API audio GPT-4o : Un unifié /chat/completions extension de point de terminaison qui accepte les entrées audio (et texte) codées Opus et renvoie la parole synthétisée ou les transcriptions avec des paramètres configurables (modèle =gpt-4o-audio-preview-<date>, speed, temperature) pour les interactions vocales par lots et en streaming.
Informations de base sur le GPT-4o Audio
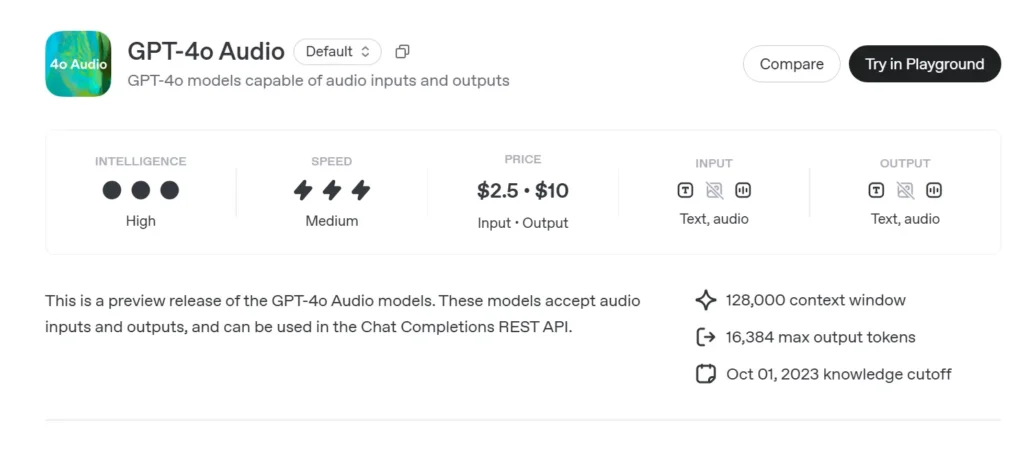
Aperçu audio du GPT-4o (gpt-4o-audio-preview-2025-06-03) est le plus récent d'OpenAI modèle de langage à grande échelle centré sur la parole rendu disponible via la norme API de complétion de chat plutôt que le canal temps réel à latence ultra-faible. Construite sur la même base « omni » que GPT-4o, cette variante est spécialisée dans entrée et sortie vocales haute fidélité Pour les conversations au tour par tour, la création de contenu, les outils d'accessibilité et les workflows agentiques ne nécessitant pas de délais de l'ordre de la milliseconde. Il hérite de toutes les capacités de raisonnement textuel des modèles de classe GPT-4, tout en y ajoutant parole à parole de bout en bout (S2S) pipelines, déterministes appel de fonction, Et la nouvelle speed paramètre pour le contrôle du débit vocal.
Ensemble de fonctionnalités de base du GPT-4o Audio
• Traitement unifié de la parole à la parole – L'audio est transformé directement en jetons sémantiquement riches, raisonné et resynthétisé sans services STT/TTS externes, ce qui donne timbre de voix cohérent, prosodie et rétention du contexte.
• Suivi des instructions amélioré – Le réglage de juin 2025 donne des résultats +19 pp passe-à-1 sur les tâches de commande vocale par rapport à la référence GPT-2024o de mai 4, réduisant les hallucinations dans des domaines tels que le support client et la rédaction de contenu.
• Appel d'outils stable – Les sorties du modèle JSON structuré qui est conforme au schéma d'appel de fonction OpenAI, permettant aux API backend (recherche, réservation, paiements) d'être déclenchées avec >95 % de précision des arguments.
• speed Paramètre (0.25–4×) – Les développeurs peuvent moduler la lecture vocale pour un apprentissage lent, une narration normale ou des modes rapides de « survol audible », sans resynthétiser le texte en externe.
• Prise de parole sensible aux interruptions – Bien que moins axé sur la latence que la variante en temps réel, l’aperçu prend en charge streaming partiel: les jetons sont émis dès qu'ils sont calculés, ce qui permet aux utilisateurs d'interrompre plus tôt si nécessaire.
Architecture technique du GPT-4o
• Transformateur à pile unique – Comme tous les dérivés de GPT-4o, l’aperçu audio utilise un encodeur-décodeur unifié où le texte et les jetons acoustiques passent par des blocs d'attention identiques, favorisant l'ancrage intermodal.
• Tokenisation audio hiérarchique – PCM brut 16 kHz → patchs log-mel → codes acoustiques grossiers → jetons sémantiques. Cette compression à plusieurs étages permet Réduction de la bande passante de 40 à 50× tout en préservant les nuances, permettant des clips de plusieurs minutes par fenêtre contextuelle.
• Poids quantifiés NF4 – L’inférence est servie à Flottant normal 4 bits précision, réduisant la mémoire GPU de moitié par rapport au fp16 et maintenant 70+ streaming RTF (facteur temps réel) sur les nœuds A100-80 Go.
• Attention au streaming et mise en cache KV – Les intégrations rotatives à fenêtre coulissante conservent le contexte sur environ 30 s de parole tout en conservant O(L) utilisation de la mémoire, idéal pour les éditeurs de podcasts ou les outils de lecture assistée.
Versionnage et dénomination — Aperçu de la piste avec des versions horodatées
| Identifiant | Développement | Interet | Date de sortie | Stabilité |
|---|---|---|---|---|
| gpt-4o-audio-preview-2025-06-03 | API de complétion de chat | Interactions audio au tour par tour, tâches d'agent | 03 Jun 2025 | Aperçu (commentaires encouragés) |
Éléments clés du nom :
- gpt-4o – Famille omni multimodale.
- acoustique – Optimisé pour les cas d’utilisation de la parole.
- avant-première – Le contrat API peut évoluer ; pas encore GA.
- 2025-06-03 – Instantané de formation et de déploiement pour la reproductibilité.
Comment appeler l'API audio GPT-4o depuis CometAPI
GPT-4o Audio API Tarification des API dans CometAPI :
- Jetons d'entrée : 2 $/M jetons
- Jetons de sortie : 8 $/M jetons
Étapes requises
- Se connecter à cometapi.comSi vous n'êtes pas encore notre utilisateur, veuillez d'abord vous inscrire
- Obtenez la clé API d'accès à l'interface. Cliquez sur « Ajouter un jeton » au niveau du jeton API dans l'espace personnel, récupérez la clé : sk-xxxxx et validez.
- Obtenez l'URL de ce site : https://api.cometapi.com/
Méthodes d'utilisation
- Sélectionnez l'option "**
gpt-4o-audio-preview-2025-06-03**Point de terminaison pour envoyer la requête et définir le corps de la requête. La méthode et le corps de la requête sont disponibles dans la documentation API de notre site web. Notre site web propose également le test Apifox pour plus de commodité. - Remplacer avec votre clé CometAPI réelle de votre compte.
- Insérez votre question ou demande dans le champ de contenu : c'est à cela que le modèle répondra.
- Traitez la réponse de l'API pour obtenir la réponse générée.
Pour plus d'informations sur l'accès aux modèles dans l'API Comet, veuillez consulter API doc.
Pour obtenir des informations sur le prix des modèles dans l'API Comet, veuillez consulter https://api.cometapi.com/pricing.
Flux de travail de l'API — Complétions de chat avec parties audio et crochets de fonction
- Format d'entrée -
audio/*MIME oubase64Morceaux WAV intégrés dansmessages[].content. - Options de sortie -
•mode: "text"→ texte pur pour le sous-titrage.
•mode: "audio"→ renvoie un streaming Charge utile Opus ou µ-law avec horodatages. - Invocation de fonction - Ajouter
functions:schéma; le modèle émetrole: "function"avec des arguments JSON ; le développeur exécute l'appel de l'outil et renvoie éventuellement le résultat. - Rate Control - Ensemble
voice.speed=1.25pour accélérer la lecture ; plages de sécurité 0.25–4.0. - Limites de jetons/audio – 128 k de contexte (~ 4 min de discours) au lancement ; 4096 jetons audio / 8192 jetons texte selon la première éventualité.
Exemple de code et intégration d'API
pythonimport openai
openai.api_key = "YOUR_API_KEY"
# Single-step audio completion (batch)
with open("prompt.wav", "rb") as audio:
response = openai.ChatCompletion.create(
model="gpt-4o-audio-preview-2025-06-03",
messages=[
{"role": "system", "content": "You are a helpful voice assistant."},
{"role": "user", "content": "audio", "audio": audio}
],
temperature=0.3,
speed=1.2 # 20% faster playback
)
print(response.choices.message)
- Temps forts:
- modèle:
"gpt-4o-audio-preview-2025-06-03" - acoustique clé utilisateur message à envoyer en flux binaire
- vitesse: Contrôles débit de voix entre lent (0.5) et rapide (2.0)
- la réactivité: Soldes notre créativité vs. Réplicabilité
Indicateurs techniques — Latence, qualité, précision
| Métrique | Aperçu audio | GPT-4o (texte uniquement) | Delta |
|---|---|---|---|
| Latence du premier jeton (1 coup) | 1.2 s avg | 0.35 s | +0.85 secondes |
| MOS (Naturel de la parole, 5 points) | 4.43 | - | - |
| Conformité des instructions (voix) | 92% | 73% | +19 par personne |
| Précision de l'argument d'appel de fonction | 95.8% | 87% | +8.8 par personne |
| Taux d'erreur de mots (STT implicite) | 5.2% | n/a | - |
| Mémoire GPU / Flux (A100-80 Go) | 7.1 GB | 14 Go (fp16) | −49 % |
Benchmarks exécutés via le streaming Chat Completions, taille du lot = 1.
Voir aussi API en temps réel GPT-4o