
L'API Flash Gemini 2.5 est le dernier modèle d'IA multimodal de Google, conçu pour des tâches rapides et rentables avec des capacités de raisonnement contrôlables, permettant aux développeurs d'activer ou de désactiver des fonctionnalités avancées de « réflexion » via l'API Gemini. Les derniers modèles sont gemini-2.5-flash.
Présentation de Gemini 2.5 Flash
Gemini 2.5 Flash est conçu pour offrir des réponses rapides sans compromettre la qualité du rendu. Il prend en charge les entrées multimodales, notamment le texte, les images, l'audio et la vidéo, ce qui le rend adapté à diverses applications. Accessible via des plateformes comme Google AI Studio et Vertex AI, le modèle offre aux développeurs les outils nécessaires à une intégration fluide dans divers systèmes.
Informations de base (caractéristiques)
Gemini 2.5 Flash présente plusieurs fonctionnalités remarquables Caractéristiques qui le distinguent au sein de la famille Gemini 2.5 :
- Raisonnement hybride: Les développeurs peuvent définir un penser_budget paramètre permettant de contrôler finement le nombre de jetons que le modèle consacre au raisonnement interne avant la sortie.
- Frontière de Pareto: Positionné au point optimal de rapport coût-performance, Flash offre le meilleur rapport prix/intelligence parmi les modèles 2.5.
- Prise en charge multimodale: Processus texte, simples images., face et acoustique nativement, permettant des capacités conversationnelles et analytiques plus riches.
- Contexte du million de jetons:La longueur de contexte inégalée permet une analyse approfondie et une compréhension de longs documents dans une seule requête.
Gestion des versions du modèle
Gemini 2.5 Flash a effectué la transition vers la clé suivante versions:
- gemini-2.5-flash-lite-preview-09-2025 : Amélioration de la convivialité des outils : Performances améliorées sur les tâches complexes en plusieurs étapes, avec une augmentation de 5 % des scores vérifiés par SWE-Bench (de 48.9 % à 54 %). Efficacité améliorée : L'activation du raisonnement permet d'obtenir des résultats de meilleure qualité avec moins de jetons, réduisant ainsi la latence et les coûts.
- Aperçu 04-17:Version en accès anticipé avec capacité de « réflexion », disponible via gemini-2.5-flash-preview-04-17.
- Disponibilité générale stable (GA):Au 17 juin 2025, le point final stable gemini-2.5-flash remplace l'aperçu, garantissant une fiabilité de niveau production sans modification de l'API par rapport à l'aperçu du 20 mai.
- Abandon de l'aperçu: Les points de terminaison d'aperçu devaient être arrêtés le 15 juillet 2025 ; les utilisateurs doivent migrer vers le point de terminaison GA avant cette date.
Depuis juillet 2025, Gemini 2.5 Flash est désormais disponible publiquement et stable (aucun changement par rapport à la version précédente). gemini-2.5-flash-preview-05-20 ).Si vous utilisez gemini-2.5-flash-preview-04-17La version préliminaire actuelle sera maintenue jusqu'à la mise hors service prévue du point de terminaison du modèle, le 15 juillet 2025. Vous pouvez migrer vers la version généralement disponible.gemini-2.5-flash».
Plus rapide, moins cher, plus intelligent :
- Objectifs de conception : faible latence + débit élevé + faible coût ;
- Accélération globale du raisonnement, du traitement multimodal et des tâches de texte long ;
- L’utilisation des jetons est réduite de 20 à 30 %, ce qui réduit considérablement les coûts de raisonnement.
Spécifications techniques
Fenêtre de contexte d'entrée : jusqu'à 1 million de jetons, permettant une conservation étendue du contexte.
Jetons de sortie : capable de générer jusqu'à 8,192 XNUMX jetons par réponse.
Modalités prises en charge : Texte, images, audio et vidéo.
Plateformes d'intégration : disponibles via Google AI Studio et Vertex AI.
Tarification : Modèle de tarification compétitif basé sur des jetons, facilitant un déploiement rentable.
Détails techniques
Sous le capot, Gemini 2.5 Flash est un à base de transformateur Modèle de langage de grande taille formé à partir d'un mélange de données Web, de code, d'images et de vidéos. technique les spécifications comprennent :
Formation multimodale:Formé pour aligner plusieurs modalités, Flash peut mélanger de manière transparente du texte avec simples images., face , ou acoustique, utile pour des tâches telles que le résumé vidéo ou le sous-titrage audio.
Processus de pensée dynamique: Implémente une boucle de raisonnement interne où le modèle rémunération et décompose les invites complexes avant la sortie finale.
Budgets de réflexion configurables: Les penser_budget peut être réglé à partir de 0 (sans raisonnement) jusqu'à Jetons 24,576, permettant des compromis entre latence et qualité de réponse.
Intégration d'outil: Les soutiens Mise à la terre avec la recherche Google, Exécution de code, Contexte de l'URLet Appel de fonction, permettant des actions du monde réel directement à partir d'invites en langage naturel.
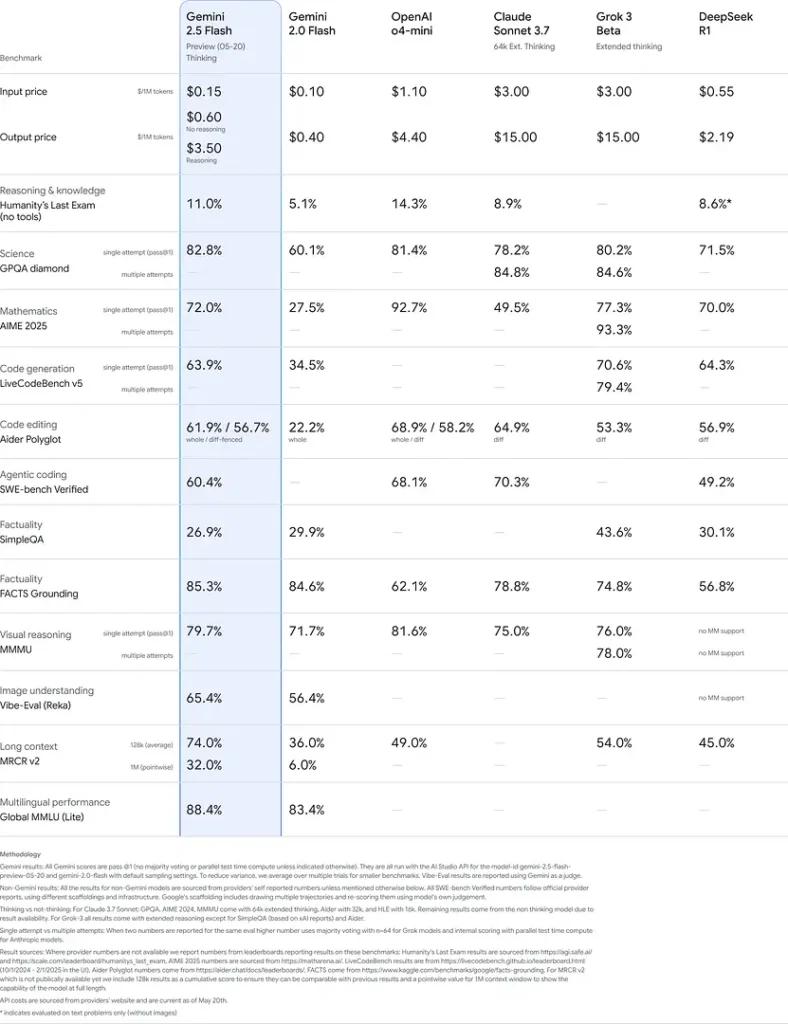
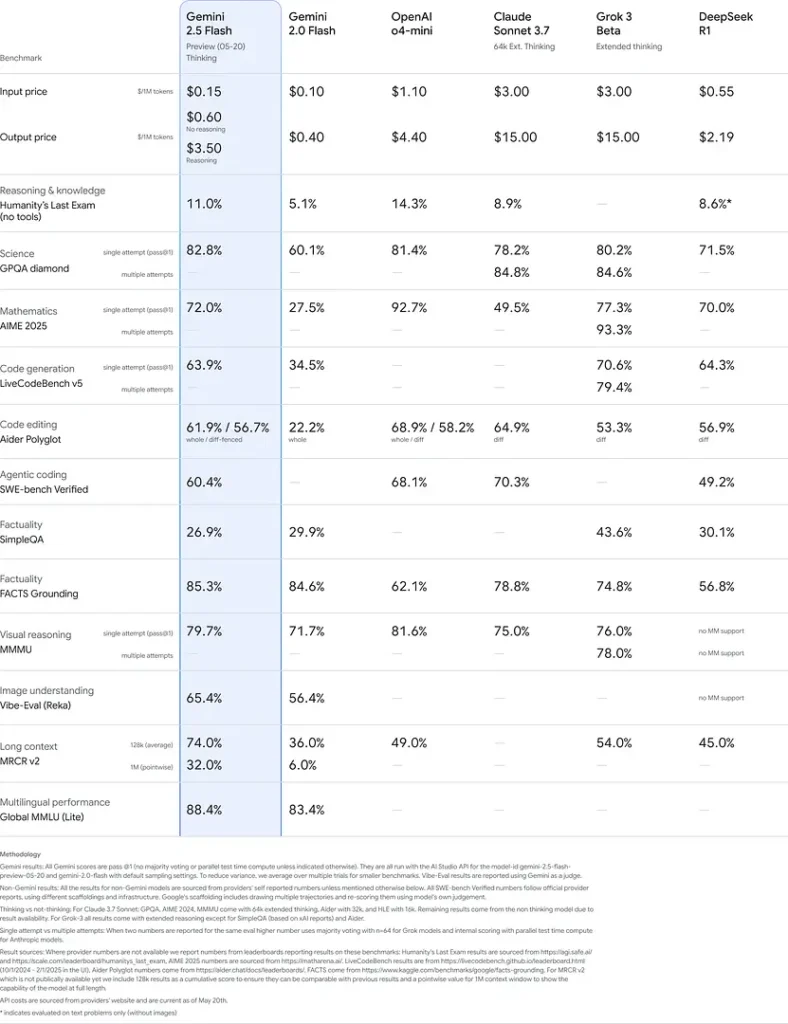
Performances de référence
Lors d'évaluations rigoureuses, Gemini 2.5 Flash démontre leader de l'industrie performance:
- Invites difficiles de LMArena:Marqué deuxième seulement après le 2.5 Pro sur le benchmark difficile Hard Prompts, mettant en valeur de solides capacités de raisonnement en plusieurs étapes.
- Score MMLU de 0.809:Dépasse les performances moyennes du modèle avec un 0.809 Précision du MMLU, reflétant sa vaste connaissance du domaine et ses prouesses de raisonnement.
- Latence et débit: Réalise 271.4 jetons/sec vitesse de décodage avec un 0.29 s de temps jusqu'au premier jeton, ce qui le rend idéal pour les charges de travail sensibles à la latence.
- Leader en matière de rapport qualité-prix: A $0.26/1 M jetonsFlash surpasse de nombreux concurrents tout en les égalant ou en les surpassant sur des critères clés.
Ces résultats indiquent l’avantage concurrentiel de Gemini 2.5 Flash en matière de raisonnement, de compréhension scientifique, de résolution de problèmes mathématiques, de codage, d’interprétation visuelle et de capacités multilingues :
Limites
Bien que puissant, Gemini 2.5 Flash possède certaines limites:
- Risques de sécurité:Le modèle peut présenter un ton « moralisateur » et peut produire des résultats plausibles, mais incorrects ou biaisés (hallucinations), notamment pour les requêtes marginales. Une surveillance humaine rigoureuse demeure essentielle.
- Limites de taux:L'utilisation de l'API est limitée par des limites de débit (10 tr/min, 250,000 250 TPM, XNUMX RPD sur les niveaux par défaut), ce qui peut avoir un impact sur le traitement par lots ou les applications à volume élevé.
- Étage du renseignement:Bien qu'exceptionnellement capable pour un flash modèle, il reste moins précis que 2.5 Pro sur les tâches agentiques les plus exigeantes comme le codage avancé ou la coordination multi-agents.
- Compromis de coûts:Bien qu'offrant le meilleur prix-performance, utilisation intensive de la thinking le mode augmente la consommation globale de jetons, augmentant les coûts des invites de raisonnement en profondeur.
Voir aussi API Gemini 2.5 Pro
Conclusion
Gemini 2.5 Flash témoigne de l'engagement de Google en faveur du développement des technologies d'IA. Grâce à ses performances robustes, ses capacités multimodales et sa gestion efficace des ressources, il offre une solution complète aux développeurs et aux organisations souhaitant exploiter la puissance de l'intelligence artificielle dans leurs opérations.
Comment appeler Gemini 2.5 Flash API de CometAPI
Gemini 2.5 Flash Tarification de l'API dans CometAPI, 20 % de réduction sur le prix officiel :
- Jetons d'entrée : 0.24 $/M jetons
- Jetons de sortie : 0.96 $/M jetons
Étapes requises
- Se connecter à cometapi.comSi vous n'êtes pas encore notre utilisateur, veuillez d'abord vous inscrire
- Obtenez la clé API d'accès à l'interface. Cliquez sur « Ajouter un jeton » au niveau du jeton API dans l'espace personnel, récupérez la clé : sk-xxxxx et validez.
- Obtenez l'URL de ce site : https://api.cometapi.com/
Méthodes d'utilisation
- Sélectionnez l'option "**
gemini-2.5-flash**Point de terminaison pour envoyer la requête API et définir le corps de la requête. La méthode et le corps de la requête sont disponibles dans la documentation API de notre site web. Notre site web propose également le test Apifox pour plus de commodité. - Remplacer avec votre clé CometAPI actuelle de votre compte.
- Insérez votre question ou demande dans le champ de contenu : c'est à cela que le modèle répondra.
- Traitez la réponse de l'API pour obtenir la réponse générée.
Pour les informations sur le modèle lancé dans l'API Comet, veuillez consulter https://api.cometapi.com/new-model.
Pour obtenir des informations sur le prix des modèles dans l'API Comet, veuillez consulter https://api.cometapi.com/pricing.
Exemple d'utilisation de l'API
Les développeurs peuvent interagir avec gemini-2.5-flash Grâce à l'API CometAPI, l'intégration à diverses applications est possible. Voici un exemple Python :
import os
from openai import OpenAI
client = OpenAI(
base_url="
https://api.cometapi.com/v1/chat/completions",
api_key="<YOUR_API_KEY>",
)
response = openai.ChatCompletion.create(
model="gemini-2.5-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the concept of quantum entanglement."}
]
)
print(response)
Ce script envoie une invite à Gemini 2.5 Flash modéliser et imprimer la réponse générée, démontrant comment utiliser Gemini 2.5 Flash pour des explications complexes.