

Google et sa branche de recherche DeepMind ont discrètement (puis de manière plus visible) franchi une nouvelle étape majeure dans la feuille de route de Gemini : Gemini 3.1 Pro. La version, déployée sur des interfaces orientées grand public et via CometAPI, est présentée comme une mise à niveau en performance et en raisonnement pour la famille Gemini 3 — promettant un raisonnement long format nettement plus robuste, une compréhension multimodale améliorée et une meilleure évolutivité pour des applications en conditions réelles.
Le tout nouveau modèle de Google — qu’est-ce que Gemini 3.1 Pro ?
Gemini 3.1 Pro est la première mise à jour incrémentale de la famille Gemini 3, positionnée comme un modèle de raisonnement « le plus performant », optimisé pour les tâches à plusieurs étapes, multimodales et agentiques. Mis en préversion publique à la mi-février 2026 (préversion annoncée les 19–20 févr. 2026), le modèle cible explicitement les scénarios nécessitant des chaînes de pensée soutenues, l’utilisation d’outils et une compréhension de long contexte — par exemple : la synthèse de recherche à grande échelle, des agents d’ingénierie qui coordonnent outils et systèmes, et l’analyse multimodale de documents mêlant texte, images, audio et vidéo.
À haut niveau, Gemini 3.1 Pro est décrit par ses concepteurs comme :
- Nativement multimodal — capable d’ingérer et de raisonner sur du texte, des images, de l’audio et de la vidéo.
- Conçu pour le long contexte — prenant en charge des fenêtres de contexte très larges, adaptées à des bases de code entières, des dossiers multi-documents ou de longues transcriptions.
- Optimisé pour un raisonnement fiable et des workflows agentiques, c’est-à-dire qu’il est ajusté pour planifier, appeler des outils et vérifier les sorties sur des tâches multi-étapes.
Pourquoi c’est important maintenant : les organisations et les développeurs passent d’« assistants conversationnels efficaces » à des « agents d’aide à la décision et de recherche à forts enjeux » (rédaction juridique, synthèse R&D, compréhension multimodale de documents). Gemini 3.1 Pro est explicitement conçu pour ce segment — pour réduire les hallucinations, produire un raisonnement traçable et s’intégrer à CometAPI tant pour le prototypage que pour la production.
Quels sont les points forts techniques et fonctionnalités de Gemini 3.1 Pro ?
Multimodalité native et fenêtres de contexte extrêmes
Gemini 3.1 Pro prolonge l’orientation multimodale de la lignée Gemini. D’après la model card et les notes produit, le modèle accepte et raisonne sur du texte, des images, de l’audio et de la vidéo dans un même pipeline — une capacité qui simplifie les workflows quand les types de données sont mêlés (p. ex., des dépositions juridiques avec audio + transcription + scans). Notablement, le modèle prend en charge une fenêtre de contexte de 1,000,000 tokens et peut produire de longues sorties (les notes publiées indiquent des limites de sortie très importantes, adaptées aux tâches long format). Cette échelle le rend apte aux cas d’usage tels que l’analyse de dépôts de code entiers, de documents en plusieurs chapitres, ou de longues transcriptions sans découpage.
« Pensée dynamique » : raisonnement amélioré et planification pas à pas
Google décrit 3.1 Pro comme ayant une « pensée » améliorée — c’est-à-dire une meilleure gestion de la chaîne de pensée interne et une sélection dynamique des stratégies de raisonnement selon la complexité de la tâche. Le modèle est ajusté pour engager une planification explicite multi-étapes quand nécessaire, tout en restant économe en tokens. En pratique, cela se traduit par moins d’hallucinations sur les problèmes complexes et séquentiels et une meilleure constance factuelle sur les benchmarks de raisonnement multi-étapes.
Workflows agentiques et utilisation d’outils
Un axe majeur de conception pour 3.1 Pro est la performance agentique : coordination d’outils, appel à l’ancrage web ou à la recherche, écriture et exécution d’extraits de code, et vérification des sorties via des passes secondaires. Google a intégré 3.1 Pro à des produits centrés sur les agents (p. ex., l’environnement de développement Antigravity) afin de permettre aux modèles d’exécuter des tâches impliquant un éditeur, un terminal et un navigateur — et d’enregistrer des artefacts comme des captures d’écran et des enregistrements de navigation pour vérifier l’avancement. Ces fonctionnalités visent à réduire l’écart entre les modèles qui « donnent des conseils » et ceux qui exécutent réellement des workflows multi-outils de manière fiable.
Sous-modes spécialisés (Deep Research, Deep Think)
Google associe 3.1 Pro à « Deep Research » et mentionne une variante « Deep Think » à venir. Ces sous-modes ciblent — respectivement — les tâches de recherche à haut rappel et une profondeur de raisonnement maximale (avec un coût et une latence de calcul plus élevés). Ils sont destinés aux analystes, chercheurs et développeurs qui ont besoin de sorties plus délibérées et de haute qualité plutôt que des réponses les plus rapides et les moins coûteuses.
Comment Gemini 3.1 Pro se comporte-t-il sur les benchmarks ?
Gemini 3.1 Pro enregistre de fortes progressions par rapport aux résultats précédents de Gemini 3 Pro, prenant souvent la tête sur un large ensemble de mesures de raisonnement multi-étapes et multimodales — mais restant derrière certains concurrents sur des tâches spécialisées spécifiques (notamment certains tests avancés de code ou des suites de questions de niveau expert). En résumé : améliorations générales avec des avantages concurrents ponctuels sur des benchmarks de spécialité.
Principales annonces de benchmarks et chiffres marquants
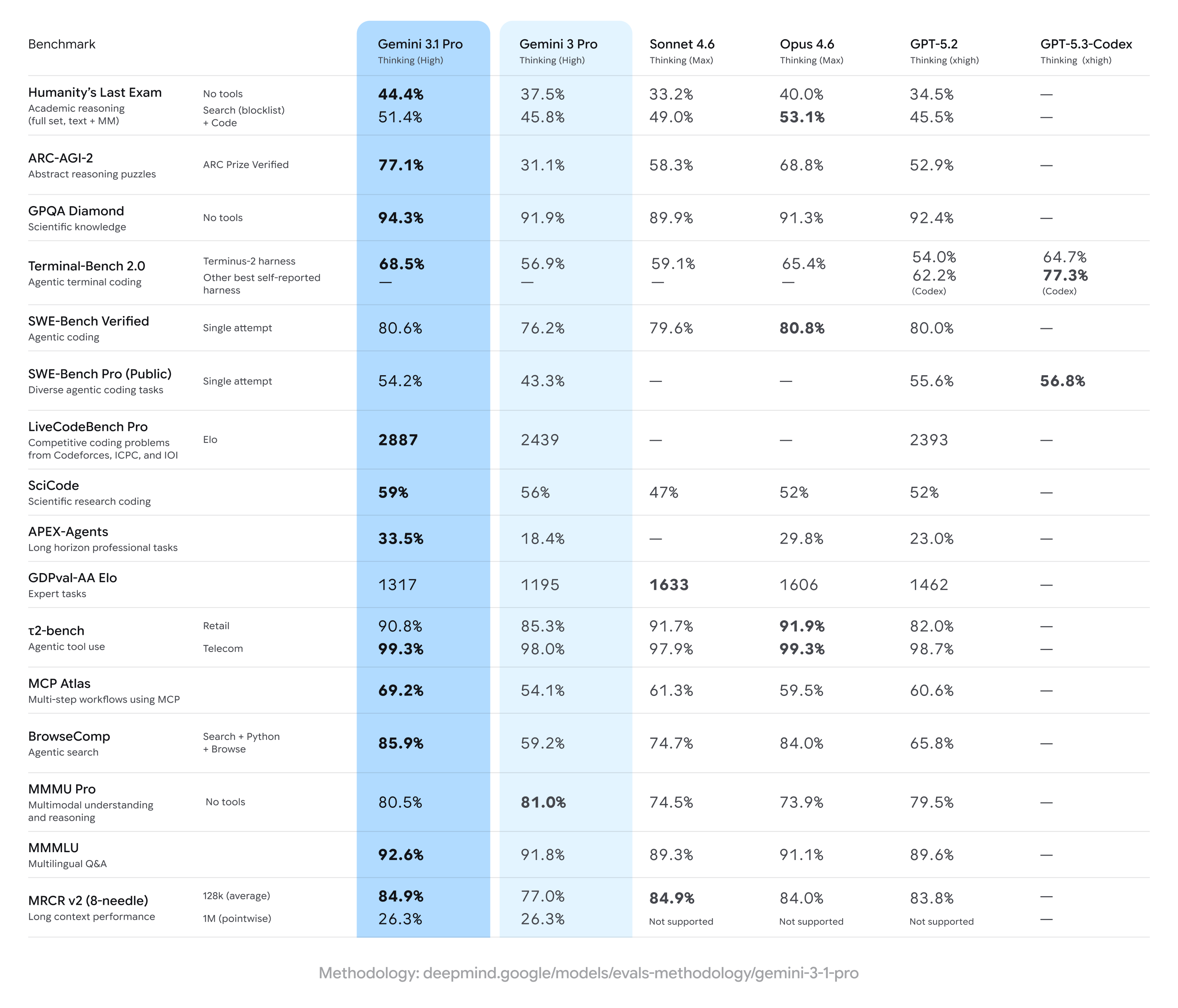
- ARC-AGI-2 (raisonnement abstrait / casse-têtes scientifiques multi-étapes) : Les hausses rapportées pour Gemini 3.1 Pro montrent une amélioration substantielle par rapport aux versions précédentes de Gemini 3 Pro ; une batterie de tests communautaires a indiqué une amélioration de plus du double sur ARC-AGI-2 par rapport au référentiel Gemini 3 Pro précédent, lors de tests courts et ciblés. Des scores spécifiques rapportés (tests communautaires) placent Gemini 3.1 Pro à environ 77.1% sur certaines agrégations de type ARC (reporting public).
- GPQA Diamond et benchmarks scientifiques de niveau master/doctorat : Les données indiquent que Gemini 3.1 Pro a atteint des records sur GPQA Diamond (benchmark de QA scientifique de niveau graduate), dépassant les modèles Gemini antérieurs et établissant un nouveau niveau pour la famille lors d’exécutions indépendantes. Ces gains reflètent l’amélioration de la chaîne de pensée et de l’ajustement au raisonnement pas à pas du modèle.
- « Humanity’s Last Exam » avec outils activés (raisonnement multi-outils, ancré) : En comparaisons directes avec Claude Opus 4.6 d’Anthropic, Claude a atteint 53.1% sur ce benchmark complexe avec outils, tandis que Gemini 3.1 Pro a atteint 51.4% sur la même série de tests — montrant un Gemini très proche mais pas au sommet sur cet examen multi-outils particulier.
- Benchmarks de code et terminal (Terminal-Bench 2.0, SWE-Bench Pro) : Les benchmarks spécialisés en programmation ont montré davantage de divergence. Sur Terminal-Bench 2.0 avec des harnais spécifiques, les variantes GPT-5.3-Codex ont obtenu environ 77.3% contre ~68.5% pour Gemini 3.1 Pro dans les mêmes comparaisons. Sur SWE-Bench Pro (résultats publics), Gemini 3.1 Pro a atteint ~54.2% contre 56.8% pour GPT-5.3-Codex — plus serré, mais la famille Codex d’OpenAI garde un avantage sur des tâches de programmation spécialisées dans ces exécutions.
- GDPval-AA Elo (notation de tâches expertes) : Dans un classement agrégé de type Elo pour des tâches expertes, les variantes Claude Sonnet/Opus ont obtenu des scores plus élevés (p. ex., ~1606–1633 points), tandis qu’un rapport public a placé Gemini 3.1 Pro à ~1317 points sur ce même jeu de données — indiquant des marges de progression sur certains domaines experts étroits.
Résultats d’essais en conditions réelles et tests pratiques
Les retours d’analystes montrent que Gemini 3.1 Pro excelle particulièrement en :
- Synthèse de long contexte et synthèse multi-documents, où la fenêtre de 1M de tokens évite les artefacts de découpage.
- Tâches de compréhension multimodale où l’ancrage image + texte améliore l’extraction factuelle.
- Automatisation agentique (p. ex., coordination de chaînes d’outils simples) — avec des essais Antigravity montrant que l’orchestration multi-agents est réalisable avec des artefacts enregistrant chaque étape.
Où Gemini 3.1 Pro reste en retrait (ce que disent les chiffres)
Aucun modèle n’est uniformément meilleur. Des commentaires indépendants et des tests communautaires mettent en lumière des lacunes spécifiques :
- Benchmarks d’ingénierie logicielle et de maintenance de code (SWE-Bench Pro et similaires) — Gemini 3.1 Pro derrière un concurrent (Claude Opus 4.6 d’Anthropic) sur des tâches testant des capacités d’ingénierie logicielle pratiques : refactorings à grande échelle, triage de bugs dans des bases de code désordonnées et certains types de réparation automatique de programmes. En d’autres termes, pour la maintenance au quotidien, des modèles spécialisés conservent un avantage sur certains bancs d’essai.
- Micro-tâches sensibles à la latence — parce que Gemini 3.1 Pro est ajusté pour la profondeur, les tâches nécessitant une latence ultra-faible et un débit élevé (p. ex., micro-inférence pour des interfaces conversationnelles légères) peuvent être mieux servies par « Flash » ou d’autres variantes optimisées de la famille Gemini.
Quel est le prix de Gemini 3.1 Pro ?
Vous pouvez accéder à Gemini 3.1 Pro de deux façons — abonnement grand public ou API développeur — et la tarification diffère pour chacune.
- Grand public (application Gemini / Google AI Pro) : L’accès à Gemini 3.1 Pro est inclus dans l’abonnement Google AI Pro, qui, aux États-Unis, est à $19.99 / mois (Google propose également un palier « AI Plus » moins cher et un palier « AI Ultra » plus élevé). Google.
- Développeur / API (au jeton) : Si vous appelez les modèles Gemini via l’API développeur Gemini/AI, la tarification est mesurée en tokens. Pour la préversion Gemini 3.x Pro, les prix développeur publiés sont approximativement : $2.00 par 1M de jetons d’entrée et $12.00 par 1M de jetons de sortie pour la tranche standard (≤200k prompts) — avec des paliers plus élevés (p. ex. $4/$18 par 1M) pour des contextes très larges. (Voir le tableau des tarifs de l’API Gemini pour tous les détails et la tarification par lots.)
- Si vous utilisez Gemini 3.1 Pro via CometAPI :
| Prix Comet (USD / M jetons) | Prix officiel (USD / M jetons) |
|---|---|
| Entrée:$1.6/M; Sortie:$9.6/M | Entrée:$2/M; Sortie:$12/M |
Tarification des abonnements grand public (application Gemini)
Pour les offres utilisateur final dans l’application Gemini, Google structure des paliers qui conditionnent l’accès aux variantes de modèle et à des fonctionnalités supplémentaires : Google AI Pro et Google AI Ultra. Les prix varient selon le marché et la devise ; des exemples publiés montrent Google AI Pro à $19.99/mois (avec des essais promotionnels disponibles), et une tarification par devise est indiquée sur la page produit (incluant des offres d’essai et des tarifs réduits de courte durée). AI Ultra inclut un accès supérieur (p. ex., accès prioritaire aux nouvelles innovations, crédits plus élevés pour la génération vidéo) à un tarif mensuel plus élevé. Ces plans grand public se veulent compétitifs face aux autres abonnements IA haut de gamme et visent à donner aux utilisateurs avancés individuels ou petites équipes l’accès aux fonctionnalités de 3.1 Pro sans intégration API.
Conseils pratiques de prompt et d’usage (ce que je ferais)
Utilisez ces approches pour des résultats fiables et répétables :
- Planificateur explicite en étapes
Modèle de prompt :1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.Cela exploite la meilleure exécution pas à pas de 3.1 Pro et vous donne des points de contrôle. - Sorties structurées avec schémas
Demandez du JSON avec un schéma etstrict: true. Comme 3.1 Pro produit des sorties longues et conformes au schéma plus régulièrement, vous obtiendrez de grandes réponses uniques que vous pourrez analyser en aval. - « Sandwich » de vérification d’outil
Lors de l’appel d’outils externes (API, exécuteurs de code), demandez au modèle de produire : plan → appel d’outil exact (copiable/collable) → étapes de validation. Puis vérifiez les étapes de validation en dehors du modèle avant de continuer. - Attention à la confiance en une seule étape
Même si le modèle écrit du code ou des commandes qui paraissent parfaits, exécutez une validation indépendante (tests, linters, exécution en bac à sable) — surtout pour des actions agentiques/autonomes.
Prise en main de Gemini 3.1 Pro
Cas d’essai 1 : Assistant de recherche en long contexte (NotebookLM / Deep Research)
Objectif : Évaluer la capacité du modèle à synthétiser 10–50 documents longs (rapports, livres blancs) en un résumé exécutif multi-pages avec citations et actions recommandées.
Configuration : Fournir un corpus totalisant 200k–800k tokens ; demander au modèle de produire un résumé de 2–4 pages avec citations explicites et recommandations de « prochaines étapes ». Utiliser un modèle de prompt reproductible et mesurer le temps, l’usage de tokens (coût) et l’exactitude factuelle.
Résultats : Une synthèse de bout en bout plus rapide avec moins d’artefacts de découpage par rapport à des modèles plus anciens, une fidélité des citations plus élevée dans le résumé, et une meilleure cohérence à l’échelle — au prix d’une consommation de tokens significative (prévoyez le budget). Les benchmarks et tests pratiques montrent que Gemini 3.1 Pro excelle en synthèse multi-documents grâce à la fenêtre de 1M de tokens.
Cas d’essai 2 : Assistant de codage agentique (Antigravity + GitHub Copilot)
Objectif : Mesurer la réduction du temps de réalisation pour des tâches développeur multi-étapes (p. ex., implémenter une fonctionnalité sur plusieurs fichiers, exécuter les tests, corriger les tests défaillants).
Configuration : Utiliser Antigravity ou GitHub Copilot en préversion avec Gemini 3.1 Pro sélectionné. Définir des tâches reproductibles (création d’issue → implémentation → exécution des tests), consigner les étapes et les artefacts d’agent, et comparer à une base humaine seule.
Résultats : Meilleure orchestration des tâches multi-étapes (enregistrement d’artefacts, suggestion automatique de correctifs), meilleur raisonnement multi-fichiers que le précédent Gemini 3 Pro, et gains de temps mesurables sur les travaux de fonctionnalité de routine. Les tâches spécialisées de débogage bas niveau peuvent toutefois rester à l’avantage de modèles spécialisés orientés code (des résultats communautaires montrent un écart vs certaines variantes GPT-Codex sur des benchmarks de terminal).
Cas d’essai 3 : Revue de documents juridiques/médicaux multimodale
Objectif : Utiliser le modèle pour ingérer un corpus mixte (PDF scannés, images, transcriptions audio), extraire les faits clés et produire une matrice de risques et des actions prioritaires.
Configuration : Fournir un jeu de données avec des images scannées et du texte OCR, plus de l’audio de support. Mesurer la précision d’extraction des entités nommées, le taux de faux positifs et la capacité du modèle à référencer les artefacts source.
Résultats : Un raisonnement plus intégré entre modalités et des sorties plus traçables (capacité à pointer vers l’image / la page / l’horodatage audio qui sous-tend une affirmation). La longue fenêtre de contexte réduit le besoin de découpage manuel et de recoupement. Cependant, dans les domaines réglementés, les sorties doivent être validées par des experts du domaine et un pipeline d’ancrage/vérification doit être utilisé.
Premières impressions (ce qui change)
- Un raisonnement pas à pas plus profond. Des tâches qui nécessitaient auparavant plusieurs allers-retours — p. ex., synthèse multi-documents, math/logic multi-étapes — ont tendance à se conclure en moins de passes et avec des sorties au style de chaîne de pensée plus clair (sans exposer de texte d’instruction interne). C’est le point central mis en avant par Google.
- Des sorties structurées plus longues et de meilleure qualité. Le JSON et les automatisations long format sont plus cohérents et souvent beaucoup plus longs (certains utilisateurs ont signalé des tailles de sortie bien supérieures à 3.0). C’est idéal pour des tâches de génération où vous voulez une charge utile unique et volumineuse. Attendez-vous à gérer des sorties plus grandes et du streaming.
- Une gestion plus efficace des tokens / du contexte. Une efficacité en tokens améliorée et un comportement plus « ancré, factuellement cohérent » dans les scénarios utilisant des outils. Cela se traduit par moins d’hallucinations sur des recherches factuelles courtes.
Analyse finale : Faut-il adopter Gemini 3.1 Pro dès maintenant ?
Gemini 3.1 Pro représente un progrès significatif dans la famille Gemini, avec des améliorations démontrables sur les benchmarks de raisonnement, de codage et agentiques — appuyées par la model card publiée par Google et des suivis indépendants signalant de grands bonds sur certains classements. Pour les équipes ayant besoin d’un raisonnement avancé, de coordination d’outils agentiques ou de capacités multimodales à long contexte, 3.1 Pro est une option convaincante.
Les développeurs peuvent accéder à Gemini 3.1 Pro via CometAPI dès maintenant. Pour commencer, explorez les capacités du modèle dans le Playground et consultez le guide de l’API pour des instructions détaillées. Avant d’accéder, veuillez vous assurer que vous êtes connecté à CometAPI et que vous avez obtenu la clé API. CometAPI propose un prix bien inférieur au tarif officiel pour faciliter votre intégration.
Prêt à démarrer ? → Inscrivez-vous à Gemini 3.1 Pro dès aujourd’hui !
Si vous souhaitez découvrir plus de conseils, guides et actualités sur l’IA, suivez-nous sur VK, X et Discord !