

L'équipe Qwen d'Alibaba a publié Aperçu de Qwen3-Max (Instruct) — le plus grand modèle de l'entreprise à ce jour, avec plus de 1 XNUMX milliards de paramètres — et l'a rendu immédiatement disponible via Qwen Chat, Alibaba Cloud Model Studio (API) et des marketplaces tierces telles que CometAPI. La préversion cible le raisonnement, le codage et les workflows de documents longs en combinant une évolutivité extrême avec une très grande fenêtre contextuelle et la mise en cache du contexte pour maintenir une latence faible pendant les longues sessions.
Principaux points techniques
- Nombre massif de paramètres (plus de mille milliards) : Le passage à un modèle de plus d'un billion de paramètres vise à accroître la capacité d'apprentissage de modèles complexes (raisonnement multi-étapes, synthèse de code, compréhension approfondie de documents). Les premiers benchmarks publiés par Qwen indiquent de meilleurs résultats en matière de raisonnement, de codage et de suites de benchmarks par rapport aux précédents modèles phares de Qwen.
- Contexte ultra-long et mise en cache : La Jeton de 262 XNUMX Window permet aux équipes d'alimenter des rapports complets et longs, des bases de code multifichiers ou de longs historiques de discussion en une seule opération. La prise en charge de la mise en cache du contexte réduit les calculs répétés pour les contextes récurrents et peut diminuer la latence et le coût des sessions prolongées.
- Multilingue + prouesses de codage : La famille Qwen3 met l'accent sur le support bilingue (chinois/anglais) et multilingue étendu, ainsi que sur un codage plus solide et une gestion de sortie structurée, utiles pour les assistants de code, la génération de rapports automatisés et les analyses de texte à grande échelle.
- Conçu pour la vitesse et la qualité. Les utilisateurs de la version préliminaire décrivent une vitesse de réponse « fulgurante » et une amélioration du suivi des instructions et du raisonnement par rapport aux versions précédentes de Qwen3. Alibaba positionne ce modèle comme un produit phare à haut débit pour les scénarios de production, d'agentique et de développement.
Disponibilité et accès
Frais d'Alibaba Cloud à plusieurs niveaux, basé sur des jetons Tarifs pour Qwen3-Max-Preview (tarifs d'entrée et de sortie distincts). La facturation est calculée par million de jetons et s'applique aux jetons réellement consommés après chaque quota gratuit.
Les prix d'aperçu publiés par Alibaba (USD) sont échelonnés sur demande contribution volume de jetons (les mêmes niveaux déterminent les taux unitaires applicables) :
- 0 à 32 XNUMX jetons d’entrée : 0.861 $ / 1 M de jetons d'entrée et 3.441 $ / 1 M de jetons de sortie.
- Jetons d'entrée 32 128 à XNUMX XNUMX : 1.434 $ / 1 M de jetons d'entrée et 5.735 $ / 1 M de jetons de sortie.
- Jetons d'entrée 128 252 à XNUMX XNUMX : 2.151 $ / 1 M de jetons d'entrée et 8.602 $ / 1 M de jetons de sortie.
CometAPI offre une remise officielle de 20 % pour aider les utilisateurs à appeler l'API, les détails se réfèrent à Aperçu de Qwen3-Max:
| Jetons d'entrée | $0.24 |
| Jetons de sortie | $2.42 |
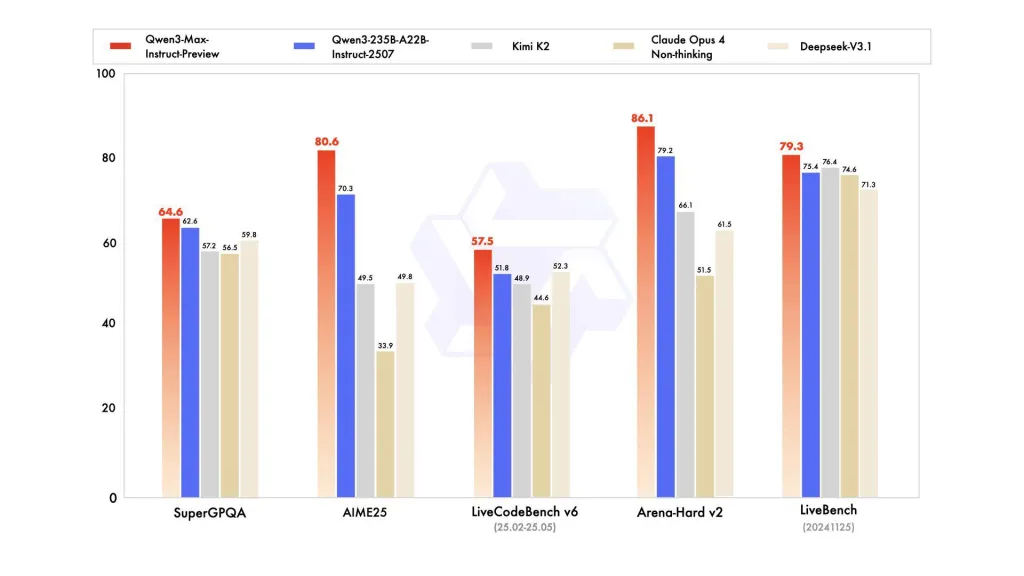
Qwen3-Max étend la famille Qwen3 (qui utilisait des conceptions hybrides telles que des variantes Mixture-of-Experts et plusieurs niveaux de paramètres actifs dans les versions précédentes). Les précédentes versions Qwen3 d'Alibaba se concentraient à la fois sur les modes « réflexion » (raisonnement étape par étape) et « instruction » ; Qwen3-Max se positionne comme la nouvelle variante d'instruction haut de gamme de cette gamme, démontrant qu'elle surpasse le produit précédent le plus performant de l'entreprise, le Qwen3-235B-A22B-2507, et montrant que le modèle de paramètres 1T est en tête dans une série de tests.
Sur SuperGPQA, AIME25, LiveCodeBench v6, Arena-Hard v2 et LiveBench (20241125), Qwen3-Max-Preview se classe systématiquement devant Claude Opus 4, Kimi K2 et Deepseek-V3.1.
Comment accéder et utiliser Qwen3-Max (guide pratique)
1) Essayez-le dans le navigateur (Qwen Chat)
Rendez nous visite Chat Qwen (interface Web/chat officielle de Qwen) et sélectionnez le Aperçu de Qwen3-Max (Instruire) le modèle s'il est affiché dans le sélecteur de modèles. C'est le moyen le plus rapide d'évaluer visuellement les tâches conversationnelles et d'instruction.
2) Accès via Cloud Alibaba (Model Studio / API Cloud)
- Connectez-vous à Alibaba Cloud → Studio de mannequins / Service de mannequinsCréez une instance d'inférence ou sélectionnez le point de terminaison du modèle hébergé pour qwen3-max-aperçu (ou la version d'aperçu étiquetée).
- Authentifiez-vous à l'aide de vos rôles Alibaba Cloud Access Key / RAM et appelez le point de terminaison d'inférence avec une requête POST contenant votre invite et tous les paramètres de génération (température, jetons max, etc.).
3) Utiliser jusqu'à hébergeurs / agrégateurs tiers
Selon la couverture, la préversion est accessible via CometAPI et d'autres agrégateurs d'API qui permettent aux développeurs d'appeler plusieurs modèles hébergés avec une seule clé API. Cela simplifie les tests entre les fournisseurs, tout en vérifiant la latence, la disponibilité régionale et les politiques de traitement des données pour chaque hôte.
Pour commencer
CometAPI est une plateforme d'API unifiée qui regroupe plus de 500 modèles d'IA provenant de fournisseurs leaders, tels que la série GPT d'OpenAI, Gemini de Google, Claude d'Anthropic, Midjourney, Suno, etc., au sein d'une interface unique et conviviale pour les développeurs. En offrant une authentification, un formatage des requêtes et une gestion des réponses cohérents, CometAPI simplifie considérablement l'intégration des fonctionnalités d'IA dans vos applications. Que vous développiez des chatbots, des générateurs d'images, des compositeurs de musique ou des pipelines d'analyse pilotés par les données, CometAPI vous permet d'itérer plus rapidement, de maîtriser les coûts et de rester indépendant des fournisseurs, tout en exploitant les dernières avancées de l'écosystème de l'IA.
Conclusion
Qwen3-Max-Preview place Alibaba parmi les entreprises qui livrent des modèles à l'échelle d'un billion de dollars à leurs clients. La combinaison d'une longueur de contexte extrême et d'une API compatible OpenAI réduit les obstacles à l'intégration pour les entreprises qui ont besoin de raisonnement sur de longs documents, d'automatisation du code ou d'orchestration d'agents. Le coût et la stabilité de la préversion sont les principaux critères d'adoption : les entreprises souhaiteront tester la mise en cache, le streaming et les appels groupés pour gérer à la fois la latence et les prix.