

Ces derniers mois ont été marqués par une escalade rapide du codage agentiel : des modèles spécialisés qui ne se contentent pas de répondre à des requêtes ponctuelles, mais planifient, modifient, testent et itèrent sur des référentiels entiers. Deux des acteurs les plus en vue sont : Compositeur, un modèle de codage à faible latence spécialement conçu à cet effet et introduit par Cursor avec sa version Cursor 2.0, et Codex GPT-5L'exemple présenté ici est une variante de GPT-5 optimisée pour les agents et adaptée aux flux de travail de programmation continus. Ensemble, ces éléments illustrent les nouvelles lignes de fracture dans les outils de développement : vitesse contre profondeur, connaissance de l'espace de travail local contre raisonnement généraliste, et facilité de programmation intuitive contre rigueur technique.
En bref : distinctions directes
- Intention de conception : GPT-5-Codex — raisonnement profond et autonome, et robustesse pour les sessions longues et complexes ; Composer — itération rapide et adaptée à l’espace de travail, optimisée pour la vitesse.
- Surface d'intégration principale : GPT-5-Codex — API de produit Codex/Réponses, IDE, intégrations d'entreprise ; Composer — Éditeur de curseur et interface utilisateur multi-agent du curseur.
- Latence/itération : Composer met l'accent sur des virages inférieurs à 30 secondes et revendique des avantages de vitesse importants ; GPT-5-Codex privilégie la rigueur et les exécutions autonomes de plusieurs heures lorsque cela est nécessaire.
J'ai testé le API GPT-5-Codex modèle fourni par API Comet (un fournisseur d'agrégation d'API tiers, dont les prix des API sont généralement moins chers que ceux de l'API officielle), a résumé mon expérience d'utilisation du modèle Composer de Cursor 2.0 et a comparé les deux dans diverses dimensions du jugement de génération de code.
Que sont Composer et GPT-5-Codex ?
Qu'est-ce que GPT-5-Codex et quels problèmes vise-t-il à résoudre ?
GPT-5-Codex d'OpenAI est une version spécialisée de GPT-5 optimisée, selon OpenAI, pour les scénarios de programmation automatisée : exécution de tests, modifications de code à grande échelle et itérations autonomes jusqu'à validation. L'accent est mis sur une large capacité à couvrir de nombreuses tâches d'ingénierie : un raisonnement approfondi pour les refactorisations complexes, un fonctionnement automatisé à long terme (où le modèle peut consacrer de quelques minutes à plusieurs heures au raisonnement et aux tests) et des performances accrues sur des benchmarks standardisés conçus pour refléter les problèmes d'ingénierie du monde réel.
Qu'est-ce que Composer et quels problèmes vise-t-il à résoudre ?
Composer est le premier modèle de codage natif de Cursor, introduit avec Cursor 2.0. Cursor le décrit comme un modèle novateur, centré sur l'agent, conçu pour une faible latence et une itération rapide au sein des flux de travail des développeurs : planification des différences entre plusieurs fichiers, application de la recherche sémantique à l'échelle du dépôt et réalisation de la plupart des itérations en moins de 30 secondes. Il a été entraîné avec un accès aux outils en boucle (recherche, édition, environnements de test) afin d'être efficace sur les tâches d'ingénierie pratiques et de minimiser les frictions liées aux cycles répétés d'interaction dans le codage quotidien. Cursor positionne Composer comme un modèle optimisé pour la vélocité des développeurs et les boucles de rétroaction en temps réel.
Portée du modèle et comportement d'exécution
- Compositeur: Optimisé pour des interactions rapides et centrées sur l'éditeur, ainsi que pour la cohérence des fichiers multiples, Cursor s'intègre à la plateforme. Il permet ainsi à Composer d'accéder à une plus grande partie du dépôt et de participer à une orchestration multi-agents (par exemple, deux agents Composer contre d'autres), ce qui, selon Cursor, réduit les risques de dépendances non détectées entre les fichiers.
- Codex GPT-5 : Optimisé pour un raisonnement plus approfondi et de longueur variable, le modèle OpenAI est capable d'adapter le temps de calcul au besoin, en privilégiant un raisonnement plus poussé. Le temps de calcul peut varier de quelques secondes pour les tâches légères à plusieurs heures pour les exécutions autonomes complexes, permettant ainsi des refactorisations plus poussées et un débogage guidé par les tests.
Version courte : Composer = Modèle de codage intégré à l’IDE de Cursor, prenant en compte l’espace de travail ; GPT-5-Codex = Variante spécialisée de GPT-5 d’OpenAI pour l’ingénierie logicielle, disponible via Responses/Codex.
Comment Composer et GPT-5-Codex se comparent-ils en termes de vitesse ?
Qu'ont affirmé les vendeurs ?
Cursor positionne Composer comme un outil de codage ultra-rapide : les chiffres publiés mettent en avant un débit de génération mesuré en jetons par seconde et des temps d'exécution interactifs 2 à 4 fois plus rapides que les modèles de pointe dans l'environnement interne de Cursor. Des sources indépendantes (presse et premiers testeurs) indiquent que Composer produit du code à environ 200-250 jetons/seconde dans l'environnement de Cursor et exécute des cycles de codage interactifs typiques en moins de 30 secondes dans de nombreux cas.
Le GPT-5-Codex d'OpenAI n'est pas conçu comme une expérience de latence ; il privilégie la robustesse et un raisonnement plus approfondi et, sur des charges de travail de raisonnement élevées comparables, il peut être plus lent lorsqu'il est utilisé avec des tailles de contexte plus importantes, selon les rapports de la communauté et les discussions sur les problèmes rencontrés.
Comment nous avons évalué la vitesse (méthodologie)
Pour obtenir une comparaison de vitesse équitable, il faut contrôler le type de tâche (exécutions courtes vs raisonnement long), l'environnement (latence réseau, intégration locale vs cloud) et mesurer les deux. délai d'obtention du premier résultat utile et horloge murale de bout en bout (y compris toute étape d'exécution de test ou de compilation). Points clés :
- Tâches choisies — petite génération de code (implémentation d'un point de terminaison d'API), tâche moyenne (refactorisation d'un fichier et mise à jour des importations), tâche importante (implémentation d'une fonctionnalité sur trois fichiers, mise à jour des tests).
- Métrique — temps d'obtention du premier jeton, temps d'obtention de la première différence utile (temps jusqu'à l'émission du correctif candidat) et temps total incluant l'exécution et la vérification des tests.
- Répétitions — chaque tâche est exécutée 10 fois, la médiane étant utilisée pour réduire le bruit du réseau.
- Environnement — Mesures prises à partir d'une machine de développement à Tokyo (pour refléter la latence réelle) avec une liaison stable de 100/10 Mbps ; les résultats varieront selon les régions.
Ci-dessous figure un exemple reproductible harnais de vitesse pour GPT-5-Codex (API de réponses) et une description de la manière de mesurer Composer (dans Cursor).
Outil d'optimisation de la vitesse (Node.js) — GPT-5-Codex (API de réponses) :
// node speed_harness_gpt5_codex.js
// Requires: node16+, npm install node-fetch
import fetch from "node-fetch";
import { performance } from "perf_hooks";
const API_KEY = process.env.OPENAI_API_KEY; // set your key
const ENDPOINT = "https://api.openai.com/v1/responses"; // OpenAI Responses API
const MODEL = "gpt-5-codex";
async function runPrompt(prompt) {
const start = performance.now();
const body = {
model: MODEL,
input: prompt,
// small length to simulate short interactive tasks
max_output_tokens: 256,
};
const resp = await fetch(ENDPOINT, {
method: "POST",
headers: {
"Authorization": `Bearer ${API_KEY}`,
"Content-Type": "application/json"
},
body: JSON.stringify(body)
});
const json = await resp.json();
const elapsed = performance.now() - start;
return { elapsed, output: json };
}
(async () => {
const prompt = "Implement a Node.js Express route POST /signup that validates email and stores user in-memory with hashed password (bcrypt). Return code only.";
const trials = 10;
for (let i=0;i<trials;i++){
const r = await runPrompt(prompt);
console.log(`trial ${i+1}: ${Math.round(r.elapsed)} ms`);
}
})();
Cela mesure la latence de requête de bout en bout pour GPT-5-Codex en utilisant l'API Responses publique (la documentation OpenAI décrit l'API Responses et l'utilisation du modèle gpt-5-codex).
Comment mesurer la vitesse du compositeur (curseur) :
Composer s'exécute au sein de Cursor 2.0 (version de bureau/VS Code). À l'heure actuelle, Cursor ne fournit pas d'API HTTP externe générale pour Composer équivalente à l'API Responses d'OpenAI ; le point fort de Composer est… intégration d'espaces de travail avec état dans l'IDEPar conséquent, évaluez Composer comme le ferait un développeur humain :
- Ouvrez le même projet dans Cursor 2.0.
- Utilisez Composer pour exécuter la même invite en tant que tâche d'agent (créer une route, refactoriser, modifier plusieurs fichiers).
- Démarrez un chronomètre lorsque vous soumettez le plan Composer ; arrêtez-le lorsque Composer émet la différence atomique et exécute la suite de tests (l'interface de Cursor peut exécuter des tests et afficher une différence consolidée).
- Répétez 10 fois et utilisez la médiane.
Les documents publiés par Cursor et les tests pratiques montrent que Composer accomplit de nombreuses tâches courantes en moins de 30 secondes environ en pratique ; il s'agit d'un objectif de latence interactive plutôt que d'un temps d'inférence de modèle brut.
Emporter: Composer est conçu pour permettre des modifications interactives rapides au sein d'un éditeur ; si votre priorité est une faible latence et des boucles de codage conversationnelles, Composer est fait pour cela. GPT-5-Codex est optimisé pour la correction et le raisonnement automatisé sur de longues sessions ; il peut accepter une latence légèrement supérieure au profit d'une planification plus poussée. Les chiffres des fournisseurs confirment ce positionnement.
Comment Composer et GPT-5-Codex se comparent-ils en termes de précision ?
Que signifie la précision en programmation IA ?
La précision est ici multiforme : correction fonctionnelle (le code compile-t-il et réussit-il les tests ?) correction sémantique (le comportement est-il conforme aux spécifications ?), et solidité (gère les cas particuliers et les problèmes de sécurité).
Numéros des fournisseurs et de la presse
OpenAI annonce d'excellentes performances de GPT-5-Codex sur les jeux de données validés par SWE-bench et souligne un 74.5 taux de réussite% sur un benchmark de codage réel (rapporté dans la presse) et une augmentation notable du succès de la refactorisation (51.3 % contre 33.9 % pour GPT-5 de base sur leur test de refactorisation interne).
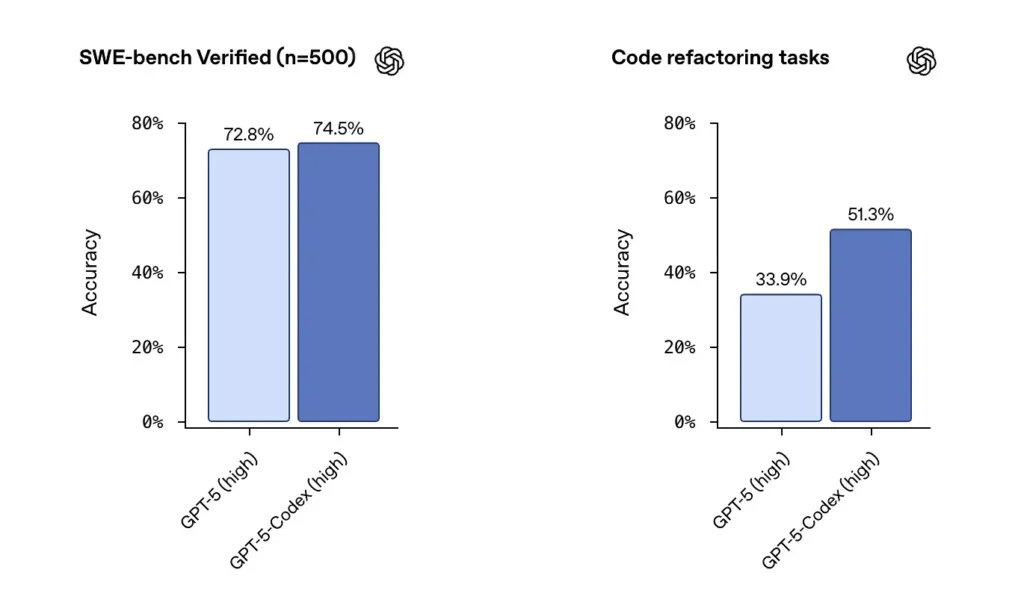
Les informations de Cursor indiquent que Composer excelle souvent dans les modifications multifichiers contextuelles où l'intégration à l'éditeur et la visibilité du dépôt sont essentielles. Mes tests ont montré que Composer générait moins d'erreurs de dépendances manquées lors des refactorisations multifichiers et obtenait de meilleurs résultats aux tests de revue à l'aveugle pour certaines charges de travail multifichiers. La faible latence et les fonctionnalités d'agents parallèles de Composer contribuent également à améliorer la vitesse d'itération.
Tests de précision indépendants (méthode recommandée)
Un test équitable utilise un mélange de :
- Tests unitaires: alimenter les deux modèles avec le même dépôt et la même suite de tests ; générer le code, exécuter les tests.
- tests de refactorisation: fournir une fonction volontairement complexe et demander au modèle de la refactoriser et d'ajouter des tests.
- Contrôles de sécurité: exécuter des outils d'analyse statique et SAST sur le code généré (par exemple, Bandit, ESLint, semgrep).
- Examen humain: Évaluation du code par des ingénieurs expérimentés concernant la maintenabilité et les meilleures pratiques.
Exemple : banc d’essai automatisé (Python) — exécution du code généré et des tests unitaires
# python3 run_generated_code.py
# This is a simplified harness: it writes model output to file, runs pytest, captures results.
import subprocess, tempfile, os, textwrap
def write_file(path, content):
with open(path, "w") as f:
f.write(content)
# Suppose `generated_code` is the string returned from model
generated_code = """
# sample module
def add(a,b):
return a + b
"""
tests = """
# test_sample.py
from sample import add
def test_add():
assert add(2,3) == 5
"""
with tempfile.TemporaryDirectory() as d:
write_file(os.path.join(d, "sample.py"), generated_code)
write_file(os.path.join(d, "test_sample.py"), tests)
r = subprocess.run(, cwd=d, capture_output=True, text=True, timeout=30)
print("pytest returncode:", r.returncode)
print(r.stdout)
print(r.stderr)
Utilisez ce modèle pour vérifier automatiquement si la sortie du modèle est fonctionnellement correcte (tests réussis). Pour les tâches de refactorisation, exécutez le test sur le dépôt d'origine et les différences du modèle, puis comparez les taux de réussite des tests et les variations de couverture.
Emporter: Sur les suites de tests de performance brutes, GPT-5-Codex affiche d'excellents résultats et une grande capacité de refactorisation. Dans des environnements réels de réparation de fichiers multiples et de travail d'édition, la prise en compte de l'espace de travail par Composer permet une meilleure acceptation pratique et réduit les erreurs « mécaniques » (importations manquantes, noms de fichiers incorrects). Pour une correction fonctionnelle maximale dans les tâches algorithmiques sur un seul fichier, GPT-5-Codex est un candidat de choix ; pour les modifications de fichiers multiples, sensibles aux conventions, au sein d'un EDI, Composer excelle souvent.
Composer vs GPT-5 : comment se comparent-ils en termes de qualité de code ?
Qu’est-ce qui est considéré comme de la qualité ?
La qualité englobe la lisibilité, la dénomination, la documentation, la couverture des tests, l'utilisation de conventions idiomatiques et les bonnes pratiques de sécurité. Elle est mesurée à la fois automatiquement (analyse de code, métriques de complexité) et qualitativement (revue humaine).
Différences observées
- Codex GPT-5: Excellente capacité à produire des modèles idiomatiques lorsqu'on le lui demande explicitement ; maîtrise la clarté algorithmique et peut générer des suites de tests complètes sur demande. L'outil Codex d'OpenAI inclut des fonctionnalités intégrées de test, de génération de rapports et de journaux d'exécution.
- CompositeurOptimisé pour respecter automatiquement le style et les conventions d'un dépôt, Composer peut suivre les modèles de projet existants et coordonner les mises à jour de plusieurs fichiers (propagation des renommages et des refactorisations, importation des mises à jour). Il offre une excellente maintenabilité à la demande pour les grands projets.
Exemples de contrôles de qualité du code que vous pouvez exécuter
- Linters — ESLint / pylint
- Complexité — radon / flake8-complexité
- Sécurité — semgrep / Bandit
- Couverture de test — Exécutez coverage.py ou vitest/nyc pour JS
Automatisez ces vérifications après l'application du correctif au modèle afin de quantifier les améliorations ou les régressions. Exemple de séquence de commandes (dépôt JS) :
# after applying model patch
npm ci
npm test
npx eslint src/
npx semgrep --config=auto .
Examen humain et meilleures pratiques
En pratique, les modèles nécessitent des instructions pour respecter les bonnes pratiques : spécifier les docstrings, les annotations de type, l’épinglage des dépendances ou des modèles spécifiques (par exemple, async/await). GPT-5-Codex est excellent lorsqu’il reçoit des directives explicites ; Composer tire parti du contexte implicite du dépôt. Adoptez une approche combinée : indiquez explicitement le modèle et laissez Composer appliquer le style du projet si vous utilisez Cursor.
Recommandation: Pour les travaux d'ingénierie multi-fichiers au sein d'un IDE, privilégiez Composer ; pour les pipelines externes, les tâches de recherche ou l'automatisation de la chaîne d'outils où vous pouvez appeler une API et fournir un contexte important, GPT-5-Codex est un excellent choix.
Intégrations et options de déploiement
Composer est fourni avec Cursor 2.0 et intégré à l'éditeur et à l'interface utilisateur de Cursor. L'approche de Cursor privilégie un plan de contrôle unique qui exécute Composer parallèlement à d'autres modèles, permettant ainsi aux utilisateurs d'exécuter plusieurs instances de modèles sur la même invite et de comparer les résultats directement dans l'éditeur. ()
GPT-5-Codex est intégré à l'offre Codex d'OpenAI et à la gamme de produits ChatGPT. Il est disponible via les abonnements payants de ChatGPT et son API, tandis que des plateformes tierces comme CometAPI offrent un meilleur rapport qualité-prix. OpenAI intègre également Codex à ses outils de développement et aux flux de travail de ses partenaires cloud (par exemple, les intégrations Visual Studio Code/GitHub Copilot).
Où Composer et GPT-5-Codex pourraient-ils faire progresser l'industrie ensuite ?
Effets à court terme
- Cycles d'itération plus rapides : Les modèles intégrés à l'éditeur, comme Composer, réduisent les frictions liées aux petites corrections et à la génération de demandes de fusion.
- Des attentes croissantes en matière de vérification : L'accent mis par Codex sur les tests, les journaux et les capacités autonomes incitera les fournisseurs à proposer une vérification prête à l'emploi plus robuste pour le code produit par le modèle.
moyen et long terme
- L'orchestration multi-modèles devient la norme : L'interface graphique multi-agents de Cursor est un premier indice que les ingénieurs s'attendront bientôt à exécuter plusieurs agents spécialisés en parallèle (analyse statique du code, sécurité, refactorisation, optimisation des performances) et à accepter les meilleurs résultats.
- Boucles de rétroaction CI/IA plus étroites : À mesure que les modèles s'améliorent, les pipelines d'intégration continue intégreront de plus en plus la génération de tests pilotée par les modèles et les suggestions de réparation automatisées, mais la vérification humaine et le déploiement progressif restent essentiels.
Conclusion
Composer et GPT-5-Codex ne sont pas des armes identiques dans une même course à l'armement ; ce sont des outils complémentaires optimisés pour différentes phases du cycle de vie du logiciel. La valeur ajoutée de Composer réside dans sa vélocité : une itération rapide et structurée, ancrée dans l'espace de travail, qui maintient les développeurs concentrés. La valeur ajoutée de GPT-5-Codex réside dans sa profondeur : persistance autonome, correction basée sur les tests et auditabilité pour les transformations complexes. La démarche pragmatique d'ingénierie consiste à… orchestrer les deuxDes agents de type Composer à boucle courte pour les opérations courantes et des agents de type GPT-5 Codex pour les opérations critiques à haute fiabilité. Les premiers résultats indiquent que les deux types d'agents feront partie intégrante des outils de développement à court terme, sans que l'un ne remplace l'autre.
Il n'existe pas de modèle unique qui s'impose dans tous les domaines. Chaque modèle a ses points forts :
- Codex GPT-5 : Il excelle particulièrement dans les tests de fiabilité complexes, le raisonnement à grande échelle et les flux de travail autonomes de plusieurs heures. Il est performant lorsque la complexité des tâches exige un raisonnement long ou une vérification poussée.
- Compositeur: Il est plus performant dans les cas d'utilisation nécessitant une intégration poussée avec l'éditeur, une meilleure cohérence du contexte multi-fichiers et une vitesse d'itération rapide au sein de l'environnement Cursor. Il peut s'avérer plus efficace pour améliorer la productivité quotidienne des développeurs qui ont besoin de modifications contextuelles immédiates et précises.
Voir aussi
Cursor 2.0 et Composer : comment une refonte multi-agents a bouleversé le codage de l’IA.
Pour commencer
CometAPI est une plateforme d'API unifiée qui regroupe plus de 500 modèles d'IA provenant de fournisseurs leaders, tels que la série GPT d'OpenAI, Gemini de Google, Claude d'Anthropic, Midjourney, Suno, etc., au sein d'une interface unique et conviviale pour les développeurs. En offrant une authentification, un formatage des requêtes et une gestion des réponses cohérents, CometAPI simplifie considérablement l'intégration des fonctionnalités d'IA dans vos applications. Que vous développiez des chatbots, des générateurs d'images, des compositeurs de musique ou des pipelines d'analyse pilotés par les données, CometAPI vous permet d'itérer plus rapidement, de maîtriser les coûts et de rester indépendant des fournisseurs, tout en exploitant les dernières avancées de l'écosystème de l'IA.
Les développeurs peuvent accéder API GPT-5-Codexvia CometAPI, la dernière version du modèle est constamment mis à jour avec le site officiel. Pour commencer, explorez les capacités du modèle dans la section cour de récréation et consultez le Guide de l'API Pour des instructions détaillées, veuillez vous connecter à CometAPI et obtenir la clé API avant d'y accéder. API Comet proposer un prix bien inférieur au prix officiel pour vous aider à vous intégrer.
Prêt à partir ?→ Inscrivez-vous à CometAPI dès aujourd'hui !
Si vous souhaitez connaître plus de conseils, de guides et d'actualités sur l'IA, suivez-nous sur VK, X et Discord!