

au 15 décembre 2025, les faits publics montrent que Google’s Gemini 3 Pro (preview) et OpenAI’s GPT-5.2 ouvrent tous deux de nouveaux horizons en raisonnement, multimodalité et traitement de très longs contextes — mais empruntent des voies d’ingénierie différentes (Gemini → MoE clairsemé + contexte énorme ; GPT-5.2 → conceptions denses/« routing », compaction et modes de raisonnement x-high) et arbitrent ainsi entre victoires maximales aux benchmarks vs. prédictibilité d’ingénierie, outillage et écosystème. Le « meilleur » dépend de votre besoin principal : les applications agentiques multimodales à contexte extrême penchent vers Gemini 3 Pro ; les outils développeurs d’entreprise stables, des coûts prévisibles et une disponibilité API immédiate favorisent GPT-5.2.
Qu’est-ce que GPT-5.2 et quelles sont ses principales fonctionnalités ?
GPT-5.2 est la version du 11 décembre 2025 de la famille GPT-5 (variantes : Instant, Thinking, Pro). Il est présenté comme le modèle le plus performant de l’entreprise pour le « travail de connaissance professionnel » — optimisé pour les tableurs, présentations, raisonnement à long contexte, appel d’outils, génération de code et tâches de vision. OpenAI a rendu GPT-5.2 disponible aux utilisateurs payants de ChatGPT et via l’API OpenAI (Responses API / Chat Completions) sous des noms de modèle tels que gpt-5.2, gpt-5.2-chat-latest et gpt-5.2-pro.
Variantes du modèle et cas d’usage prévus
- gpt-5.2 / GPT-5.2 (Thinking) — le meilleur pour le raisonnement complexe en plusieurs étapes (la variante « Thinking » par défaut utilisée dans la Responses API).
- gpt-5.2-chat-latest / Instant — assistant et chat du quotidien à plus faible latence.
- gpt-5.2-pro / Pro — fidélité/fiabilité maximale pour les problèmes les plus difficiles (calcul supplémentaire, prend en charge
reasoning_effort: "xhigh").
Caractéristiques techniques clés (côté utilisateur)
- Améliorations vision & multimodalité — meilleur raisonnement spatial sur les images et compréhension vidéo améliorée lorsqu’il est associé à des outils de code (outil Python), plus la prise en charge d’outils de type code-interpreter pour exécuter des extraits.
- Effort de raisonnement configurable (
reasoning_effort: none|minimal|low|medium|high|xhigh) afin d’échanger latence/coût contre profondeur.xhighest nouveau pour GPT-5.2 (et pris en charge sur Pro). - Amélioration du long-contexte et fonctions de compaction pour raisonner sur des centaines de milliers de tokens (OpenAI annonce de solides métriques MRCRv2 / long-contexte).
- Appel d’outils avancé & workflows agentiques — meilleure coordination multi-tours, orchestration renforcée des outils dans une architecture de type « méga-agent unique » (OpenAI met en avant les performances outils sur Tau2-bench).
Qu’est-ce que Gemini 3 Pro Preview ?
Gemini 3 Pro Preview est le modèle d’IA générative le plus avancé de Google, publié dans le cadre de la famille Gemini 3 en novembre 2025. Le modèle met l’accent sur la compréhension multimodale — capable de comprendre et de synthétiser du texte, des images, de la vidéo et de l’audio — et propose une grande fenêtre de contexte (~1 million de tokens) pour gérer de vastes documents ou bases de code.
Google positionne Gemini 3 Pro comme l’état de l’art en profondeur et nuance de raisonnement, et il sert de moteur central à de nombreux outils développeurs et d’entreprise, notamment Google AI Studio, Vertex AI, et des plateformes de développement agentique comme Google Antigravity.
À ce jour, Gemini 3 Pro est en preview — ce qui signifie que les fonctionnalités et l’accès sont encore en expansion, mais le modèle se classe déjà très haut en logique, compréhension multimodale et workflows agentiques.
Caractéristiques techniques & produit clés
- Fenêtre de contexte : Gemini 3 Pro Preview prend en charge une fenêtre de contexte d’entrée de 1 000 000 tokens (et jusqu’à 64k tokens en sortie), ce qui constitue un avantage pratique majeur pour ingérer des documents, livres ou transcriptions vidéo extrêmement volumineux en une seule requête.
- Fonctionnalités API : paramètre
thinking_level(low/high) pour arbitrer latence et profondeur de raisonnement ; paramètresmedia_resolutionpour contrôler la fidélité multimodale et l’usage de tokens ; ancrage sur la recherche, contexte fichiers/URL, exécution de code et function calling sont pris en charge. Les signatures de pensée et la mise en cache de contexte aident à maintenir l’état sur des workflows multi-appels. - Mode Deep Think / raisonnement plus poussé : une option « Deep Think » ajoute une passe de raisonnement supplémentaire pour pousser les scores sur les problèmes complexes. Google publie Deep Think comme une voie distincte haute performance pour les problèmes difficiles.
- Prise en charge multimodale native : entrées texte, image, audio et vidéo avec ancrage serré pour la recherche et les intégrations produits (scores Video-MMMU et autres benchmarks multimodaux mis en avant).
Aperçu rapide — GPT-5.2 vs Gemini 3 Pro
Tableau comparatif compact avec les faits les plus importants (sources citées).
| Aspect | GPT-5.2 (OpenAI) | Gemini 3 Pro (Google / DeepMind) |
|---|---|---|
| Fournisseur / positionnement | OpenAI — mise à niveau phare GPT-5.x axée sur le travail de connaissance professionnel, le code et les workflows agentiques. | Google DeepMind / Google AI — génération Gemini phare axée sur le raisonnement multimodal à très long contexte et l’intégration d’outils. |
| Principales saveurs de modèle | Instant, Thinking, Pro (et bascule automatique entre elles). Pro ajoute un effort de raisonnement plus élevé. | Famille Gemini 3 incluant Gemini 3 Pro et modes Deep-Think ; focus multimodal / agentique. |
| Fenêtre de contexte (entrée/sortie) | Capacité d’entrée totale ~400 000 tokens ; jusqu’à 128 000 tokens de sortie / raisonnement (conçu pour des documents & bases de code très longs). | Jusqu’à ~1 000 000 tokens en entrée/fenêtre de contexte (1M) avec jusqu’à 64K tokens en sortie |
| Forces / focus clés | Raisonnement long-contexte, appel d’outils agentique, codage, tâches structurées en environnement de travail (tableurs, présentations) ; mises à jour safety/system-card axées fiabilité. | Compréhension multimodale à l’échelle, raisonnement + composition d’images, très grande fenêtre de contexte + mode de raisonnement « Deep Think », intégrations serrées dans l’écosystème Google. |
| Capacités multimodales & image | Meilleur ancrage vision et multimodal ; réglé pour l’usage d’outils et l’analyse de documents. | Génération d’images haute fidélité + composition renforcée par le raisonnement, édition multi-référence et rendu de texte lisible. |
| Latence / interactivité | L’éditeur met en avant une inférence plus rapide et une meilleure réactivité du prompt (latence inférieure aux modèles GPT-5.x précédents) ; multiples niveaux (Instant / Thinking / Pro). | Google met en avant un « Flash »/serving optimisé et des vitesses interactives comparables pour de nombreux flux ; le mode Deep Think échange la latence contre un raisonnement plus profond. |
| Caractéristiques notables | Niveaux d’effort de raisonnement (medium/high/xhigh), appel d’outils amélioré, génération de code de haute qualité, forte efficacité en tokens pour les workflows d’entreprise. | Contexte 1M tokens, ingestion multimodale native robuste (vidéo/audio), mode de raisonnement « Deep Think », intégrations serrées avec les produits Google (Docs/Drive/NotebookLM). |
| Meilleurs usages typiques (court) | Analyse de longs documents, workflows agentiques, projets de code complexes, automatisation d’entreprise (tableurs/rapports). | Projets multimodaux extrêmement volumineux, workflows agentiques à long horizon nécessitant 1M de contexte, pipelines image + raisonnement avancés. |
Comment GPT-5.2 et Gemini 3 Pro se comparent-ils sur le plan architectural ?
Architecture de base
- Benchmarks / évaluations en conditions réelles : GPT-5.2 Thinking a atteint 70,9 % de victoires/égalités sur GDPval (évaluation de travail de connaissance couvrant 44 professions) et de larges gains sur les benchmarks d’ingénierie et de mathématiques vs les variantes GPT-5 précédentes. Améliorations majeures en codage (SWE-Bench Pro) et QA scientifique de domaine (GPQA Diamond).
- Outils & agents : prise en charge intégrée solide pour l’appel d’outils, l’exécution Python et les workflows agentiques (recherche de documents, analyse de fichiers, agents data science). 11x plus rapide / <1 % du coût vs experts humains pour certaines tâches GDPval (mesure de la valeur économique potentielle , 70,9 % vs. ~38,8 % précédemment), et gains concrets en modélisation de tableurs (p. ex., +9,3 % sur une tâche de junior en banque d’investissement vs GPT-5.1).
- Gemini 3 Pro : Transformer Mixture-of-Experts clairsemé (MoE). Le modèle active un petit ensemble d’experts par token, permettant une capacité totale de paramètres extrêmement large avec un calcul par token sous-linéaire. Google publie une fiche modèle précisant que la conception Sparse MoE contribue de façon clé au profil de performance amélioré. Cette architecture rend possible de pousser bien plus haut la capacité du modèle sans coût d’inférence linéaire.
- GPT-5.2 (OpenAI) : OpenAI continue d’utiliser des architectures basées sur le Transformer avec des stratégies de routing/compaction dans la famille GPT-5 (un « routeur » déclenche différents modes — Instant vs Thinking — et l’entreprise documente des techniques de compaction et de gestion de tokens pour les longs contextes). GPT-5.2 met l’accent sur l’entraînement et l’évaluation pour « réfléchir avant de répondre » et sur la compaction pour les tâches à long horizon plutôt que d’annoncer un MoE clairsemé classique à grande échelle.
Implications des architectures
- Arbitrages latence & coût : les modèles MoE comme Gemini 3 Pro peuvent offrir une capacité de pointe par token plus élevée tout en maintenant un coût d’inférence inférieur pour de nombreuses tâches car seul un sous-ensemble d’experts s’exécute. Ils peuvent toutefois ajouter de la complexité de service et d’ordonnancement (équilibrage des experts au cold start, E/S). L’approche de GPT-5.2 (dense/à routage avec compaction) privilégie une latence prévisible et une ergonomie développeur — en particulier dans l’outillage OpenAI établi comme Responses, Realtime, Assistants et APIs batch.
- Mise à l’échelle du long contexte : la capacité d’entrée 1M tokens de Gemini permet d’alimenter nativement des documents extrêmement longs et des flux multimodaux. La fenêtre combinée de GPT-5.2 (~400k entrée+sortie) reste massive et couvre la plupart des besoins d’entreprise mais est inférieure à la spécification 1M de Gemini. Pour des corpus très volumineux ou des transcriptions vidéo de plusieurs heures, la spécification de Gemini offre un avantage technique clair.
Outils, agents et plomberie multimodale
- OpenAI : intégration profonde pour l’appel d’outils, l’exécution Python, les modes de raisonnement « Pro » et des écosystèmes d’agents payants (ChatGPT Agents / intégrations d’outils entreprise). Forte focalisation sur les workflows centrés code et la génération de tableurs/diapositives comme sorties de premier ordre.
- Google / Gemini : ancrage intégré à Google Search (fonctionnalité facturée en option), exécution de code, contexte URL et fichiers, et contrôles explicites de la résolution média pour arbitrer tokens vs fidélité visuelle. L’API propose
thinking_levelet d’autres réglages pour adapter coût/latence/qualité.
Comment les chiffres de benchmark se comparent-ils
Fenêtres de contexte et gestion des tokens
- Gemini 3 Pro Preview : 1 000 000 tokens en entrée / 64k tokens en sortie (fiche modèle Pro preview). Date de coupure des connaissances : janvier 2025 (Google).
- GPT-5.2 : OpenAI démontre une solide performance en long contexte (scores MRCRv2 sur des tâches « needle » 4k–256k avec >85–95 % sur de nombreux réglages) et utilise des fonctions de compaction ; les exemples publics d’OpenAI indiquent une robustesse même à très grands contextes mais OpenAI liste des fenêtres spécifiques par variante (et met l’accent sur la compaction plutôt que sur un chiffre unique 1M). Pour l’usage API, les noms de modèles sont
gpt-5.2,gpt-5.2-chat-latest,gpt-5.2-pro.
Raisonnement et benchmarks agentiques
- OpenAI (sélection) : Tau2-bench Telecom 98,7 % (GPT-5.2 Thinking), forts gains dans l’utilisation d’outils multi-étapes et les tâches agentiques (OpenAI met en avant la fusion de systèmes multi-agents en « méga-agent »). GPQA Diamond et ARC-AGI montrent des bonds par rapport à GPT-5.1.
- Google (sélection) : Gemini 3 Pro : LMArena 1501 Elo, MMMU-Pro 81 %, Video-MMMU 87,6 %, GPQA élevé et scores à Humanity’s Last Exam ; Google démontre aussi une planification à long horizon via des exemples agentiques.
Outils & agents :
GPT-5.2 : Prise en charge intégrée robuste pour l’appel d’outils, l’exécution Python et les workflows agentiques (recherche de documents, analyse de fichiers, agents data science). 11x plus rapide / <1 % du coût vs experts humains pour certaines tâches GDPval (mesure de la valeur économique potentielle , 70,9 % vs. ~38,8 % précédemment), et gains concrets en modélisation de tableurs (p. ex., +9,3 % sur une tâche de junior en banque d’investissement vs GPT-5.1).
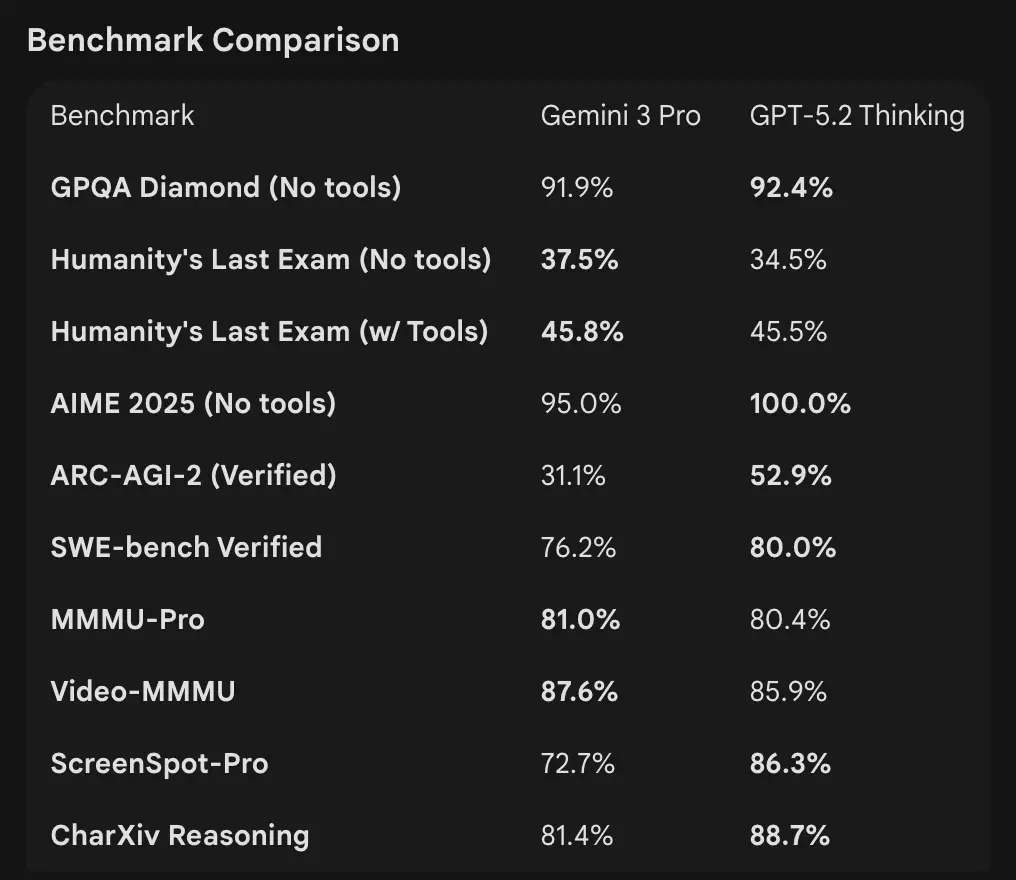
Interprétation : les benchmarks sont complémentaires — OpenAI met l’accent sur des benchmarks de travail de connaissance réel (GDPval) montrant que GPT-5.2 excelle dans des tâches de production comme les tableurs, diapositives et longues séquences agentiques. Google met en avant des classements de raisonnement brut et des fenêtres de contexte à requête unique extrêmement grandes. Ce qui compte le plus dépend de votre charge : les pipelines d’entreprise agentiques et longs documents favorisent la performance GDPval éprouvée de GPT-5.2 ; l’ingestion de contextes bruts massifs (p. ex., corpus vidéo entiers / livres complets en un seul passage) favorise la fenêtre d’entrée 1M de Gemini.
Comment se comparent les capacités multimodales ?
Entrées & sorties
- Gemini 3 Pro Preview : prend en charge les entrées texte, image, vidéo, audio, PDF et des sorties texte ; Google fournit des contrôles fins
media_resolutionet un paramètrethinking_levelpour ajuster coût vs fidélité en multimodal. Limite de sortie 64k tokens ; entrée jusqu’à 1M tokens. - GPT-5.2 : prend en charge des workflows vision et multimodaux riches ; OpenAI met en avant un raisonnement spatial amélioré (étiquettes estimées de délimitation d’objets), la compréhension vidéo (scores Video MMMU) et la vision assistée par outils (l’outil Python sur les tâches de vision améliore les scores). GPT-5.2 souligne que les tâches vision + code complexes bénéficient grandement de l’activation des outils (exécution de code Python).
Différences pratiques
Granularité vs. étendue : Gemini expose une série de réglages multimodaux (media_resolution, thinking_level) pour permettre aux développeurs d’ajuster les arbitrages selon le type de média. GPT-5.2 met l’accent sur l’usage intégré des outils (exécuter Python dans la boucle) pour combiner vision, code et transformations de données. Si votre cas d’usage implique fortement l’analyse vidéo + image avec des contextes extrêmement grands, l’argument du contexte 1M de Gemini est convaincant ; si vos workflows exigent d’exécuter du code dans la boucle (transformations de données, génération de tableurs), l’outillage code et la convivialité agentique de GPT-5.2 peuvent être plus pratiques.
Qu’en est-il de l’accès API, des SDK et des tarifs ?
OpenAI GPT-5.2 (API & tarification)
- API :
gpt-5.2,gpt-5.2-chat-latest,gpt-5.2-provia Responses API / Chat Completions. SDK établis (Python/JS), guides « cookbook » et écosystème mûr. - Tarifs (publics) : $1.75 / 1M tokens d’entrée et $14 / 1M tokens de sortie ; des remises de cache (90 % pour les entrées en cache) réduisent le coût effectif pour les données répétées. OpenAI met en avant l’efficacité en tokens (prix par token plus élevé mais moins de tokens pour atteindre un seuil de qualité).
Gemini 3 Pro Preview (API & tarification)
- API :
gemini-3-pro-previewvia Google GenAI SDK et les endpoints Vertex AI/GenerativeLanguage. Nouveaux paramètres (thinking_level,media_resolution) et intégration avec les ancrages Google et outils. - Tarifs (aperçu public) : Environ $2 / 1M tokens d’entrée et $12 / 1M tokens de sortie pour les niveaux preview en dessous de 200k tokens ; des frais supplémentaires peuvent s’appliquer pour l’ancrage Search, Maps ou d’autres services Google (la facturation de l’ancrage Search commence le 5 janv. 2026).
Utiliser GPT-5.2 et Gemini 3 via CometAPI
CometAPI est une API de passerelle/agrégateur : un unique endpoint REST au format OpenAI qui vous donne un accès unifié à des centaines de modèles de nombreux fournisseurs (LLM, modèles image/vidéo, modèles d’embedding, etc.). Au lieu d’intégrer de multiples SDK éditeurs, CometAPI vise à vous permettre d’appeler des endpoints familiers au format OpenAI (chat/completions/embeddings/images) tout en changeant de modèle ou de fournisseur sous le capot.
Les développeurs peuvent profiter simultanément de modèles phares de deux entreprises différentes via CometAPI sans changer de fournisseur, et les prix de l’API sont plus abordables, généralement avec 20 % de réduction.
Exemple : extraits API rapides (copier-coller pour essayer)
Ci-dessous des exemples minimaux que vous pouvez exécuter. Ils reflètent les « quickstarts » publiés par les éditeurs (OpenAI Responses API + client Google GenAI). Remplacez $OPENAI_API_KEY / $GEMINI_API_KEY par vos clés.
GPT-5.2 — Python (OpenAI Responses API, reasoning réglé sur xhigh pour les problèmes difficiles)
# Python (requires openai SDK that supports responses API)from openai import OpenAIclient = OpenAI(api_key="YOUR_OPENAI_API_KEY")resp = client.responses.create( model="gpt-5.2-pro", # gpt-5.2 or gpt-5.2-pro input="Summarize this 50k token company report and output a 10-slide presentation outline with speaker notes.", reasoning={"effort": "xhigh"}, # deeper reasoning max_output_tokens=4000)print(resp.output_text) # or inspect resp to get structured outputs / tokens
Notes : reasoning.effort vous permet d’arbitrer coût vs profondeur. Utilisez gpt-5.2-chat-latest pour le style chat Instant. La documentation OpenAI montre des exemples pour responses.create.
GPT-5.2 — curl (simple)
curl https://api.openai.com/v1/responses \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-5.2", "input": "Write a Python function that converts a PDF with tables into a normalized CSV with typed columns.", "reasoning": {"effort":"high"} }'
(Inspectez le JSON pour output_text ou des sorties structurées.)
Gemini 3 Pro Preview — Python (client Google GenAI)
# Python (google genai client) — example from Google docsfrom google import genaiclient = genai.Client(api_key="YOUR_GEMINI_API_KEY")response = client.models.generate_content( model="gemini-3-pro-preview", contents="Find the race condition in this multi-threaded C++ snippet: <paste code here>", config={ "thinkingConfig": {"thinking_level": "high"} })print(response.text)
Notes : thinking_level contrôle la délibération interne du modèle ; media_resolution peut être défini pour les images/vidéos. Les exemples REST et JS figurent dans le guide développeur Gemini de Google.
Gemini 3 Pro — curl (REST)
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \ -H "x-goog-api-key: $GEMINI_API_KEY" \ -H "Content-Type: application/json" \ -X POST \ -d '{ "contents": [{ "parts": [{"text": "Explain the race condition in this C++ code: ..."}] }], "generationConfig": {"thinkingConfig": {"thinkingLevel": "high"}} }'
La documentation de Google inclut des exemples multimodaux (image inline data, media_resolution).
Quel modèle est « meilleur » — conseils pratiques
Il n’y a pas de « gagnant » universel ; choisissez plutôt selon le cas d’usage et les contraintes. Voici une courte matrice de décision.
Choisissez GPT-5.2 si :
- Vous avez besoin d’une intégration étroite avec des outils d’exécution de code (écosystème d’interpréteur/outils d’OpenAI) pour des pipelines programmatiques de données, la génération de tableurs ou des workflows de code agentiques. OpenAI met en avant des améliorations de l’outil Python et l’usage de méga-agent.
- Vous priorisez l’efficacité en tokens selon les indications du fournisseur et souhaitez une tarification OpenAI par token explicite et prévisible avec de fortes remises sur les entrées mises en cache (utile pour les traitements batch/production).
- Vous voulez l’écosystème OpenAI (intégration produit ChatGPT, partenariats Azure / Microsoft et outillage autour de Responses API et Codex).
Choisissez Gemini 3 Pro si :
- Vous avez besoin d’entrées multimodales extrêmes (vidéo + images + audio + pdfs) et souhaitez un modèle unique acceptant nativement toutes ces entrées avec une fenêtre d’entrée de 1 000 000 tokens. Google commercialise explicitement cela pour les longues vidéos, les pipelines documents + vidéo volumineux et les cas d’usage interactifs Search/AI Mode.
- Vous construisez sur Google Cloud / Vertex AI et voulez une intégration étroite avec l’ancrage Google Search, le provisioning Vertex et les clients GenAI. Vous bénéficierez des intégrations produits Google (Search AI Mode, AI Studio, outillage agentique Antigravity).
Conclusion : lequel est meilleur en 2026 ?
Dans le duel GPT-5.2 vs. Gemini 3 Pro Preview, la réponse est dépendante du contexte :
- GPT-5.2 mène en travail de connaissance professionnel, profondeur analytique et workflows structurés.
- Gemini 3 Pro Preview excelle en compréhension multimodale, intégrations d’écosystème et tâches à grand contexte.
Aucun modèle n’est « meilleur » en toutes circonstances — leurs forces répondent à des besoins réels différents. Les adopteurs avisés feront correspondre le choix du modèle aux cas d’usage spécifiques, aux contraintes budgétaires et à l’alignement d’écosystème.
Ce qui est clair en 2026, c’est que la frontière de l’IA a considérablement avancé, et GPT-5.2 comme Gemini 3 Pro repoussent les limites de ce que les systèmes intelligents peuvent accomplir en entreprise et au-delà.
Si vous voulez essayer tout de suite, explorez les capacités de GPT-5.2 et Gemini 3 Pro sur CometAPI dans le Playground et consultez le guide de l’API pour des instructions détaillées. Avant d’accéder, assurez-vous d’être connecté à CometAPI et d’avoir obtenu la clé API. CometAPI propose un prix bien inférieur au tarif officiel pour vous aider à intégrer.
Prêt à démarrer ? → Essai gratuit de GPT-5.2 et Gemini 3 Pro !
If you want to