

En un panorama dominado por la filosofía de «escalar a cualquier costo», donde modelos como Flux.2 y Hunyuan-Image-3.0 llevan los recuentos de parámetros a rangos masivos de 30B a 80B, ha surgido un nuevo contendiente para alterar el estatus quo. Z-Image, desarrollado por Tongyi Lab de Alibaba, se ha lanzado oficialmente, rompiendo expectativas con una arquitectura ligera de 6 mil millones de parámetros que rivaliza la calidad de salida de los gigantes de la industria mientras se ejecuta en hardware de consumo.
Lanzado a finales de 2025, Z-Image (y su variante ultrarrápida Z-Image-Turbo) cautivó instantáneamente a la comunidad de IA, superando las 500,000 descargas en 24 horas desde su debut. Al ofrecer imágenes fotorrealistas en solo 8 pasos de inferencia, Z-Image no es solo otro modelo; es una fuerza democratizadora en la IA generativa, que habilita la creación de alta fidelidad en laptops que se atragantarían con sus competidores.
¿Qué es Z-Image?
Z-Image es un nuevo modelo fundacional de generación de imágenes de código abierto desarrollado por el equipo de investigación Tongyi-MAI / Alibaba Tongyi Lab. Es un modelo generativo de 6 mil millones de parámetros construido sobre una arquitectura novedosa Scalable Single-Stream Diffusion Transformer (S3-DiT) que concatena tokens de texto, tokens semánticos visuales y tokens VAE en una sola secuencia de procesamiento. El objetivo de diseño es explícito: ofrecer fotorrealismo de primer nivel y obediencia a instrucciones mientras reduce drásticamente el costo de inferencia y habilita el uso práctico en hardware de consumo. El proyecto Z-Image publica código, pesos del modelo y una demo en línea bajo una licencia Apache-2.0.
Z-Image se distribuye en múltiples variantes. El lanzamiento más comentado es Z-Image-Turbo —una versión destilada de pocos pasos optimizada para despliegue— además de la no destilada Z-Image-Base (checkpoint fundacional, más adecuada para fine-tuning) y Z-Image-Edit (ajustada por instrucciones para edición de imágenes).
La ventaja «Turbo»: inferencia en 8 pasos
La variante insignia, Z-Image-Turbo, utiliza una técnica de destilación progresiva conocida como Decoupled-DMD (Distribution Matching Distillation). Esto permite comprimir el proceso de generación desde los 30-50 pasos estándar hasta apenas 8 pasos.
Resultado: tiempos de generación inferiores al segundo en GPUs empresariales (H800) y prácticamente en tiempo real en tarjetas de consumo (RTX 4090), sin el aspecto «plástico» o «deslavado» típico de otros modelos turbo/lightning.
4 características clave de Z-Image
Z-Image está repleto de funciones que atienden tanto a desarrolladores técnicos como a profesionales creativos.
1. Fotorrealismo y estética inigualables
A pesar de tener solo 6 mil millones de parámetros, Z-Image produce imágenes con una claridad sorprendente. Destaca en:
- Textura de la piel: reproduce poros, imperfecciones e iluminación natural en sujetos humanos.
- Física de materiales: renderizado preciso de vidrio, metal y texturas de tela.
- Iluminación: manejo superior de iluminación cinematográfica y volumétrica en comparación con SDXL.
2. Renderizado de texto bilingüe nativo
Uno de los puntos de dolor más significativos en la generación de imágenes por IA ha sido el renderizado de texto. Z-Image lo resuelve con soporte nativo para inglés y chino.
- Puede generar carteles, logotipos y señalizaciones complejas con ortografía y caligrafía correctas en ambos idiomas, una función a menudo ausente en modelos centrados en Occidente.
3. Z-Image-Edit: edición basada en instrucciones
Junto al modelo base, el equipo publicó Z-Image-Edit. Esta variante está afinada para tareas image-to-image, permitiendo a los usuarios modificar imágenes existentes con instrucciones en lenguaje natural (por ejemplo, "Haz que la persona sonría", "Cambia el fondo a una montaña nevada"). Mantiene alta consistencia de identidad e iluminación durante estas transformaciones.
4. Accesibilidad en hardware de consumo
- Eficiencia de VRAM: se ejecuta cómodamente con 6GB VRAM (con cuantización) hasta 16GB VRAM (precisión completa).
- Ejecución local: soporta completamente el despliegue local vía ComfyUI y
diffusers, liberando a los usuarios de dependencias en la nube.
¿Cómo funciona Z-Image?
Transformador de difusión de flujo único (S3-DiT)
Z-Image se aparta de los diseños clásicos de doble flujo (codificadores/flujo separado para texto e imagen) y en su lugar concatena tokens de texto, tokens VAE de imagen y tokens semánticos visuales en una única entrada de transformador. Este enfoque de flujo único mejora la utilización de parámetros y simplifica la alineación multimodal dentro del backbone del transformador, lo cual, según los autores, ofrece una relación eficiencia/calidad favorable para un modelo de 6B.
DMD desacoplado y DMDR (destilación + RL)
Para habilitar generación en pocos pasos (8) sin la penalización de calidad habitual, el equipo desarrolló un enfoque de destilación Decoupled-DMD. La técnica separa la ampliación CFG (orientación sin clasificador) del emparejamiento de distribuciones, permitiendo optimizar cada una de forma independiente. Luego aplican un paso de aprendizaje por refuerzo posterior al entrenamiento (DMDR) para refinar la alineación semántica y la estética. Juntos, estos producen Z-Image-Turbo con muchas menos NFEs que los modelos de difusión típicos, manteniendo un alto realismo.
Optimización del rendimiento de entrenamiento y del coste
Z-Image fue entrenado con un enfoque de optimización del ciclo de vida: pipelines de datos curados, currículo simplificado y elecciones de implementación conscientes de la eficiencia. Los autores reportan completar el flujo completo de entrenamiento en aproximadamente 314K horas de GPU H800 (≈ USD $630K) —una métrica de ingeniería explícita y reproducible que posiciona al modelo como rentable frente a alternativas muy grandes (>20B).
Resultados de referencia del modelo Z-Image
Z-Image-Turbo ocupó puestos altos en varios rankings contemporáneos, incluyendo una posición destacada de código abierto en el leaderboard de Artificial Analysis Text-to-Image y un rendimiento sólido en evaluaciones de preferencia humana de Alibaba AI Arena.
Pero la calidad en el mundo real también depende de la formulación del prompt, resolución, pipeline de upscaling y procesamiento posterior adicional.
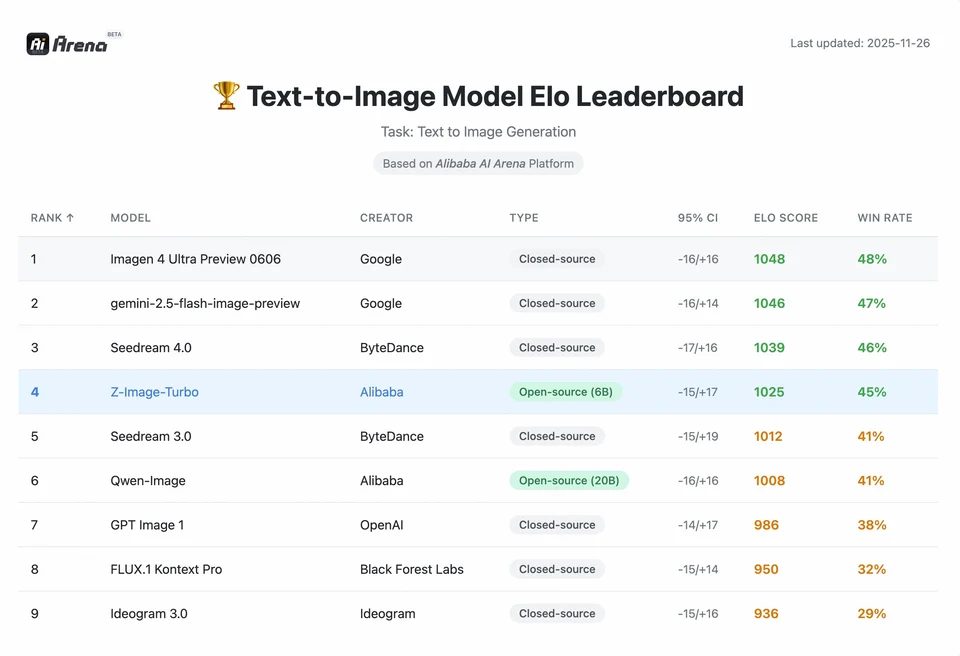
Para entender la magnitud del logro de Z-Image, debemos mirar los datos. A continuación se presenta un análisis comparativo de Z-Image frente a modelos líderes de código abierto y propietarios.
Resumen comparativo de benchmarks
| Característica / Métrica | Z-Image-Turbo | Flux.2 (Dev/Pro) | SDXL Turbo | Hunyuan-Image |
|---|---|---|---|---|
| Arquitectura | S3-DiT (flujo único) | MM-DiT (flujo dual) | U-Net | Transformador de Difusión |
| Parámetros | 6 mil millones | 12B / 32B | 2.6B / 6.6B | ~30B+ |
| Pasos de inferencia | 8 pasos | 25 - 50 pasos | 1 - 4 pasos | 30 - 50 pasos |
| VRAM requerida | ~6GB - 12GB | 24GB+ | ~8GB | 24GB+ |
| Renderizado de texto | Alto (EN + CN) | Alto (EN) | Moderado (EN) | Alto (CN + EN) |
| Velocidad de generación (4090) | ~1.5 - 3.0 segundos | ~15 - 30 segundos | ~0.5 segundos | ~20 segundos |
| Puntuación de fotorrealismo | 9.2/10 | 9.5/10 | 7.5/10 | 9.0/10 |
| Licencia | Apache 2.0 | No comercial (Dev) | OpenRAIL | Personalizada |
Análisis de datos e insights de rendimiento
- Velocidad vs. calidad: aunque SDXL Turbo es más rápido (1 paso), su calidad se degrada significativamente en prompts complejos. Z-Image-Turbo logra el «punto óptimo» en 8 pasos, igualando la calidad de Flux.2 mientras es 5x a 10x más rápido.
- Democratización del hardware: Flux.2, aunque potente, está efectivamente limitado a tarjetas de 24GB VRAM (RTX 3090/4090) para un rendimiento razonable. Z-Image permite a usuarios con tarjetas de gama media (RTX 3060/4060) generar imágenes locales de 1024x1024 de calidad profesional.
¿Cómo pueden los desarrolladores acceder y usar Z-Image?
Hay tres enfoques típicos:
- Alojado / SaaS (UI web o API): utiliza servicios como z-image.ai u otros proveedores que despliegan el modelo y exponen una interfaz web o API de pago para generación de imágenes. Esta es la ruta más rápida para experimentar sin configuración local.
- Hugging Face + pipelines de
diffusers: la libreríadiffusersde Hugging Face incluyeZImagePipelineyZImageImg2ImgPipeliney ofrece los flujos típicosfrom_pretrained(...).to("cuda"). Esta es la vía recomendada para desarrolladores Python que quieran integración directa y ejemplos reproducibles. - Inferencia nativa local desde el repositorio de GitHub: el repositorio de Tongyi-MAI incluye scripts de inferencia nativa, opciones de optimización (FlashAttention, compilación, descarga a CPU) e instrucciones para instalar
diffusersdesde fuente para la integración más reciente. Esta ruta es útil para investigadores y equipos que quieren control total o ejecutar entrenamiento/afinación personalizados.
¿Cómo luce un ejemplo mínimo en Python?
A continuación se muestra un fragmento conciso en Python usando diffusers de Hugging Face que demuestra la generación texto-a-imagen con Z-Image-Turbo.
# minimal_zimage_turbo.pyimport torchfrom diffusers import ZImagePipelinedef generate(prompt, output_path="zimage_output.png", height=1024, width=1024, steps=9, guidance_scale=0.0, seed=42): # Usar bfloat16 donde esté soportado para ganar eficiencia en GPUs modernas pipe = ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) pipe.to("cuda") generator = torch.Generator("cuda").manual_seed(seed) image = pipe( prompt=prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=guidance_scale, generator=generator, ).images[0] image.save(output_path) print(f"Guardado: {output_path}")if __name__ == "__main__": generate("Un retrato cinematográfico de un robot pintor, iluminación de estudio, ultra detallado")
Notas: los valores por defecto y los ajustes recomendados de guidance_scale difieren para los modelos Turbo; la documentación sugiere que la guía puede establecerse baja o en cero para Turbo dependiendo del comportamiento deseado.
¿Cómo ejecutar image-to-image (edición) con Z-Image?
El ZImageImg2ImgPipeline soporta edición de imágenes. Ejemplo:
from diffusers import ZImageImg2ImgPipelinefrom diffusers.utils import load_imageimport torchpipe = ZImageImg2ImgPipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16)pipe.to("cuda")init_image = load_image("sketch.jpg").resize((1024, 1024))prompt = "Convierte este boceto en un valle fluvial de fantasía con colores vibrantes"result = pipe(prompt, image=init_image, strength=0.6, num_inference_steps=9, guidance_scale=0.0, generator=torch.Generator("cuda").manual_seed(123))result.images[0].save("zimage_img2img.png")
Esto refleja los patrones de uso oficiales y es adecuado para tareas creativas de edición e inpainting.
¿Cómo abordar los prompts y la guía?
- Sé explícito con la estructura: para escenas complejas, estructura prompts que incluyan composición de la escena, objeto focal, cámara/lente, iluminación, ambiente y cualquier elemento textual. Z-Image se beneficia de prompts detallados y maneja bien pistas posicionales/narrativas.
- Ajusta
guidance_scalecuidadosamente: los modelos Turbo pueden recomendar valores de guía más bajos; es necesario experimentar. Para muchos flujos Turbo,guidance_scale=0.0–1.0con una semilla y pasos fijos produce resultados consistentes. - Usa image-to-image para ediciones controladas: cuando necesites preservar la composición pero cambiar estilo/color/objetos, parte de una imagen inicial y usa
strengthpara controlar la magnitud del cambio.
Mejores casos de uso y buenas prácticas
1. Prototipado rápido y storyboard
Caso de uso: directores de cine y diseñadores de juegos necesitan visualizar escenas al instante.
¿Por qué Z-Image? con generación inferior a 3 segundos, los creadores pueden iterar cientos de conceptos en una sola sesión, refinando iluminación y composición en tiempo real sin esperar minutos por un render.
2. Comercio electrónico y publicidad
Caso de uso: generar fondos de producto o tomas lifestyle para mercancía.
Mejor práctica: usa Z-Image-Edit.
Sube una foto de producto sin procesar y utiliza un prompt como "Coloca esta botella de perfume sobre una mesa de madera en un jardín bañado por el sol". El modelo preserva la integridad del producto mientras inventa un fondo fotorrealista.
3. Creación de contenido bilingüe
Caso de uso: campañas de marketing globales que requieren recursos tanto para mercados occidentales como asiáticos.
Mejor práctica: aprovecha la capacidad de renderizado de texto.
- Prompt: "Un letrero de neón que diga 'OPEN' y '营业中' brillando en un callejón oscuro."
- Z-Image renderizará correctamente tanto los caracteres en inglés como en chino, una hazaña que la mayoría de otros modelos no logran.
4. Entornos de pocos recursos
Caso de uso: ejecutar generación de IA en dispositivos edge o laptops de oficina estándar.
Consejo de optimización: utiliza la versión cuantizada en INT8 de Z-Image. Esto reduce el uso de VRAM por debajo de 6GB con una pérdida de calidad insignificante, haciéndolo viable para apps locales en laptops no gaming.
En resumen: ¿quién debería usar Z-Image?
Z-Image está diseñado para organizaciones y desarrolladores que quieren fotorrealismo de alta calidad con latencia y costo prácticos, y que prefieren licencias abiertas y alojamiento on-premises o personalizado. Es particularmente atractivo para equipos que necesitan iteración rápida (herramientas creativas, maquetas de producto, servicios en tiempo real) y para investigadores/miembros de la comunidad interesados en afinar un modelo de imágenes compacto pero potente.
CometAPI ofrece modelos Grok Image igualmente menos restringidos, así como modelos como Nano Banana Pro, GPT- image 1.5, Sora 2(¿Puede Sora 2 generar contenido NSFW? ¿Cómo podemos probarlo?), etc., siempre que tengas los consejos y trucos NSFW adecuados para eludir las restricciones y empezar a crear con libertad. Antes de acceder, asegúrate de haber iniciado sesión en CometAPI y obtenido la clave de API. CometAPI ofrece un precio mucho más bajo que el oficial para ayudarte a integrar.
¿Listo para empezar?→ Prueba gratuita para crear !