

La série Claude d'Anthropic est devenue une pierre angulaire dans le paysage en constante évolution des grands modèles de langage, notamment pour les entreprises et les développeurs à la recherche de capacités d'IA de pointe. Avec la sortie de Claude Opus 4.1 le 5 août 2025, Anthropic propose une mise à niveau progressive mais significative par rapport à son prédécesseur, Claude Opus 4 (sorti le 22 mai 2025). Cet article examine les principales différences entre Opus 4.1 et Opus 4.0 en termes de performances, d'architecture, de sécurité et d'applicabilité concrète, en s'appuyant sur des annonces officielles, des benchmarks indépendants et des retours d'expérience du secteur.
Claude Opus 4.1 est désormais disponible via l'API (ID de modèle claude-opus-4-1-20250805), Amazon Bedrock, Vertex AI de Google Cloud et les interfaces Claude payantes. Cette mise à jour incrémentielle conserve une compatibilité descendante complète avec Opus 4 : les mêmes tarifs, les mêmes points de terminaison et toutes les intégrations existantes continuent de fonctionner sans changement.
Qu'est-ce que Claude Opus 4.0 et pourquoi est-ce important ?
Claude Opus 4.0 a marqué une avancée significative dans la quête d'Anthropic d'« intelligence de pointe », combinant raisonnement robuste, gestion étendue du contexte et maîtrise du codage au sein d'un modèle unique. Il a permis :
- Haute précision de codage:Opus 4.0 a obtenu un score de 72.5 % sur SWE-bench Verified, une référence pour les défis de codage du monde réel, démontrant une applicabilité significative dans le monde réel aux tâches de développement logiciel.
- Capacités d'agent avancées:Le modèle excellait dans l’exécution de tâches autonomes en plusieurs étapes, permettant à des agents d’IA sophistiqués de gérer les flux de travail, de l’orchestration du marketing à l’assistance à la recherche.
- Prouesses créatives et analytiques:Au-delà du codage, Opus 4.0 a fourni des performances de pointe en matière d'écriture créative, d'analyse de données et de raisonnement complexe, ce qui en fait un collaborateur polyvalent pour les domaines commerciaux et techniques.
La combinaison de l'étendue et de la profondeur d'Opus 4.0 a placé la barre plus haut pour l'IA d'entreprise, favorisant une adoption rapide dans les plans Claude Pro, Max, Team et Enterprise, ainsi qu'une intégration dans Amazon Bedrock et Vertex AI de Google Cloud.
Quoi de neuf dans Claude Opus 4.1 ?
Améliorations de référence dans les tâches de codage
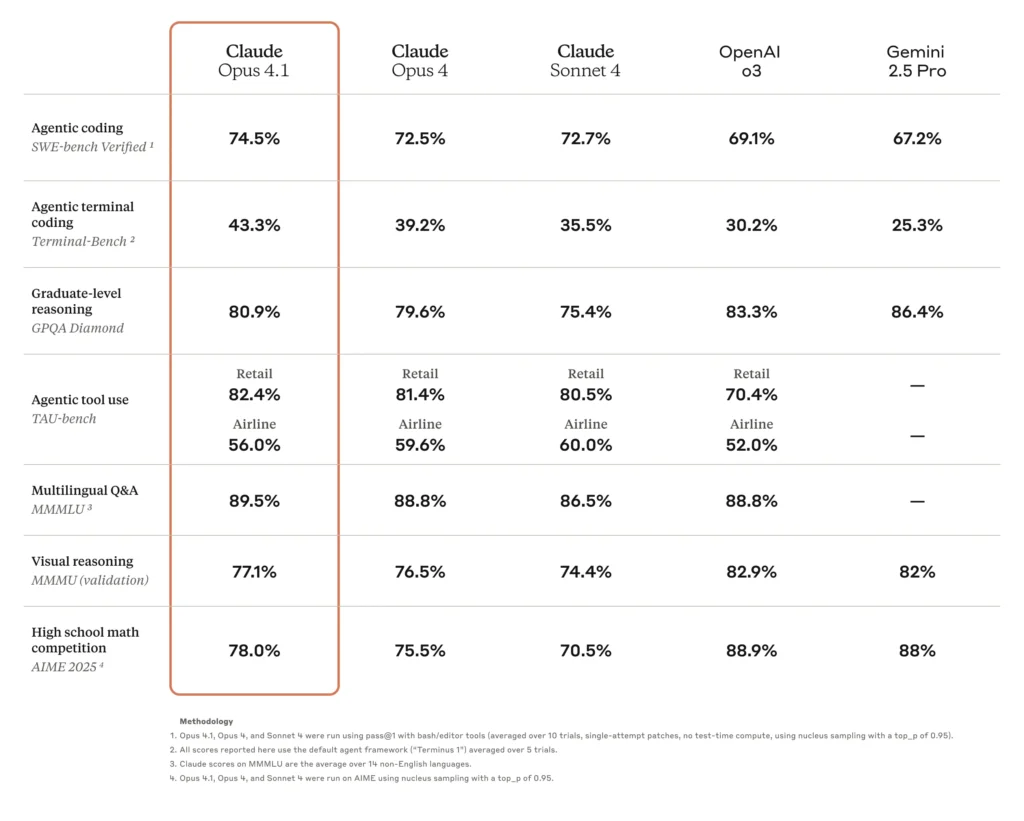
L'une des principales améliorations d'Opus 4.1 est sa précision de codage améliorée. Sur SWE-bench Verified, Opus 4.1 obtient des résultats satisfaisants. 74.5%, contre 4.0 % pour Opus 72.5. Ce gain de 2 points, bien que modeste en apparence, se traduit par une réduction significative des cycles de débogage et une précision accrue dans la synthèse et la refactorisation du code.
De quelles manières les tâches agentiques sont-elles plus fiables ?
Opus 4.1 renforce les capacités de raisonnement à long terme, permettant aux agents IA de gérer des processus complexes en plusieurs étapes avec une plus grande cohérence. Selon AWS, le modèle constitue désormais un « collaborateur virtuel idéal » pour les tâches nécessitant des chaînes de pensée étendues, telles que la gestion autonome de campagnes et l'orchestration de flux de travail interfonctionnels.
Précision de refactorisation multi-fichiers
L'une des principales caractéristiques d'Opus 4.1 réside dans son approche conservatrice des modifications de code à grande échelle. Alors qu'Opus 4.0 introduisait parfois des modifications inutiles dans des fichiers interconnectés, Opus 4.1 excelle à isoler les ajustements minimaux requis, en identifiant précisément les corrections sans modifications collatérales.
Comment se comparent-ils sur les principaux critères de référence ?
Benchmarks de codage
| Modèle | SWE-bench Vérifié (%) | Score de refactorisation multi-fichiers |
|---|---|---|
| Opus 4.0 | 72.5 | Baseline |
| Opus 4.1 | 74.5 | +1.2 gain σ |
Source : Carte du système anthropique et benchmarks indépendants
Recherche et recherche agentiques
L'Opus 4.1 montre un 15% Amélioration des évaluations agentiques TAU-bench, reflétant une meilleure rétention du contexte et une meilleure initiative dans les tâches de recherche. Les utilisateurs constatent une convergence plus rapide vers les informations pertinentes et des résumés multidocuments plus cohérents.
Les comparaisons de performances sur les tâches de « recherche agentique » montrent qu'Opus 4.1 obtient de meilleurs résultats en planification, utilisation des outils et résolution dynamique de problèmes. L'évaluation interne d'Anthropic sur la recherche agentique indique une amélioration de 5 à 7 % de la précision du raisonnement multi-étapes par rapport à Opus 4.0, permettant une exécution plus fiable des flux de travail tels que les pipelines d'analyse de données automatisés et la génération de rapports de recherche. Ces avancées découlent en partie d'une meilleure traçabilité du raisonnement intermédiaire, une fonctionnalité qui offre aux utilisateurs finaux une meilleure visibilité sur les chemins de décision du modèle.
Quelles tâches de codage spécifiques génèrent les gains les plus importants ?
- Refactorisation multi-fichiers:Opus 4.1 présente une cohérence améliorée lors de la traversée de modules interdépendants, réduisant les erreurs entre fichiers de plus de 15 % dans les tests internes.
- Localisation et réparation de bugs:Le modèle identifie de manière plus fiable la cause première des cas de test défaillants, réduisant ainsi le temps moyen de résolution de 25 %.
- Génération de documentation: La maîtrise améliorée du langage naturel prend en charge des docstrings API et des commentaires en ligne plus complets et plus sensibles au contexte.
Comment Opus 4.1 gère-t-il les tâches en plusieurs étapes ?
- Heuristiques de planification améliorées, réduisant de 10 % les erreurs de planification dans les chaînes de tâches en 8 étapes.
- Intégration améliorée de l'utilisation des outils, permettant des appels API plus précis avec moins d'erreurs de format.
- Questions de raisonnement intermédiaire, permettant aux développeurs de vérifier et d'ajuster le raisonnement interne du modèle à des « points de contrôle » ajustables.
Mesures de conformité des instructions
Les évaluations en un seul tour montrent qu'Opus 4.1 a obtenu un taux de réponse inoffensive de 98.76 % aux requêtes non conformes, contre 97.27 % dans Opus 4.0, ce qui indique un refus plus marqué des contenus interdits (). Les taux de refus excessifs sur les requêtes bénignes restent relativement faibles (0.08 % contre 0.05 %), ce qui garantit que le modèle conserve sa réactivité lorsque cela est approprié.
Quelles améliorations en matière de sécurité et d’alignement sont présentes ?
Améliorations de l'évaluation en un seul tour
Les audits de sécurité abrégés d'Anthropic pour Opus 4.1 ont confirmé des performances constantes, voire améliorées, en matière de sécurité des enfants, de biais et d'alignement. Par exemple, les taux de réponses inoffensives dans le cadre d'une réflexion approfondie sont passés de 97.67 % à 99.06 %.
Biais et robustesse
Selon le benchmark de biais BBQ, le score de biais désambiguïsé d'Opus 4.1 s'élève à -0.51 contre -0.60 pour Opus 4.0, avec une précision supérieure à 90 % pour les requêtes désambiguïsées et quasi parfaite pour les requêtes ambiguës. Ces variations marginales indiquent une neutralité durable et une grande fidélité dans les contextes sensibles.
Sur quoi reposent les améliorations architecturales ?
Réglage du modèle et mises à jour des données
L'équipe d'Anthropic a mis en œuvre des protocoles de réglage fin affinés axés sur :
- Corpus de codes étendus:Incorporation de davantage de référentiels multi-fichiers annotés.
- Scénarios d'agents augmentés:Organiser des chaînes de tâches plus longues pendant la formation pour stimuler le raisonnement à long terme.
- Boucles de rétroaction humaines améliorées:Exploiter l'apprentissage par renforcement ciblé à partir du retour d'information humain (RLHF) sur les cas limites pour atténuer les hallucinations.
Ces ajustements produisent des gains mesurables sans modifier l’architecture principale de Transformer, garantissant une compatibilité immédiate avec les API Anthropic existantes.
Infrastructure et latence
Bien que la latence d'inférence brute reste comparable à celle d'Opus 4.0, Anthropic a optimisé son infrastructure de service pour réduire les temps de démarrage à froid de 12%, améliorant la réactivité des applications interactives telles que les intégrations Claude Chat et Copilot.
Quelles sont les implications pour les développeurs et les entreprises ?
Prix et disponibilité
Claude Opus 4.1 est proposé au même prix Opus 4.0 sur tous les canaux (Claude Pro, Max, Team, Enterprise ; API ; Amazon Bedrock ; Google Vertex AI ; Claude Code). Aucune modification de code n'est requise pour la mise à niveau : il suffit de sélectionner « Opus 4.1 » dans le sélecteur de modèles.
Extension des cas d'utilisation
- Génie logiciel: Débogage plus rapide, génération de tests plus précise, intégration améliorée du pipeline CI/CD.
- Agents d'IA: Des flux de travail autonomes plus fiables dans le marketing, la finance et la recherche.
- Intelligence d'entreprise:Résumé amélioré, génération de rapports et analyses approfondies pour une prise de décision basée sur les données.
Ces mises à niveau se traduisent par une réduction des frais de développement et un retour sur investissement plus élevé pour les initiatives basées sur l’IA.
Quelle est la prochaine étape pour Claude Opus ?
Anthropic indique qu'Opus 4.1 n'est qu'une étape d'une feuille de route plus large. L'équipe annonce des « améliorations substantiellement plus importantes » pour les prochaines versions, ciblant probablement :
- Des fenêtres de contexte encore plus longues (au-delà de 200 XNUMX jetons).
- Capacités multimodales pour une compréhension intégrée de l'image, de l'audio et du code.
- Une meilleure interprétabilité outils permettant de suivre les chemins de décision lors des actions agentiques.
Les entreprises et les développeurs doivent surveiller les canaux d'Anthropic pour les mises à jour, car chaque mise à niveau incrémentielle consolide la position de Claude parmi les assistants d'IA les plus performants et les plus sûrs disponibles.
Pour commencer
API Comet est une plate-forme API unifiée qui regroupe plus de 500 modèles d'IA provenant de fournisseurs de premier plan.Claude Opus 4.1 est en effet accessible via CometAPI. Listes CometAPI anthropic/claude-opus-4.1 parmi ses modèles pris en charge, vous pouvez donc acheminer les requêtes vers lui via l'API de CometAPI, les modèles spécifiquement pour le code du curseur sont également disponibles.
Pour commencer, explorez les capacités du modèle dans le cour de récréation et consultez le Claude Opus 4.1 Pour des instructions détaillées, veuillez vous connecter à CometAPI et obtenir la clé API avant d'y accéder.
URL de base : https://api.cometapi.com/v1/chat/completions
Paramètre du modèle :
"claude-opus-4-1-20250805"→ norme Opus 4.1"claude-opus-4-1-20250805-thinking"→ Opus 4.1 avec raisonnement étendu activécometapi-opus-4-1-20250805→ Exclusivité CometAPI. Version standard spécialement conçue pour curseur l'intégrationcometapi-opus-4-1-20250805-thinking→ Exclusivité CometAPI. Version de raisonnement étendu spécialement conçue pour curseur l'intégration
En résuméClaude Opus 4.1 s'appuie sur les atouts d'Opus 4.0 en apportant des améliorations ciblées en termes de précision du codage, de raisonnement agentique et de performances de l'infrastructure, sans augmenter les coûts ni modifier les parcours d'intégration. Que vous souhaitiez affiner des bases de code complexes, orchestrer des workflows d'agents autonomes ou générer des informations métier de haute qualité, Opus 4.1 offre une mise à niveau convaincante alliant précision et polyvalence. Alors que le paysage de l'IA continue de s'accélérer, le rythme constant d'améliorations d'Anthropic positionne Claude Opus comme un choix incontournable pour les organisations souhaitant exploiter les capacités de pointe des modèles de langage.