

GLM-4.6 est la dernière version majeure de la famille GLM de Z.ai (anciennement Zhipu AI) : une 4e génération, en grand langage Modèle MoE (mélange d'experts) réglé pour flux de travail agentiques, raisonnement à long contexte et codage du monde réel. La version met l'accent sur l'intégration pratique des agents/outils, une très grande fenêtre contextuelle, et une disponibilité en poids ouvert pour un déploiement local.
Fonctionnalités
- Contexte long - indigène Jeton 200K Fenêtre contextuelle (étendue de 128 Ko). ()
- Codage et capacité d'agent — des améliorations commercialisées sur les tâches de codage du monde réel et une meilleure invocation d'outils pour les agents.
- Efficacité — signalé Consommation de jetons inférieure d'environ 30 % vs GLM-4.5 sur les tests de Z.ai.
- Déploiement et quantification — première intégration annoncée de FP8 et Int4 pour les puces Cambricon ; prise en charge native de FP8 sur Moore Threads via vLLM.
- Taille du modèle et type de tenseur — les artefacts publiés indiquent une ~357B-paramètre modèle (tenseurs BF16/F32) sur Hugging Face.
Détails techniques
Modalités et formats. GLM-4.6 est un texte seulement LLM (modalités d'entrée et de sortie : texte). Longueur du contexte = 200 000 jetons; sortie maximale = 128 000 jetons.
Quantification et support matériel. L'équipe rapporte Quantification FP8/Int4 sur les puces Cambricon et FP8 natif exécution sur les GPU Moore Threads à l'aide de vLLM pour l'inférence — important pour réduire les coûts d'inférence et permettre les déploiements sur site et dans le cloud domestique.
Outillage et intégrations. GLM-4.6 est distribué via l'API de Z.ai, les réseaux de fournisseurs tiers (par exemple, CometAPI) et intégré dans les agents de codage (Claude Code, Cline, Roo Code, Kilo Code).
Détails techniques
Modalités et formats. GLM-4.6 est un texte seulement LLM (modalités d'entrée et de sortie : texte). Longueur du contexte = 200 000 jetons; sortie maximale = 128 000 jetons.
Quantification et support matériel. L'équipe rapporte Quantification FP8/Int4 sur les puces Cambricon et FP8 natif exécution sur les GPU Moore Threads à l'aide de vLLM pour l'inférence — important pour réduire les coûts d'inférence et permettre les déploiements sur site et dans le cloud domestique.
Outillage et intégrations. GLM-4.6 est distribué via l'API de Z.ai, les réseaux de fournisseurs tiers (par exemple, CometAPI) et intégré dans les agents de codage (Claude Code, Cline, Roo Code, Kilo Code).
Performances de référence
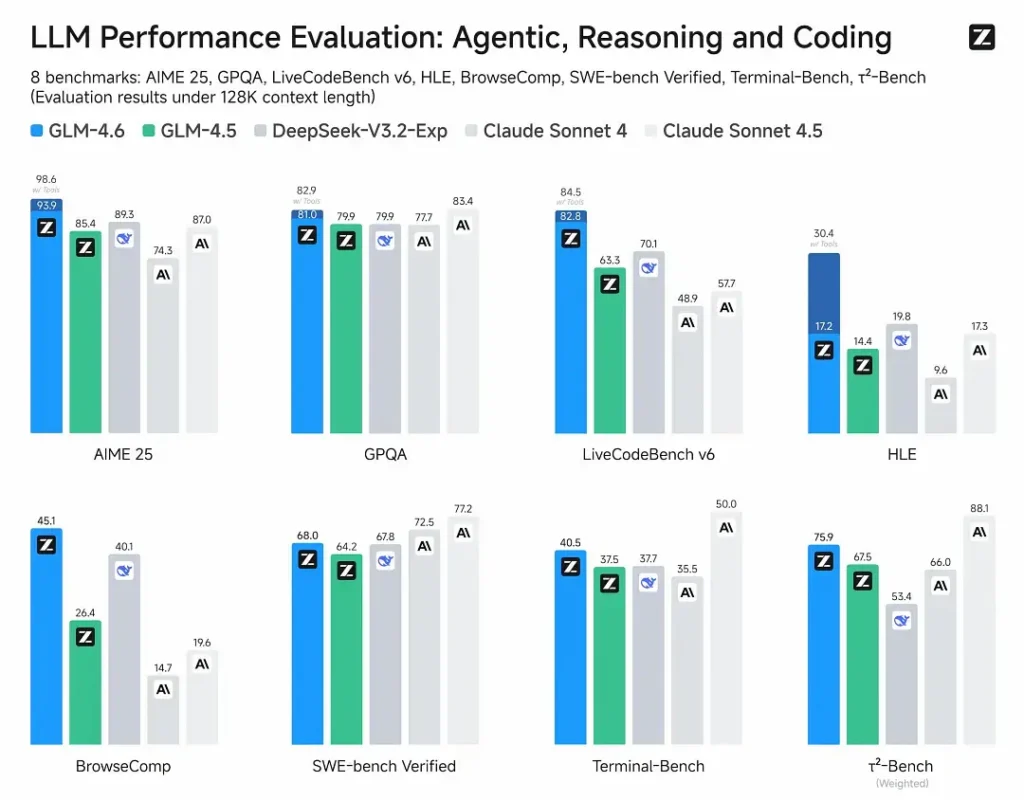
- Évaluations publiées : GLM-4.6 a été testé sur huit benchmarks publics couvrant les agents, le raisonnement et le codage et montre gains nets par rapport à GLM-4.5. Lors de tests de codage réels évalués par des humains (CC-Bench étendu), GLM-4.6 utilise ~15 % de jetons en moins vs GLM-4.5 et publie un ~48.6 % de taux de réussite contre Anthropic Claude Sonnet 4 (quasi-parité dans de nombreux classements).
- Positionnement: les résultats indiquent que GLM-4.6 est compétitif avec les principaux modèles nationaux et internationaux (les exemples cités incluent DeepSeek-V3.1 et Claude Sonnet 4).
Limites et risques
- Hallucinations et erreurs : Comme tous les LLM actuels, GLM-4.6 peut commettre des erreurs factuelles, et en fait. La documentation de Z.ai prévient explicitement que les résultats peuvent contenir des erreurs. Les utilisateurs doivent appliquer la vérification et la récupération (RAG) pour le contenu critique.
- Complexité du modèle et coût de service : Un contexte de 200 000 et des sorties très volumineuses augmentent considérablement les exigences de mémoire et de latence et peuvent augmenter les coûts d'inférence ; une ingénierie quantifiée/d'inférence est nécessaire pour fonctionner à grande échelle.
- Lacunes du domaine : Bien que GLM-4.6 fasse état de solides performances en termes d'agent/codage, certains rapports publics indiquent qu'il retarde certaines versions des modèles concurrents dans des microbenchmarks spécifiques (par exemple, certaines mesures de codage par rapport à Sonnet 4.5). Évaluer chaque tâche avant de remplacer les modèles de production.
- Sécurité et politique : Les poids ouverts augmentent l'accessibilité mais soulèvent également des questions de gestion (les mesures d'atténuation, les garde-fous et le red-teaming restent de la responsabilité de l'utilisateur).
Cas d'usage
- Orchestration des systèmes agentiques et des outils : longues traces d'agent, planification multi-outils, invocation d'outils dynamiques ; le réglage agentique du modèle est un argument de vente clé.
- Assistants de codage du monde réel : génération de code multi-tours, révision de code et assistants IDE interactifs (intégrés dans Claude Code, Cline, Roo Code—par Z.ai). Améliorations de l'efficacité des jetons le rendre attractif pour les plans de développement à usage intensif.
- Flux de travail pour documents longs : résumé, synthèse multi-documents, longues revues juridiques/techniques en raison de la fenêtre de 200 000.
- Création de contenu et personnages virtuels : dialogues prolongés, maintien cohérent de la personnalité dans des scénarios à plusieurs tours.
Comparaison du GLM-4.6 avec les autres modèles
- GLM-4.5 → GLM-4.6 : changement radical dans taille du contexte (128 Ko → 200 Ko) et efficacité des jetons (~15 % de jetons en moins sur CC-Bench); utilisation améliorée des agents/outils.
- GLM-4.6 contre Claude Sonnet 4 / Sonnet 4.5 : Z.ai rapporte quasi-parité dans plusieurs classements et un taux de réussite d'environ 48.6 % aux tâches de codage concrètes du CC-Bench (soit une concurrence serrée, avec quelques microbenchmarks où Sonnet reste en tête). Pour de nombreuses équipes d'ingénierie, GLM-4.6 se positionne comme une alternative rentable.
- GLM-4.6 vs autres modèles à contexte long (DeepSeek, variantes Gemini, famille GPT-4) : GLM-4.6 met l'accent sur les workflows de codage à contexte large et agentique ; les avantages relatifs dépendent de métriques (efficacité des jetons/intégration des agents par rapport à la précision de la synthèse du code brut ou aux pipelines de sécurité). La sélection empirique doit être axée sur les tâches.
Sortie du dernier modèle phare de Zhipu AI, GLM-4.6 : 355 milliards de paramètres au total, dont 32 milliards de dollars actifs. Il surpasse GLM-4.5 dans toutes ses fonctionnalités principales.
- Codage : s'aligne avec Claude Sonnet 4, le meilleur en Chine.
- Contexte : Étendu à 200 000 (au lieu de 128 000).
- Raisonnement : amélioré, prend en charge l'appel d'outils pendant l'inférence.
- Recherche : Appel d'outils et performances de l'agent améliorés.
- Écriture : mieux adapté aux préférences humaines en termes de style, de lisibilité et de jeu de rôle.
- Multilingue : traduction multilingue optimisée.
Comment appeler GLM-**4.**6 API de CometAPI
GLM‑4.6 Tarification de l'API dans CometAPI, 20 % de réduction sur le prix officiel :
- Jetons d'entrée : 0.64 million de jetons
- Jetons de sortie : 2.56 $/M jetons
Étapes requises
- Se connecter à cometapi.comSi vous n'êtes pas encore notre utilisateur, veuillez d'abord vous inscrire.
- Connectez-vous à votre Console CometAPI.
- Obtenez la clé API d'accès à l'interface. Cliquez sur « Ajouter un jeton » au niveau du jeton API dans l'espace personnel, récupérez la clé : sk-xxxxx et validez.

Utiliser la méthode
- Sélectionnez l'option "
glm-4.6Point de terminaison pour envoyer la requête API et définir le corps de la requête. La méthode et le corps de la requête sont disponibles dans la documentation API de notre site web. Notre site web propose également le test Apifox pour plus de commodité. - Remplacer avec votre clé CometAPI réelle de votre compte.
- Insérez votre question ou demande dans le champ de contenu : c'est à cela que le modèle répondra.
- Traitez la réponse de l'API pour obtenir la réponse générée.
CometAPI fournit une API REST entièrement compatible, pour une migration fluide. Informations clés API doc:
- URL de base : https://api.cometapi.com/v1/chat/completions
- Noms de modèle: "
glm-4.6" - Authentification:
Bearer YOUR_CometAPI_API_KEYentête - Content-Type:
application/json.
Intégration et exemples d'API
Voici une Python Extrait montrant comment invoquer GLM-4.6 via l'API CometAPI. Remplacer <API_KEY> et <PROMPT> en conséquence:
import requests
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = {
"Authorization": "Bearer <API_KEY>",
"Content-Type": "application/json"
}
payload = {
"model": "glm-4.6",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "<PROMPT>"}
],
"max_tokens": 512,
"temperature": 0.7
}
response = requests.post(API_URL, json=payload, headers=headers)
print(response.json())
Paramètres clés:
- modèle: Spécifie la variante GLM‑4.6
- max_tokens: Contrôle la longueur de sortie
- la réactivité:Ajuste la créativité par rapport au déterminisme
Voir aussi
Claude Sonnet 4.5