometAPI, ¡así que permanezca atento! Mientras finalizamos la carga del modelo MiniMax-M1, explore nuestros otros modelos en Página de modelos o pruébalos en el Patio de juegos de IAEl último modelo de MiniMax en CometAPI son API de vista previa de Minimax ABAB7 y API de MiniMax Video-01 ,referirse a:
