

Le 3 mars 2026, Google a présenté Gemini 3.1 Flash-Lite, le nouveau membre de la famille Gemini 3, conçu spécifiquement comme un moteur à haut débit, faible latence et rentable pour les charges de travail des développeurs et des entreprises. Google positionne Flash-Lite comme le modèle “le plus rapide et le plus économique” de la gamme Gemini 3 : une variante allégée qui vise à offrir des interactions en streaming, un traitement en arrière-plan à grande échelle et des tâches de production à haute fréquence (par exemple, traduction, extraction, génération d’interface utilisateur et classification à grand volume) à un prix bien inférieur à celui de ses homologues Pro.
Ci-dessous, nous détaillons ce qu’est Flash-Lite.
Qu’est-ce que Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite est un membre de la famille Gemini 3 de Google qui troque volontairement une partie de la profondeur de raisonnement de niveau supérieur contre la vitesse et l’efficacité des coûts. Il est nativement multimodal dans la lignée Gemini (capable d’accepter du texte, des images et d’autres modalités en entrée), mais est ajusté et déployé spécifiquement pour offrir un débit maximal en tokens par seconde et une facturation par jeton sensiblement plus faible pour les charges de travail nécessitant des inférences rapides et répétées plutôt qu’une profondeur cognitive maximale. Le modèle est décrit comme dérivé de l’architecture 3.1 Pro, mais optimisé pour le débit, la latence et le coût.
Principaux arbitrages de conception
Le qualificatif “Lite” signale l’accent mis par l’ingénierie du modèle :
- Débit plutôt que raisonnement lourd : Flash-Lite réduit intentionnellement le calcul par jeton afin d’offrir un meilleur Time-to-First-Token (TTFT) et une vitesse de sortie continue. Cela le rend idéal pour des pipelines où chaque requête doit être servie rapidement et à grande échelle (par ex. filtres de sécurité, assistants en temps réel, génération à haut volume).
- Efficacité des coûts pour des volumes élevés : En abaissant le calcul par jeton, le modèle peut être proposé à des prix plus bas par million de jetons, ce qui réduit le coût marginal dans les applications à grande échelle (par ex. de millions à des milliards de jetons par mois). Les tarifs de préversion de Google montrent un écart significatif par rapport au niveau Pro.
- Qualité ajustée pour des tâches pragmatiques : Selon les premiers résumés de scores, Flash-Lite conserve de bons résultats sur les tâches standard de classification, de multilinguisme et de nombreuses tâches multimodales, mais il n’est pas positionné pour battre Pro sur les benchmarks les plus complexes de raisonnement multi-étapes ou de génération de code où la profondeur compte.
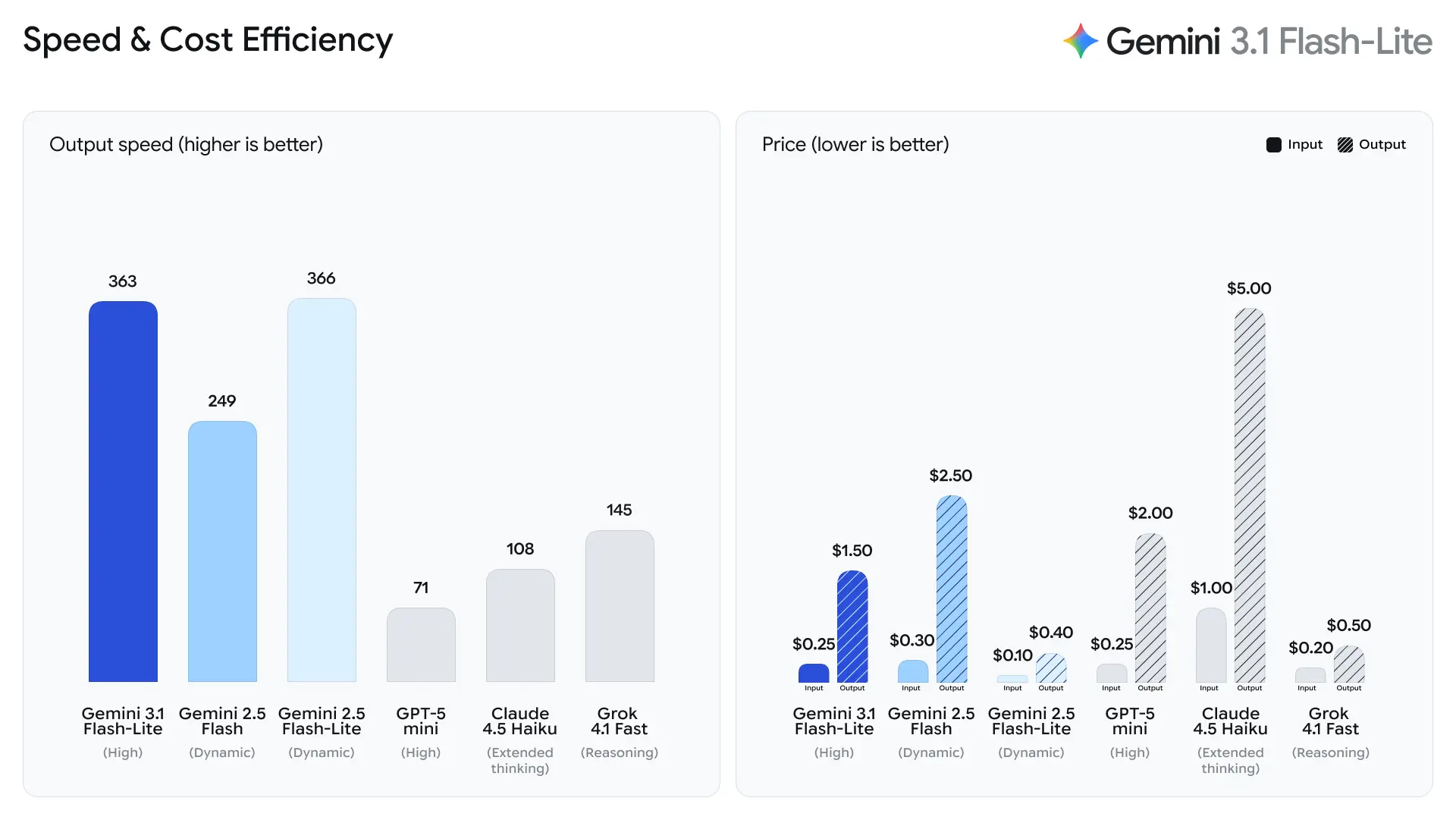
Ces charges de travail exigent une sortie fiable et un haut débit, sans toujours nécessiter les capacités de raisonnement multi-étapes complexes des modèles phares.
Fonctionnalités clés de Gemini 3.1 Flash-Lite
1. Faible latence et temps d’apparition du premier jeton rapide
Google met en avant le time-to-first-answer token comme métrique principale pour Flash-Lite. L’entreprise indique un ~2.5× temps jusqu’au premier jeton plus rapide par rapport à Gemini 2.5 Flash et jusqu’à 45 % de génération de sortie plus rapide — des améliorations qui impactent directement la réactivité perçue par les utilisateurs finaux et les coûts de débit pour les systèmes back-end. Ces gains rendent Flash-Lite particulièrement adapté aux fonctionnalités interactives (par ex. chatbots intégrés aux applications) et aux pipelines à QPS élevé où les microsecondes comptent.
Cette amélioration renforce significativement les applications en temps réel telles que :
- l’IA conversationnelle
- les assistants de recherche alimentés par l’IA
- les chatbots interactifs
- les services de traduction en direct
Une latence plus faible améliore l’expérience utilisateur en réduisant le temps d’attente et en permettant des interactions plus fluides.
2. Tarification des jetons économique
Les coûts d’inférence en IA sont souvent calculés par jeton, ce qui fait de la tarification un facteur critique pour les déploiements à grande échelle.
Gemini 3.1 Flash-Lite introduit une structure tarifaire très compétitive :
| Type de jeton | Prix |
|---|---|
| Jetons d’entrée | $0.25 per 1M tokens |
| Jetons de sortie | $1.50 per 1M tokens |
Cela représente une réduction par rapport aux modèles Flash précédents, rendant le modèle attractif pour les organisations opérant de grandes charges.
À titre de comparaison :
| Modèle | Prix d’entrée | Prix de sortie |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
Cette stratégie tarifaire permet aux développeurs d’exécuter l’IA à l’échelle sans augmenter drastiquement les coûts opérationnels.
Si vous recherchez un prix encore meilleur, alors Gemini Flash-Lite propose une remise de 20 % sur CometAPI.
3. “Niveaux de réflexion” (profondeur d’inférence contrôlable)
Gemini 3.1 Flash-Lite inclut la fonctionnalité “niveaux de réflexion” — un réglage configurable par le développeur qui indique au modèle de privilégier un traitement plus rapide et plus superficiel pour les tâches triviales et un raisonnement plus profond pour les tâches difficiles. C’est important en pratique car cela permet des compromis dynamiques coût/latence par requête sans changer de modèle.
Les développeurs peuvent configurer la profondeur de raisonnement du modèle en fonction de la complexité de la tâche. Niveaux de réflexion : prend en charge quatre niveaux : Minimal, Low, Medium et High.
Cette approche dynamique permet aux applications d’optimiser l’utilisation des ressources tout en maintenant la qualité là où elle est nécessaire. La stratégie pratique est la suivante :
- Minimal/Low : Convient aux tâches à forte concurrence mais logiquement simples, telles que la traduction, la classification et l’analyse de sentiments, en privilégiant la vitesse maximale et le coût minimal.
- Medium : Convient à la plupart des tâches de production, offrant un équilibre entre qualité et efficacité.
- High : Convient aux tâches nécessitant un raisonnement profond, telles que la génération d’interfaces utilisateur, la création de simulations et l’exécution d’instructions complexes.
4. Capacités multimodales avec une empreinte légère
Bien que Flash-Lite soit optimisé pour la vitesse et le coût, il conserve les fondations multimodales de la gamme Gemini 3 : il peut accepter des entrées image pour la classification ou un raisonnement multimodal léger lorsque le cas d’usage le requiert — mais les développeurs doivent s’attendre à ce que la conception économique privilégie des opérations multimodales courtes et bornées plutôt que des workflows très lourds en images. Comme les autres modèles Gemini, Gemini 3.1 Flash-Lite prend en charge les entrées multimodales, permettant aux développeurs de traiter différents types de données.
Les entrées prises en charge incluent :
- Texte
- Images
- Vidéo
- Audio
La capacité du modèle à analyser plusieurs types d’informations permet de nouveaux cas d’usage, tels que :
- le traitement automatisé de documents
- l’extraction de données visuelles
- la synthèse multimédia
Les modèles Gemini précédents ont également démontré de solides capacités de raisonnement multimodal sur des benchmarks visuels et de connaissances.
Indicateurs de performance — des chiffres concrets et ce qu’ils signifient
L’annonce de Google et la documentation produit présentent plusieurs points de données de benchmark destinés à aider les acheteurs à comprendre où se situe Flash-Lite dans l’écosystème.
Indicateurs de vitesse orientés développeurs
- 2.5× plus rapide pour le premier jeton de réponse vs Gemini 2.5 Flash (comparaison interne annoncée par Google).
- 45 % de génération de sortie plus rapide vs Gemini 2.5 Flash.
Il s’agit d’indicateurs d’ingénierie des performances plutôt que de mesures de qualité évaluées par des humains ; ils reflètent des améliorations de la microarchitecture d’exécution, du batching et des optimisations de la pile d’inférence qui réduisent la latence pour les réponses courtes. Des temps plus rapides pour le premier jeton réduisent le décalage perçu dans les applications interactives et augmentent le débit par serveur, ce qui peut réduire le coût total de calcul pour un même QPS.
Jetons par seconde (t/s) et débit
Selon les données de test d’Artificial Analysis, le 3.1 Flash-Lite a atteint une vitesse de sortie de 388.8 jetons par seconde (la médiane des modèles dans la même gamme de prix n’est que de 96.7 jetons/seconde). Cette vitesse est de premier plan parmi les modèles de sa catégorie.
Cependant, Artificial Analysis a également souligné un problème : la latence du premier jeton (TTFT) du 3.1 Flash-Lite est de 5.18 secondes, ce qui est relativement élevé pour les modèles d’inférence dans la même gamme de prix (la médiane est de 1.82 seconde). De plus, le modèle a généré 53 millions de jetons lors du processus d’évaluation, ce qui est relativement élevé par rapport à la moyenne de 20 millions. Cela signifie que si votre scénario est très sensible à la latence du premier jeton ou a des exigences strictes en matière de concision de sortie, vous devrez peut-être optimiser le niveau de réflexion et les prompts.
Scores de référence pour le raisonnement et la factualité
Google a inclus des comparaisons inter-modèles montrant que Gemini 3.1 Flash-Lite offre de solides performances par rapport à ses pairs et aux précédentes variantes Gemini sur des tâches agrégées de raisonnement/factualité :
- Score Elo Arena.ai : Gemini 3.1 Flash-Lite aurait atteint un Elo de 1432 sur le classement d’évaluation Arena — un classement composite en confrontation directe montrant une performance relative compétitive dans des scénarios face à face.
- GPQA Diamond : 86.9 % (un indicateur de la robustesse en questions-réponses).
- MMMU Pro : 76.8 % (un indicateur multimodal/multitâche utilisé en interne/externe par certains laboratoires).
- LiveCodeBench (capacité de codage) : 72.0 %
- CharXiv Reasoning (raisonnement graphique) : 73.2 %
- Video-MMMU (compréhension vidéo) : 84.8 %
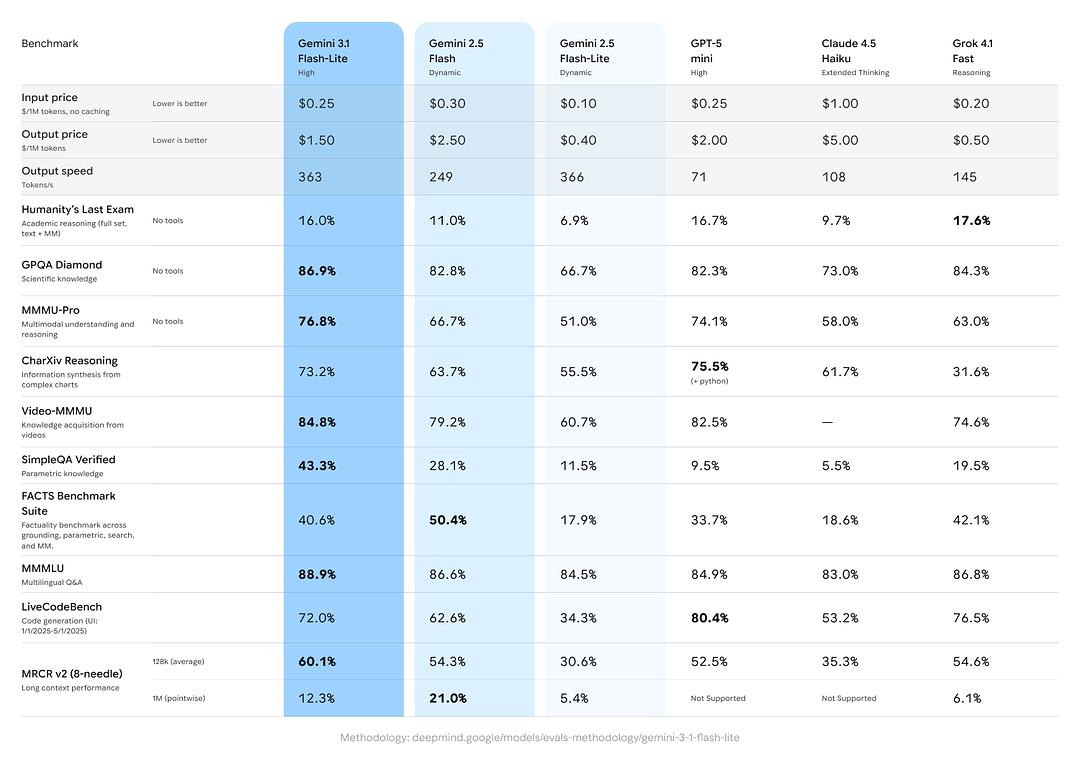
Gemini 3.1 Flash-Lite dépasse l’ancien Gemini 2.5 Flash sur plusieurs de ces métriques tout en offrant de bien meilleures performances en matière de vitesse/coût.
Cas d’usage adaptés à Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite est conçu autour d’un ensemble clair de charges de travail pratiques où le haut débit et le coût par jeton plus faible sont décisifs :
Agents conversationnels à haute fréquence et interfaces en streaming
Les chatbots en temps réel, les flux de transcription + traduction en direct et les interfaces collaboratives qui affichent des réponses partielles au fur et à mesure de la génération bénéficient de la sortie de jetons en streaming et du faible temps jusqu’au premier jeton de Flash-Lite.
Traitement de données en masse (RAG, pipelines de transformation)
Ingestion massive de documents : extraction d’entités, étiquetage de métadonnées, classification et traduction sur des millions de documents — Gemini 3.1 Flash-Lite réduit le coût d’inférence tout en offrant une précision acceptable pour des sorties normalisées ou régies par des règles.
Calcul de type edge ou en arrière-plan
Les charges de travail qui traitent en continu la télémétrie entrante ou des données non structurées (par ex. pipelines de classification pour la modération de contenu, génération de rapports automatisés) sont bien adaptées, car Gemini 3.1 Flash-Lite minimise le coût par unité.
Outils développeur et complétion de code par lots
Pour des fonctionnalités telles que le scaffolding multi-fichiers, le linting de code à grande échelle et la génération de modèles à l’échelle, les avantages de vitesse de Gemini 3.1 Flash-Lite réduisent la latence et le coût pour les outils destinés aux développeurs lorsque la profondeur de raisonnement maximale n’est pas indispensable.
Comparaison de Gemini 3.1 Flash-Lite avec les autres modèles Gemini et les concurrents
Au sein de la famille Gemini
- Gemini 3.1 Pro : la meilleure capacité en matière de raisonnement complexe et de planification multi-étapes ; sensiblement plus coûteux et plus lent par jeton, mais préférable pour les tâches profondes et nuancées.
- Gemini 3.1 Flash (non-Lite) : vise un juste milieu entre débit brut et capacité — Flash-Lite pousse encore plus loin l’optimisation de la pile de calcul pour le débit.
Par rapport aux modèles “rapides” concurrents
Gemini 3.1 Flash-Lite surpasse ou égale plusieurs modèles rapides/mini sur de nombreuses métriques de débit et de qualité — mais des analystes indépendants mettent en garde : les comparaisons directes dépendent de la méthodologie d’évaluation et du choix des jeux de données. Attendez-vous à ce que Gemini 3.1 Flash-Lite soit très compétitif en débit et en coût tout en restant dans la moyenne du classement sur les métriques de raisonnement les plus élevées.
Conclusion — la place de Flash-Lite dans la pile IA
Gemini 3.1 Flash-Lite est une offre conçue de manière délibérée : un membre de la famille Gemini 3 axé sur l’efficacité et le débit, qui permet aux équipes d’échanger une partie du calcul par exemple contre des améliorations spectaculaires de latence et de coût. Pour les entreprises et les développeurs construisant des pipelines à grand volume — traductions, traitements par lots, interfaces en streaming et tâches agentiques de complexité modérée — Flash-Lite constitue un moteur de base sensé. Pour les organisations nécessitant la fidélité de raisonnement la plus élevée, les modèles Pro restent le choix approprié.
Si votre charge de travail est dominée par de nombreuses inférences courtes et répétables ou si vous avez besoin d’une sortie en streaming rapide à grande échelle, Flash-Lite vaut la peine d’être testé. Si votre charge de travail repose sur un raisonnement multi-sauts profond, envisagez une approche hybride : orientez le trafic à haut débit vers Flash-Lite et escaladez les requêtes complexes et à forte valeur vers les modèles Pro.
Les développeurs peuvent accéder à Gemini 3.1 Flash Lite via CometAPI dès maintenant. Pour commencer, explorez les capacités du modèle dans le Playground et consultez le guide API pour des instructions détaillées. Avant d’y accéder, assurez-vous d’être connecté à CometAPI et d’avoir obtenu la clé API. CometAPI propose un prix bien inférieur au tarif officiel pour vous aider à intégrer.
Prêt à commencer ? → Inscrivez-vous à Gemini 3.1 Flash-Lite dès aujourd’hui !
Si vous souhaitez plus d’astuces, de guides et d’actualités sur l’IA, suivez-nous sur VK, X et Discord !