

En juillet 2025, Alibaba a dévoilé Qwen3-Coder, son modèle d'IA open source le plus avancé, conçu spécifiquement pour les workflows de codage complexes et les tâches de programmation agentique. Ce guide professionnel vous guidera pas à pas à travers tout ce que vous devez savoir : de la compréhension de ses fonctionnalités clés et de ses innovations clés à l'installation et à l'utilisation du logiciel associé. Code Qwen Outil CLI pour le codage automatisé de type agent. Vous découvrirez les bonnes pratiques, des conseils de dépannage et comment optimiser vos invites et l'allocation de vos ressources pour tirer le meilleur parti de Qwen3-Coder.
Qu'est-ce que Qwen3-Coder et pourquoi est-ce important ?
Qwen3-Coder d'Alibaba est un modèle Mixture-of-Experts (MoE) de 480 milliards de paramètres avec 35 milliards de paramètres actifs, conçu pour prendre en charge les tâches de codage à grand contexte, gérant nativement 256 1 jetons (et jusqu'à 23 M avec des méthodes d'extrapolation). Lancé le 2025 juillet XNUMX, il représente une avancée majeure dans le codage par IA agentique, où le modèle génère non seulement du code, mais peut également planifier, déboguer et itérer de manière autonome des défis de programmation complexes sans intervention manuelle.
En quoi Qwen3-Coder diffère-t-il de ses prédécesseurs ?
Qwen3-Coder s'appuie sur les innovations de la famille Qwen3, intégrant à la fois un « mode pensée » pour le raisonnement multi-étapes et un « mode non pensée » pour les réponses rapides, dans un framework unique et unifié qui change dynamiquement de mode en fonction de la complexité de la tâche. Contrairement à Qwen2.5-Coder, dense et limité à des contextes plus restreints, Qwen3-Coder utilise une architecture Mixture-of-Experts éparse pour offrir des performances de pointe sur des benchmarks tels que SWE-Bench Verified et les évaluations ELO de CodeForces, égalant ou surpassant des modèles comme Claude d'Anthropic et GPT-4 d'OpenAI sur des indicateurs clés de codage.
caractéristiques principales de Qwen3-Coder :
- Fenêtre de contexte massive : 256 1 jetons en natif, jusqu'à XNUMX M par extrapolation, lui permettant de traiter des bases de code entières ou une longue documentation en un seul passage.
- Capacités d'agent : Un « mode agent » dédié qui peut planifier, générer, tester et déboguer du code de manière autonome, réduisant ainsi les frais d'ingénierie manuelle.
- Haut débit et efficacité : La conception mixte d'experts active seulement 35 milliards de paramètres par inférence, équilibrant ainsi les performances et le coût de calcul.
- Open Source et extensible : Publié sous Apache 2.0, avec des API entièrement documentées et des améliorations pilotées par la communauté disponibles sur GitHub.
- Multilingue et interdomaine : Formé sur 7.5 billions de jetons (70 % de code) dans des dizaines de langages de programmation, de Python et JavaScript à Go et Rust.
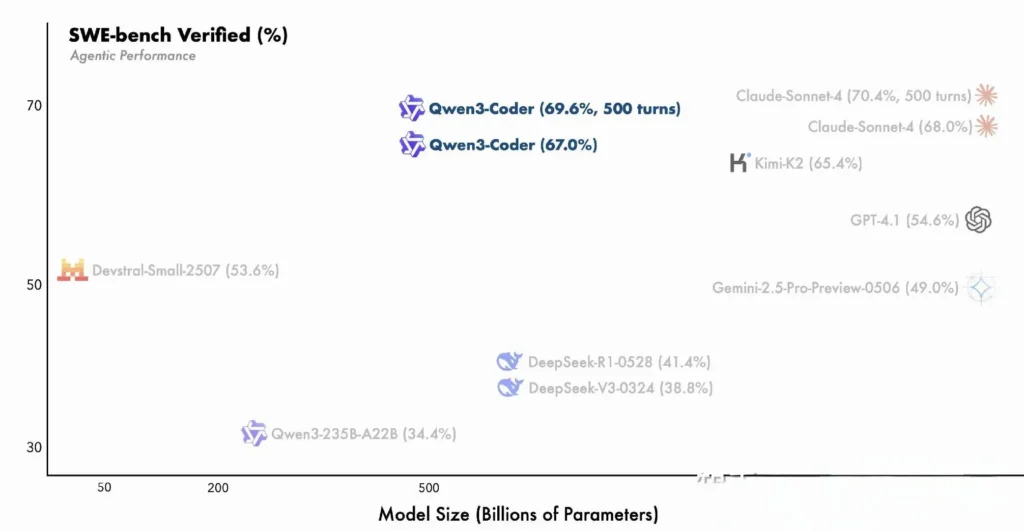
Comment les développeurs peuvent-ils démarrer avec Qwen3-Coder ?
Où puis-je télécharger et installer Qwen3-Coder ?
Vous pouvez obtenir les poids des modèles et les images Docker à partir de :
- GitHub: https://github.com/QwenLM/Qwen3-Coder
- Visage câlin : https://huggingface.co/QwenLM/Qwen3-Coder-480B-A35B-Instruct
- Portée du modèle : Dépôt officiel d'Alibaba
Clonez simplement le dépôt et récupérez le conteneur Docker pré-construit :
git clone https://github.com/QwenLM/Qwen3-Coder.git
cd Qwen3-Coder
docker pull qwenlm/qwen3-coder:latest
Chargement du modèle avec des transformateurs
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Coder-480B-A35B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
Ce code initialise le modèle et le tokenizer, distribuant automatiquement les couches sur les GPU disponibles.
Comment configurer mon environnement ?
- Matériel requis:
- GPU NVIDIA avec ≥ 48 Go de VRAM (A100 80 Go recommandé)
- 128 à 256 Go de RAM système
-
Dépendances
pip install -r requirements.txt # PyTorch, CUDA, tokenizers, etc. -
Clés API (facultatif) :
Pour l'inférence hébergée dans le cloud, définissez votreALIYUN_ACCESS_KEYetALIYUN_SECRET_KEYcomme variables d'environnement.
Comment utilisez-vous Qwen Code pour le codage agentique ?
Voici un guide étape par étape pour vous aider à démarrer avec Qwen3-Coder via le Code Qwen CLI (invoqué simplement comme qwen):
1. Pré-requis
- Node.js 20+ (vous pouvez l'installer via l'installateur officiel ou via le script ci-dessous)
- NPM, qui est fourni avec Node.js
# (Linux/macOS)
curl -qL https://www.npmjs.com/install.sh | sh
2. Installez l'interface de ligne de commande Qwen Code
npm install -g @qwen-code/qwen-code
Sinon, pour installer à partir des sources :
git clone https://github.com/QwenLM/qwen-code.git
cd qwen-code
npm install
npm install -g
3. Configurez votre environnement
Qwen Code utilise le Compatible avec OpenAI Interface API intégrée. Définissez les variables d'environnement suivantes :
export OPENAI_API_KEY="your_api_key_here"
export OPENAI_BASE_URL="https://dashscope-intl.aliyuncs.com/compatible-mode/v1"
export OPENAI_MODEL="qwen3-coder-plus"
OPENAI_MODEL peut être défini sur l'un des éléments suivants :
qwen3-coder-plus(alias Qwen3-Coder-480B-A35B-Instruct)- ou toute autre variante de Qwen3-Coder que vous avez déployée.
4. Utilisation de base
- Démarrez un REPL de codage interactif :
qwen
Cela vous plonge dans une session de codage agentique propulsée par Qwen3-Coder.
- Invite unique du Shell, pour demander un extrait de code ou compléter une fonction :
qwen code complete \
--model qwen3-coder-plus \
--prompt "Write a Python function that reverses a linked list."
- Complétion de code basée sur des fichiers, remplissez ou refactorisez automatiquement un fichier existant :
qwen code file-complete \
--model qwen3-coder-plus \
--file ./src/utils.js
- Interaction de type chat, utilisez Qwen en mode « chat », idéal pour les dialogues de codage à plusieurs tours :
qwen chat \
--model qwen3-coder-plus \
--system "You are a helpful coding assistant." \
--user "Generate a REST API endpoint in Express.js for user authentication."
Comment invoquer Qwen3-Coder via l'API CometAPI ?
CometAPI est une plateforme d'API unifiée qui regroupe plus de 500 modèles d'IA provenant de fournisseurs leaders, tels que la série GPT d'OpenAI, Gemini de Google, Claude d'Anthropic, Midjourney, Suno, etc., au sein d'une interface unique et conviviale pour les développeurs. En offrant une authentification, un formatage des requêtes et une gestion des réponses cohérents, CometAPI simplifie considérablement l'intégration des fonctionnalités d'IA dans vos applications. Que vous développiez des chatbots, des générateurs d'images, des compositeurs de musique ou des pipelines d'analyse pilotés par les données, CometAPI vous permet d'itérer plus rapidement, de maîtriser les coûts et de rester indépendant des fournisseurs, tout en exploitant les dernières avancées de l'écosystème de l'IA.
Si vous êtes un utilisateur de cometAPI, vous pouvez vous connecter à cometapi pour obtenir la clé et l'URL de base et vous connecter à cometapi pour obtenir la clé et l'URL de base, reportez-vous à API Qwen3-CoderPour commencer, explorez les capacités des modèles dans le cour de récréation et consultez le Guide de l'API pour des instructions détaillées.
Pour appeler Qwen3-Coder via CometAPI, vous utilisez les mêmes points de terminaison compatibles OpenAI que pour tout autre modèle : pointez simplement votre client vers l'URL de base de CometAPI, présentez votre clé CometAPI sous forme de jeton Bearer et spécifiez soit le qwen3-coder-plus or qwen3-coder-480b-a35b-instruct .
1. Pré-requis
- Inscrivez-vous at https://cometapi.com et ajoutez/générez un jeton API dans votre tableau de bord.
- Notez votre Clé API (commence par
sk-…). - Connaissance du protocole OpenAI Chat API (rôles + messages).
2. URL de base et authentification
URL de base:
arduinohttps://api.cometapi.com/v1
Endpoint:
bashPOST https://api.cometapi.com/v1/chat/completions
3. Exemple cURL / REST
curl https://api.cometapi.com/v1/chat/completions \
-H "Authorization: Bearer sk-xxxxxxxxxxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3-coder-plus",
"messages": [
{ "role": "system", "content": "You are a helpful coder." },
{ "role": "user", "content": "Generate a SQL query to find duplicate emails." }
],
"temperature": 0.7,
"max_tokens": 512
}'
- Réponse: JSON avec
choices.message.contentcontenant le code généré.
Comment exploitez-vous les capacités agentiques de Qwen3-Coder ?
Les fonctionnalités agentiques de Qwen3-Coder permettent l'invocation d'outils dynamiques et des flux de travail autonomes en plusieurs étapes, permettant au modèle d'appeler des fonctions externes ou des API pendant la génération de code.
Invocation d'outils et outils personnalisés
Définissez des outils personnalisés (tels que des linters, des exécuteurs de tests ou des formateurs) dans votre base de code et exposez-les au modèle via des schémas de fonctions. Par exemple :
tools = [
{"name":"run_tests","description":"Execute the test suite and return results","parameters":{}},
{"name":"format_code","description":"Apply black formatter to the code","parameters":{}}
]
response = client.chat.completions.create(
messages=,
functions=tools,
function_call="auto"
)
Qwen3-Coder peut alors générer, formater et valider du code de manière autonome en une seule session, réduisant ainsi les frais d'intégration manuelle ().
Utilisation de Qwen Code CLI
La qwen-code L'outil de ligne de commande offre un REPL interactif pour le codage agentique :
qwen-code --model qwen3-coder-480b-a35b-instruct
> generate: "Create a REST API in Node.js with JWT authentication."
> tool: install_package(express)
> tool: create_file(app.js)
> tool: run_tests
Cette CLI orchestre des flux de travail complexes avec des journaux transparents, ce qui la rend idéale pour le prototypage exploratoire ou l'intégration dans les pipelines CI/CD.
Qwen3-Coder est-il adapté aux grandes bases de code ?
Grâce à sa fenêtre contextuelle étendue, Qwen3-Coder peut ingérer des dépôts entiers (jusqu'à des centaines de milliers de lignes de code) avant de générer des correctifs ou des refactorisations. Cette fonctionnalité permet des refactorisations globales, des analyses inter-modules et des suggestions architecturales que les modèles contextuels plus restreints ne peuvent tout simplement pas égaler.
Quelles sont les meilleures pratiques pour maximiser l’utilité de Qwen3-Coder ?
L’adoption efficace de Qwen3-Coder nécessite une configuration et une intégration réfléchies dans votre pipeline CI/CD.
Comment régler les paramètres d’échantillonnage et de faisceau ?
- Température: 0.6–0.8 pour une créativité équilibrée ; inférieur (0.2–0.4) pour les tâches de refactorisation déterministe.
- Haut-p: 0.7–0.9 pour se concentrer sur les suites les plus probables tout en permettant des suggestions nouvelles occasionnelles.
- Top-k: 20–50 pour une utilisation standard ; réduire à 5–10 lorsque vous recherchez des sorties très ciblées.
- Pénalité de répétition:1.05–1.1 pour décourager le modèle de répéter des modèles standard.
Expérimenter ces paramètres en fonction de la tolérance de votre projet aux variations peut générer des gains de productivité significatifs.
Quelles sont les meilleures pratiques pour utiliser efficacement Qwen3-Coder ?
Ingénierie rapide pour la qualité du code
- Soyez précis: Spécifiez la langue, les directives de style et la complexité souhaitée dans votre invite.
- Raffinement itératif:Utilisez les capacités agentiques du modèle pour déboguer et optimiser de manière itérative le code généré.
- Réglage de la température: Abaisser la température de génération (par exemple,
temperature=0.2) pour des résultats plus déterministes dans des contextes de production.
Gestion de l'utilisation des ressources
- Variantes de modèle: Commencez avec des variantes plus petites de Qwen3-Coder pour le prototypage, puis augmentez-les selon vos besoins.
- Quantification dynamique: Expérimentez avec les points de contrôle quantifiés FP8 et GGUF pour réduire l'empreinte mémoire du GPU sans baisse significative des performances.
- Génération asynchrone: Déchargez les générations de code de longue durée vers les travailleurs en arrière-plan pour maintenir la réactivité.
Le respect de ces directives vous garantit de maximiser le retour sur investissement de l'intégration de Qwen3-Coder dans votre cycle de vie de développement logiciel.
En suivant les conseils ci-dessus (comprendre son architecture, installer et configurer à la fois le modèle et Qwen Code CLI, et tirer parti des meilleures pratiques), vous serez bien équipé pour exploiter tout le potentiel de Qwen3-Coder pour tout, des simples extraits de code aux agents de programmation entièrement autonomes.