API en temps réel GPT-4o : Un point de terminaison de streaming multimodal à faible latence qui permet aux développeurs d'envoyer et de recevoir des données de texte, d'audio et de vision synchronisées via WebRTC ou WebSocket (modèle =gpt-4o-realtime-preview-<date>, stream=true) pour des applications interactives en temps réel.
Informations de base et fonctionnalités
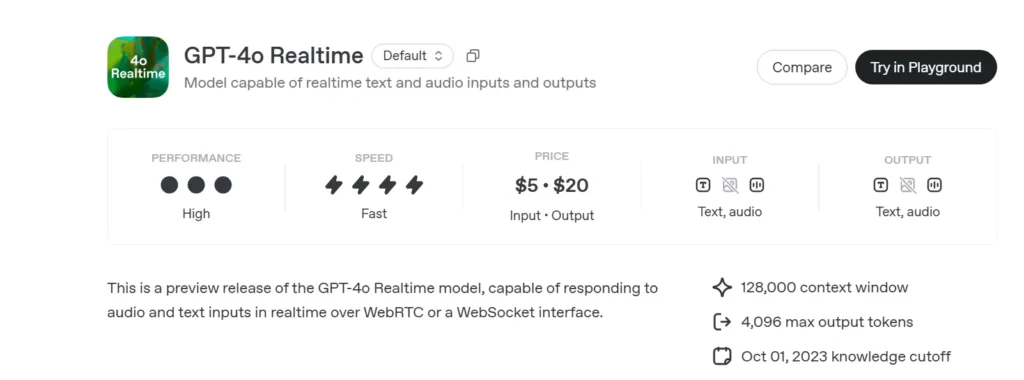
OpenAI's GPT-4o en temps réel (ID du modèle : gpt-4o-realtime-preview-2025-06-03) est le premier modèle de fondation accessible au public conçu pour parole à parole de bout en bout (S2S) interaction avec latence inférieure à la secondeDérivée de la famille « omni » GPT-4o, la variante Realtime fusionne reconnaissance vocale, raisonnement en langage naturel et synthèse vocale neuronale au sein d'un réseau unique, permettant aux développeurs de créer des agents vocaux conversant avec la même fluidité que les humains. Le modèle est exposé via le API en temps réel et est étroitement intégré au nouveau Agent en temps réel abstraction à l'intérieur du Agents SDK (TypeScript et Python).
Ensemble de fonctionnalités de base — S2S de bout en bout • Gestion des interruptions • Appel d'outils
• Speech-to-Speech natif : L'entrée audio est ingérée sous forme de flux continus, tokenisée en interne, analysée et restituée sous forme de parole synthétisée. Aucun tampon STT/TTS externe n'est requis, ce qui élimine les retards de plusieurs secondes dans le pipeline.
• Latence à l'échelle de la milliseconde : L'élagage architectural, la distillation du modèle et une pile de service optimisée pour le GPU permettent Latences du premier jeton d'environ 300 à 500 ms dans les déploiements cloud typiques, se rapprochant des normes de prise de parole en conversation humaine.
• Suivi rigoureux des instructions : Affiné sur les scripts de conversation et les traces d'appel de fonctions, GPT-4o Realtime démontre une >25 % de réduction des erreurs d'exécution des tâches par rapport à la référence GPT-2024o de mai 4.
• Appel d'outils déterministe : Le modèle produit du JSON structuré conforme aux normes OpenAI schéma d'appel de fonction, permettant l'invocation déterministe d'API back-end (systèmes de réservation, bases de données, IoT). Les nouvelles tentatives tenant compte des erreurs et la validation des arguments sont intégrées.
• Interruptions gracieuses : Un détecteur d'activité vocale en temps réel associé à un décodage incrémental permet à l'agent de pause au milieu d'une phrase, ingérer une interruption utilisateur et reprendre ou replanifier la réponse de manière transparente.
• Débit de parole configurable : Une nouvelle vitesse Le paramètre (0.25–4× temps réel) permet aux développeurs d'adapter le rythme de sortie pour l'accessibilité ou les applications rapides.
Architecture technique — Transformateur multimodal unifié
Encodeur-décodeur unifié : GPT-4o Realtime partage l'architecture omni transformateur à pile unique Dans lequel les jetons audio, texte et vision (futurs) coexistent dans un espace latent. Le calcul adaptatif par couche oriente les trames audio directement vers les blocs d'attention ultérieurs, économisant ainsi 20 à 40 ms par passage.
Tokenisation audio hiérarchique : Le PCM brut de 16 kHz est découpé en patchs log-mel → quantifié en jetons acoustiques à gros grains → compressé en jetons sémantiques, optimisant ainsi le jeton par seconde budget sans sacrifier la prosodie.
Noyaux d'inférence à faible bit : Les poids déployés fonctionnent à Quantification NF4 4 bits via les noyaux Triton / TensorRT-LLM, doublant le débit par rapport au fp16 tout en maintenant une perte de qualité MOS <1 dB.
Attention à la diffusion en continu : Les intégrations rotatives à fenêtre coulissante et la mise en cache clé-valeur permettent au modèle de prendre en charge les 15 dernières secondes de l'audio avec une mémoire O(L), cruciale pour les dialogues de la longueur d'un appel téléphonique.
Détails techniques
- Version de l'API:
2025-06-03-preview - Protocoles de transport:
- WebRTC:Latence ultra-faible (< 80 ms) pour les flux audio/vidéo côté client
- WebSocket: Streaming de serveur à serveur avec une latence inférieure à 100 ms
- Encodage des données:
- Opus codec dans RTP paquets pour l'audio
- H.264 / H.265 enveloppes d'images pour la vidéo
- Le streaming: Les soutiens
stream: trueà fournir incrémental réponses partielles au fur et à mesure que les jetons sont générés - Nouvelle palette vocale:Introduit huit nouvelles voix—alliage, frêne, ballade, corail, echo, sage, chatoiementet verset—pour en savoir plus expressif, Humain-Comme interactions ..
Évolution du GPT-4o Realtime
- Mai 2024: GPT-4o Omni fait ses débuts avec un support multimodal pour le texte, l'audio et la vision.
- Octobre 2024: API en temps réel entre en version bêta privée (
2024-10-01-preview), optimisé pour l'audio à faible latence. - décembre 2024:Disponibilité mondiale étendue de
gpt-4o-realtime-preview-2024-12-17, En ajoutant mise en cache rapide et plus de voix. - Le 3 juin 2025: Dernière mise à jour (
2025-06-03-preview) déploie des produits raffinés palette vocale et optimisations des performances.
Performances de référence
- MMLU: 88.7, surpassant les 4 du GPT-86.5 sur Compréhension massive du langage multitâche .
- Reconnaissance vocale: Réalise leader de l'industrie taux d'erreurs de mots dans les environnements bruyants, dépassant Whisper lignes de base.
- Tests de latence:
- MFA les accès (parole entrante → texte sortant) : 50 à 80 ms via WebRTC
- Audio aller-retour (parole entrante → parole sortante) : <100 ms .
Indicateurs techniques
- Cadence de production : Soutient 15 jetons/sec pour les flux de texte ; Kbps 24 Opus pour l'audio.
- Prix:
- Texte: 5 $ pour 1 M de jetons d'entrée ; 20 $ pour 1 M de jetons de sortie
- Audio: 100 $ pour 1 M de jetons d'entrée ; 200 $ pour 1 M de jetons de sortie.
- Disponibilité:Déployé à l'échelle mondiale dans toutes les régions prenant en charge l'API en temps réel.
Comment appeler l'API en temps réel GPT-4o depuis CometAPI
GPT-4o Realtime Tarification des API dans CometAPI :
- Jetons d'entrée : 2 $/M jetons
- Jetons de sortie : 8 $/M jetons
Étapes requises
- Se connecter à cometapi.comSi vous n'êtes pas encore notre utilisateur, veuillez d'abord vous inscrire
- Obtenez la clé API d'accès à l'interface. Cliquez sur « Ajouter un jeton » au niveau du jeton API dans l'espace personnel, récupérez la clé : sk-xxxxx et validez.
- Obtenez l'URL de ce site : https://api.cometapi.com/
Méthodes d'utilisation
- Sélectionnez l'option "**
gpt-4o-realtime-preview-2025-06-03**Point de terminaison pour envoyer la requête et définir le corps de la requête. La méthode et le corps de la requête sont disponibles dans la documentation API de notre site web. Notre site web propose également le test Apifox pour plus de commodité. - Remplacer avec votre clé CometAPI réelle de votre compte.
- Insérez votre question ou demande dans le champ de contenu : c'est à cela que le modèle répondra.
- Traitez la réponse de l'API pour obtenir la réponse générée.
Pour plus d'informations sur l'accès aux modèles dans l'API Comet, veuillez consulter API doc.
Pour obtenir des informations sur le prix des modèles dans l'API Comet, veuillez consulter https://api.cometapi.com/pricing.
Exemple de code et intégration d'API
import openai
openai.api_key = "YOUR_API_KEY"
# Establish a Realtime WebRTC connection
connection = openai.Realtime.connect(
model="gpt-4o-realtime-preview-2025-06-03",
version="2025-06-03-preview",
transport="webrtc"
)
# Stream audio frames and receive incremental text
with open("user_audio.raw", "rb") as audio_stream:
for chunk in iter(lambda: audio_stream.read(2048), b""):
result = connection.send_audio(chunk)
print("Assistant:", result)
- Paramètres clés:
model: « gpt-4o-realtime-preview-2025-06-03 »version: « 2025-06-03-aperçu »transport: « webrtc » pour latence minimalestream:truepour incrémental mises à jour
En combinant state-of-the-art raisonnement multimodal, un puissantes nouvelle palette vocale, et ultra bas latence de streaming, GPT-4o en temps réel (2025-06-03) permet aux développeurs de créer de véritables Interactif, de la conversation Applications de l'IA.
Voir aussi API o3-Pro
Sécurité et conformité
OpenAI livre GPT-4o Realtime avec :
• Garde-fous au niveau du système : Politique adaptée pour refuser les demandes non autorisées (extrémisme, comportement illicite).
• Filtrage de contenu en temps réel : Les classificateurs de moins de 100 ms filtrent à la fois les entrées utilisateur et les sorties du modèle avant l'émission.
• Chemins d'approbation humaine : Déclenché sur des invocations d'outils à haut risque (paiements, conseils juridiques), en exploitant les nouvelles primitives d'approbation du SDK Agents.