

Google DeepMind a annoncé aujourd'hui des extensions significatives de sa famille Gemini 2.5, dévoilant les versions stables de Gemini 2.5 Pro et Gemini 2.5 Flash, ainsi qu'un aperçu du tout nouveau modèle Gemini 2.5 Flash‑Lite. Ces mises à jour reflètent l'engagement continu de Google à proposer une gamme de modèles d'IA offrant un équilibre optimal entre coût, rapidité et performances pour diverses charges de travail.
Versions stables : Gemini 2.5 Pro et Flash
Le 17 juin 2025, Google a annoncé la disponibilité générale de Gemini 2.5 Pro et Gemini 2.5 Flash. La version Pro offre une puissance de raisonnement maximale et est conçue pour les tâches très complexes telles que la génération de code avancée, l'analyse scientifique et la synthèse de données à grande échelle. En revanche, Gemini 2.5 Flash offre une option intermédiaire optimisée pour les utilisations quotidiennes exigeant une faible latence, idéale pour les chatbots, la synthèse et la création de contenu à grande échelle.
Présentation : trois modèles de la famille Gemini-2.5
| Modèle | Statut | Points forts | Cas d'utilisation idéaux |
|---|---|---|---|
| Gemini 2.5 Flash‑Lite (Aperçu) | Aperçu | Le plus rapide et le moins cher ; multimodal ; raisonnement contrôlable ; activé par des outils | Tâches à volume élevé comme les chatbots, le résumé, la recherche |
| Gemini 2.5 Flash | Stable | Équilibré : faible latence, bon raisonnement, multimodal | Conversations en temps réel, support client |
| Gemini 2.5 Pro | Stable | Le plus capable : raisonnement profond, contexte vaste, multimodal | Recherche, codage complexe, tâches scientifiques |
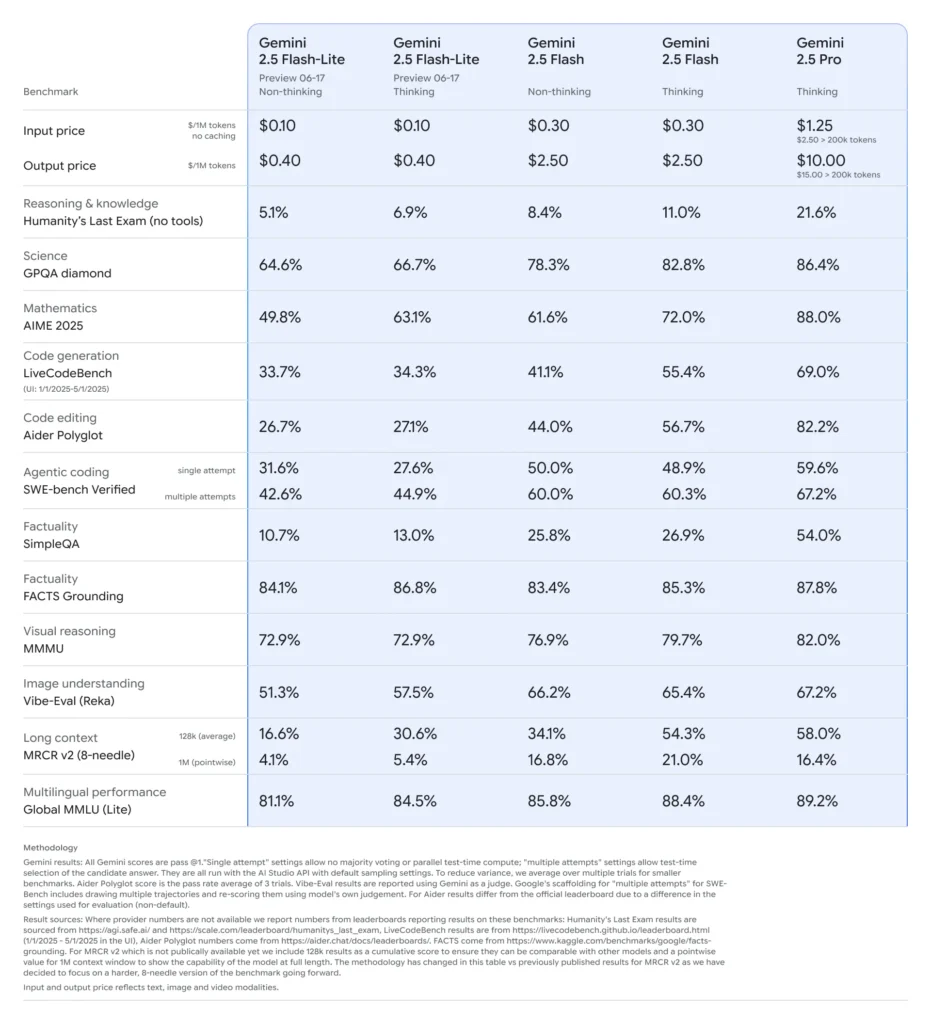
Gemini 2.5 Flash‑Lite : Aperçu des points forts
Latence ultra-faible et économies de coûtsConçu pour les applications à volume élevé et en temps réel, telles que la traduction, la classification et la synthèse. Il offre une inférence plus rapide et un coût par appel inférieur à celui de Flash‑Lite 2.0 et de la version Flash complète.
Amélioration des performances fondamentales:Surpasse les modèles Flash-Lite précédents dans les tests de génération de code, de logique, de mathématiques, de raisonnement multimodal et de sciences.
Coût et efficacité: Tarification Flash‑Lite (aperçu) : environ 0.10 $ par 1 M de jetons d'entrée et environ 0.40 $ par 1 M de jetons de sortie, soit nettement moins cher que Flash (0.30 $/2.50 $) et Pro (1.25 $/10 $).
Fonctionnalités complètes de Gemini -2.5 :
- Pensée contrôlable:Les utilisateurs peuvent définir des « budgets de réflexion » (limites de jetons) pour échanger la vitesse contre la profondeur. Flash‑Lite peut activer cette option selon les besoins.
- Entrée multimodale: Prend en charge le texte, l'image, l'audio et la vidéo (y compris les clips d'une heure), avec des capacités d'analyse des graphiques, de l'interface utilisateur, des scènes et des résumés d'événements.
- Intégration d'outil: Inclut la recherche Google, l'exécution de code et une fenêtre de contexte d'un million de jetons, correspondant aux capacités de Flash et Pro.
Positionnement sur la courbe prix-performance
Google positionne la vitesse élevée et le faible coût de Flash-Lite au premier rang Frontière de Pareto, ce qui signifie qu'il figure parmi les modèles les plus économiques et performants au monde (). Lors d'évaluations comparatives, Flash‑Lite représente le meilleur rapport qualité-prix: intelligent mais abordable.
À propos de Flash et Pro
- Gemini 2.5 Flash: Modèle de réflexion multimodal stable et à faible latence. Positionné en dessous de Pro, mais à peu près au même niveau que GPT-4o en termes de capacités, avec une vitesse et une rentabilité supérieures ().
- Gemini 2.5 Pro: Le modèle le plus avancé de Google. Réputé pour gérer des vidéos et des fichiers audio de plusieurs heures, du code et des mathématiques complexes, ainsi que des raisonnements en contexte étendu. Il introduit également des « budgets de réflexion » sélectifs et une qualité de code améliorée pour servir d'IA phare stable à long terme.
Déploiement et tarification
- Disponibilité:Les trois modèles sont accessibles via Google IA Studio, Google Cloud Vertex IAainsi que, Application Gémeaux .
- La structure des coûts (Tarifs Vertex AI à partir du 16 juin 2025) :
- Pro: $1.25/1M d'entrée, $10/1M de sortie (plus élevé au-delà de 200 XNUMX jetons)
- Flash: 0.15 $/1 M d'entrée, 3.50 $/1 M de sortie en mode « réflexion » — et comprend 1,500 8 invites ancrées gratuites par jour ()
- Flash‑Lite (aperçu) : ~$0.10/$0.40 pour 1 M de jetons
Pour commencer
CometAPI fournit une interface REST unifiée qui regroupe des centaines de modèles d'IA sous un point de terminaison cohérent, avec gestion intégrée des clés API, des quotas d'utilisation et des tableaux de bord de facturation. Plus besoin de jongler avec plusieurs URL et identifiants de fournisseurs.
Les développeurs peuvent accéder API Gemini 2.5 Flash-Lite (aperçu) à travers API CometLes derniers modèles listés sont ceux en vigueur à la date de publication de l'article. Pour commencer, explorez les fonctionnalités du modèle dans la section cour de récréation et consultez le Guide de l'API Pour des instructions détaillées, veuillez vous connecter à CometAPI et obtenir la clé API avant d'y accéder. API Comet proposer un prix bien inférieur au prix officiel pour vous aider à vous intégrer.