

OpenAI a publié un aperçu de ses recherches gpt-oss-safeguard, une famille de modèles d'inférence à poids ouverts conçue pour permettre aux développeurs d'appliquer leur propre Des politiques de sécurité sont mises en place dès l'inférence. Plutôt que de fournir un classificateur fixe ou un moteur de modération opaque, les nouveaux modèles sont finement ajustés pour motif tiré d'une politique fournie par le développeurIls émettent une chaîne de pensée (CoT) expliquant leur raisonnement et produisent des résultats de classification structurés. Annoncé en avant-première pour la recherche, gpt-oss-safeguard se présente comme une paire de modèles de raisonnement :gpt-oss-safeguard-120b et gpt-oss-safeguard-20b—affiné à partir de la famille gpt-oss et conçu explicitement pour effectuer des tâches de classification de sécurité et d'application des politiques pendant l'inférence.
Qu'est-ce que gpt-oss-safeguard ?
gpt-oss-safeguard est une paire de modèles de raisonnement textuels à poids ouvert qui ont été post-entraînés à partir de la famille gpt-oss. interpréter une politique rédigée en langage naturel et étiqueter le texte conformément à cette politiqueLa caractéristique distinctive est que la politique est fourni au moment de l'inférence (La politique est utilisée comme entrée), et non intégrée aux pondérations statiques du classificateur. Les modèles sont principalement conçus pour des tâches de classification de sécurité, telles que la modération multipolitique, la classification de contenu selon plusieurs régimes réglementaires ou les contrôles de conformité aux politiques.
Pourquoi cela importe
Les systèmes de modération traditionnels s'appuient généralement sur (a) des ensembles de règles fixes associés à des classificateurs entraînés sur des exemples étiquetés, ou (b) des heuristiques/expressions régulières pour la détection de mots-clés. gpt-oss-safeguard propose une approche novatrice : au lieu de réentraîner les classificateurs à chaque modification de la politique, vous fournissez un texte de politique (par exemple, la politique d'utilisation acceptable de votre entreprise, les conditions d'utilisation de la plateforme ou une directive réglementaire), et le modèle détermine si un contenu donné enfreint cette politique. Cette approche garantit agilité (modifications de la politique sans réentraînement) et interprétabilité (le modèle fournit son raisonnement).
Voici sa philosophie fondamentale : « Remplacer la mémorisation par le raisonnement et la conjecture par l’explication. »
Cela représente une nouvelle étape en matière de sécurité du contenu, passant de « l’apprentissage passif des règles » à « la compréhension active des règles ».
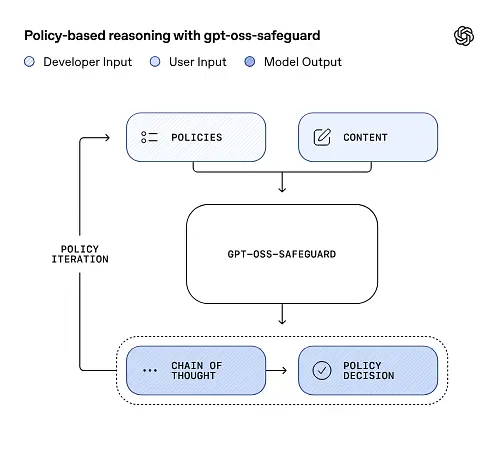
gpt-oss-safeguard peut lire directement les politiques de sécurité définies par les développeurs et suivre ces politiques pour porter des jugements lors de l'inférence.
Comment fonctionne gpt-oss-safeguard ?
Raisonnement fondé sur la politique en tant qu'entrée
Au moment de l'inférence, vous fournissez deux choses : le texte de politique et la contenu candidat à étiqueter. Le modèle considère la politique comme l'instruction principale, puis effectue un raisonnement étape par étape pour déterminer si le contenu est autorisé, interdit ou nécessite des étapes de modération supplémentaires. Lors de l'inférence, le modèle :
- produit un résultat structuré qui comprend une conclusion (étiquette, catégorie, confiance) et une trace de raisonnement lisible par l'humain expliquant pourquoi cette conclusion a été atteinte.
- intègre la politique et le contenu à classifier,
- il analyse en interne les clauses de la police d'assurance en suivant un raisonnement logique, et
Par exemple :
Policy: Content that encourages violence, hate speech, pornography, or fraud is not allowed.
Content: This text describes a fighting game.
Il répondra :
Classification: Safe
Reasoning: The content only describes the game mechanics and does not encourage real violence.
Chaîne de pensée (CoT) et résultats structurés
gpt-oss-safeguard peut générer une trace CoT complète pour chaque inférence. Cette trace est conçue pour être inspectable : les équipes de conformité peuvent ainsi comprendre le raisonnement du modèle et les ingénieurs peuvent l’utiliser pour diagnostiquer les ambiguïtés des politiques ou les défaillances du modèle. Le modèle prend également en charge… résultats structurés— par exemple, un fichier JSON contenant un verdict, les articles de politique violés, le score de gravité et les actions correctives suggérées — ce qui facilite son intégration dans les processus de modération.
Niveaux d’« effort de raisonnement » réglables
Pour équilibrer la latence, le coût et l'exhaustivité, les modèles prennent en charge un effort de raisonnement configurable : faible / moyen / élevéUn effort plus important approfondit le raisonnement et produit généralement des conclusions plus robustes, mais plus lentes et plus coûteuses. Cela permet aux développeurs de prioriser leurs tâches : allouer un effort moindre au contenu courant et un effort plus important aux cas particuliers ou au contenu à haut risque.
Quelle est la structure du modèle et quelles sont les versions existantes ?
Famille et lignée modèles
gpt-oss-safeguard sont post-entraînement des variantes antérieures d'OpenAI gpt-oss Modèles ouverts. La gamme de protection comprend actuellement deux tailles disponibles :
- gpt-oss-safeguard-120b — un modèle à 120 milliards de paramètres destiné à des tâches de raisonnement de haute précision, qui fonctionne toujours sur un seul GPU de 80 Go dans des environnements d'exécution optimisés.
- gpt-oss-safeguard-20b — un modèle de 20 milliards de paramètres optimisé pour l'inférence à moindre coût et les environnements périphériques ou sur site (peut fonctionner sur des appareils de 16 Go de VRAM dans certaines configurations).
Notes d'architecture et caractéristiques d'exécution (à quoi s'attendre)
- Paramètres actifs par jeton : L'architecture sous-jacente de gpt-oss utilise des techniques qui réduisent le nombre de paramètres activés par jeton (un mélange de conception de style attention dense et clairsemée / mélange d'experts dans le gpt-oss parent).
- En pratique, la classe 120B tient sur des accélérateurs uniques de grande taille et la classe 20B est conçue pour fonctionner sur des configurations de 16 Go de VRAM dans des temps d'exécution optimisés.
Les modèles de sauvegarde étaient non formé avec des données supplémentaires en biologie ou en cybersécuritéLes analyses des scénarios d'utilisation abusive les plus graves réalisées pour la version gpt-oss s'appliquent globalement aux variantes de protection. Ces modèles sont destinés à la classification et non à la génération de contenu pour les utilisateurs finaux.
Quels sont les objectifs de gpt-oss-safeguard
Objectifs
- Flexibilité des politiques : Permettre aux développeurs de définir n'importe quelle politique en langage naturel et de laisser le modèle l'appliquer sans collecte d'étiquettes personnalisée.
- Explicabilité: Exposer le raisonnement afin que les décisions puissent être auditées et les politiques itérées.
- Accessibilité: proposer une alternative à poids ouvert afin que les organisations puissent effectuer des analyses de sécurité localement et examiner le fonctionnement interne du modèle.
Comparaison avec les classificateurs classiques
Avantages par rapport aux classificateurs traditionnels
- Aucune formation supplémentaire n'est requise pour les changements de politique : Si votre politique de modération change, mettez à jour le document de politique plutôt que de collecter des étiquettes et de réentraîner un classificateur.
- Raisonnement plus riche : Les résultats de CoT peuvent révéler des interactions politiques subtiles et fournir une justification narrative utile aux examinateurs humains.
- Personnalisabilité: Un seul modèle peut appliquer simultanément de nombreuses politiques différentes lors de l'inférence.
Inconvénients par rapport aux classificateurs traditionnels
- Limites de performance pour certaines tâches : L'évaluation d'OpenAI note que Les classificateurs de haute qualité entraînés sur des dizaines de milliers d'exemples étiquetés peuvent surpasser gpt-oss-safeguard Pour des tâches de classification spécialisées, un classificateur dédié, entraîné sur cette distribution, peut s'avérer plus performant lorsque l'objectif est la précision brute de la classification et que les données sont étiquetées.
- Latence et coût : Le raisonnement avec CoT est gourmand en ressources de calcul et plus lent qu'un classificateur léger ; cela peut rendre les pipelines basés uniquement sur des mécanismes de sauvegarde coûteux à grande échelle.
En bref : gpt-oss-safeguard est particulièrement efficace lorsque agilité et auditabilité des politiques sont prioritaires ou lorsque les données étiquetées sont rares — et comme composant complémentaire dans les pipelines hybrides, pas nécessairement comme remplacement direct d'un classificateur optimisé à l'échelle.
Quelles ont été les performances de gpt-oss-safeguard lors des évaluations d'OpenAI ?
OpenAI a publié des résultats de référence dans un rapport technique de 10 pages résumant les évaluations internes et externes. Principaux enseignements (métriques clés sélectionnées) :
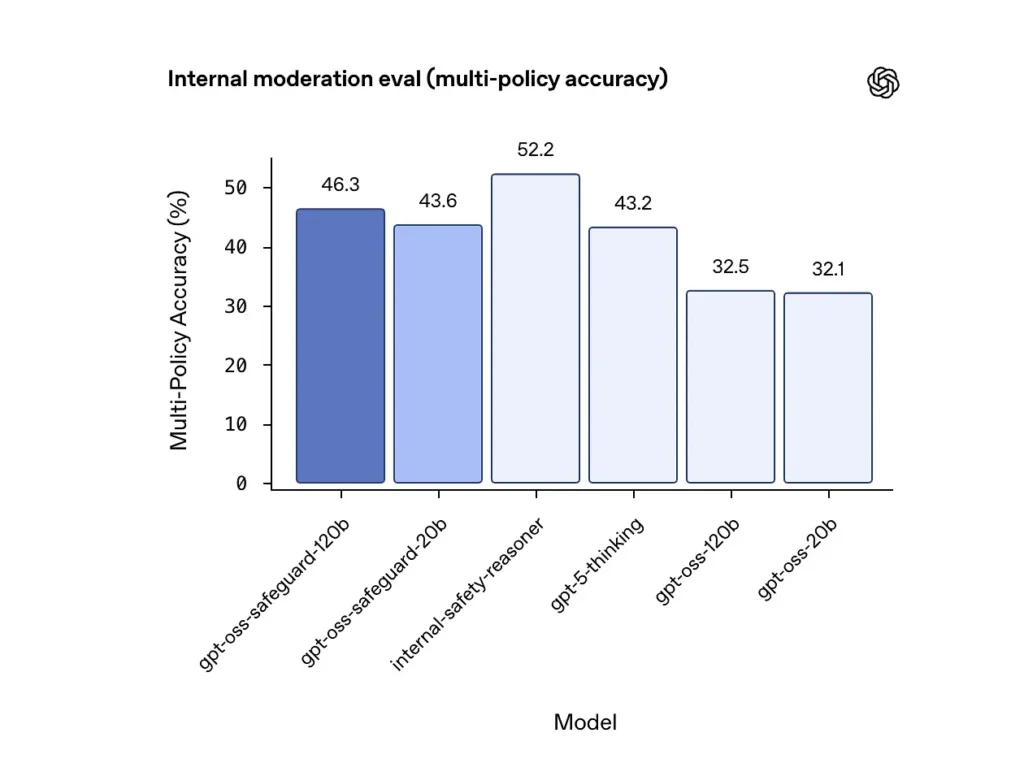
Précision multi-politiques (évaluation interne)
OpenAI a évalué la précision multi-politique en fournissant le modèle plusieurs des politiques simultanément et ne considérant une prédiction comme correcte que si elle correspondait aux étiquettes de référence. tous politiques. Résultats :
- gpt-oss-safeguard-120b : 46.3% précision multi-police
- gpt-oss-safeguard-20b : 43.6%
- En comparaison: gpt-5-pensée : 43.2%; gpt-oss-120b : 32.5%; gpt-oss-20b : % 32.1.
L'ensemble interne « safety-reasoner » d'OpenAI a obtenu un score de 52.2 % au même test. Ces résultats montrent que les modèles de protection surpassent largement leurs modèles de base gpt-oss sur la tâche multi-politique, et qu'ils ont même dépassé le modèle de référence plus large gpt-5-thinking dans la métrique multi-politique interne.
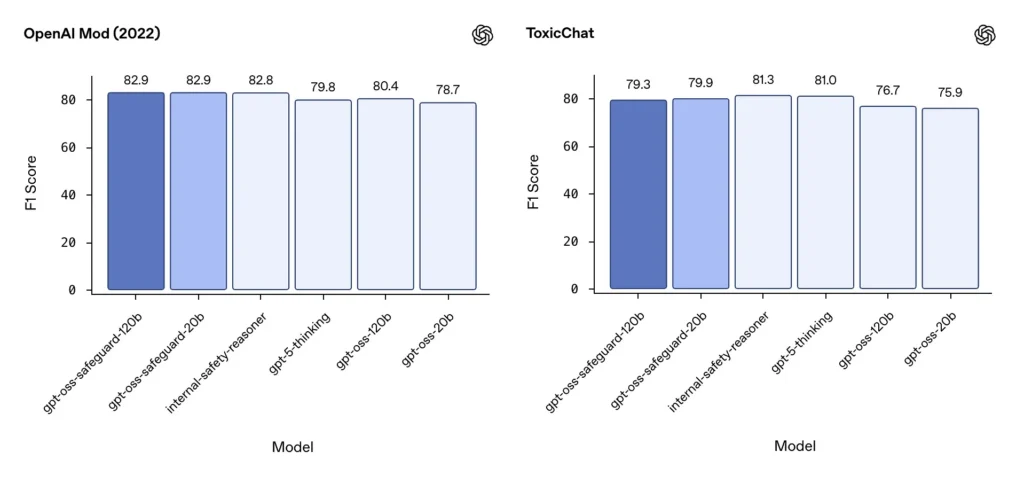
Modération F1 (références externes)
Sur l'ensemble de données de modération 2022 d'OpenAI et sur le benchmark public ToxicChat, les modèles gpt-oss-safeguard ont obtenu de solides scores F1 :
- OpenAI Mod (2022) F1 : gpt-oss-safeguard-120b = 82.9%, gpt-oss-safeguard-20b = 82.9%
- ToxicChat F1 : gpt-oss-safeguard-120b = 79.3%, gpt-oss-safeguard-20b = 79.9%
Ces scores placent gpt-oss-safeguard près ou légèrement derrière les systèmes internes spécialisés d'OpenAI sur certains benchmarks, et généralement devant les homologues gpt-oss non finement réglés.
Limitations observées
OpenAI signale deux limitations pratiques :
- Les classificateurs entraînés sur de grands ensembles de données étiquetées spécifiques à la tâche peuvent encore surpasser les modèles de protection. lorsque la précision de la classification est le seul objectif.
- Coûts de calcul et de latence : Le raisonnement CoT augmente le temps d'inférence et la consommation de calcul, ce qui complique la mise à l'échelle au niveau du trafic de la plateforme, sauf s'il est associé à des classificateurs de triage et à des pipelines asynchrones.
parité multilingue
gpt-oss-safeguard offre des performances équivalentes à celles des modèles gpt-oss sous-jacents dans de nombreux langages lors de tests de style MMMLU, ce qui indique que les variantes de protection finement ajustées conservent une large capacité de raisonnement.
Comment les équipes peuvent-elles accéder à gpt-oss-safeguard et le déployer ?
OpenAI fournit les poids sous licence Apache 2.0 et propose des liens pour le téléchargement des modèles (Hugging Face). Le modèle gpt-oss-safeguard étant à poids ouverts, un déploiement local et autogéré est recommandé pour des raisons de confidentialité et de personnalisation.
- Télécharger les poids du modèle (issues d'OpenAI / Hugging Face) et hébergez-les sur vos propres serveurs ou machines virtuelles cloud. Apache 2.0 autorise la modification et l'utilisation commerciale.
- RuntimeUtilisez des environnements d'exécution d'inférence standard prenant en charge les grands modèles de transformateurs (ONNX Runtime, Triton ou des environnements d'exécution optimisés par le fournisseur). Les environnements d'exécution communautaires comme Ollama et LM Studio intègrent déjà la prise en charge des familles gpt-oss.
- MatérielLe modèle 120B nécessite généralement des GPU à grande capacité de mémoire (par exemple, A100/H100 de 80 Go ou partitionnement multi-GPU), tandis que le modèle 20B est plus économique et propose des options optimisées pour les configurations avec 16 Go de VRAM. Prévoyez la capacité nécessaire en fonction du débit maximal et des coûts d'évaluation de plusieurs stratégies.
Environnements d'exécution gérés et tiers
Si la gestion de votre propre matériel est impraticable, API Comet La prise en charge des modèles gpt-oss s'étend rapidement. Ces plateformes facilitent la mise à l'échelle, mais présentent à nouveau des risques d'exposition des données tierces. Il est donc essentiel d'évaluer la confidentialité, les SLA et les contrôles d'accès avant de choisir des environnements d'exécution gérés.
Stratégies de modération efficaces avec gpt-oss-safeguard
1) Utiliser un pipeline hybride (triage → justification → décision)
- Couche de triage : Des classificateurs (ou règles) simples et rapides éliminent les cas triviaux. Cela réduit la charge sur le modèle de protection coûteux.
- Couche de protection : Exécutez gpt-oss-safeguard pour les contrôles ambigus, à haut risque ou à politiques multiples où les nuances de politique sont importantes.
- Arbitrage humain : Ce modèle hybride permet de traiter les cas particuliers et les appels, en conservant les preuves de transparence. Il offre un équilibre entre débit et précision.
2) Ingénierie des politiques (et non ingénierie des délais)
- Considérez les politiques comme des artefacts logiciels : gérez les versions, testez-les sur des ensembles de données et veillez à ce qu’elles soient explicites et hiérarchiques.
- Rédigez des politiques avec des exemples et des contre-exemples. Dans la mesure du possible, incluez des instructions de clarification (par exemple : « Si l’intention de l’utilisateur est clairement exploratoire et historique, étiquetez-la comme X ; si l’intention est opérationnelle et en temps réel, étiquetez-la comme Y »).
3) Configurer l'effort de raisonnement de manière dynamique
- Utilisez le effort faible pour le traitement en vrac et effort élevé pour les contenus signalés, les appels ou les secteurs verticaux à fort impact (juridique, médical, financier).
- Ajustez les seuils en fonction des retours d'évaluation humaine afin de trouver le juste équilibre entre coût et qualité.
4) Valider le CoT et surveiller les raisonnements hallucinés
Le CoT est précieux, mais il peut induire en erreur : la trace est une justification générée par un modèle, et non la vérité de référence. Il est donc essentiel de contrôler régulièrement les résultats du CoT et d’utiliser des détecteurs pour repérer les citations erronées ou les raisonnements incohérents. OpenAI documente ces erreurs de raisonnement comme un problème connu et propose des solutions pour les atténuer.
5) Créer des ensembles de données à partir du fonctionnement du système
Les décisions des modèles de journalisation et les corrections humaines permettent de créer des ensembles de données étiquetées susceptibles d'améliorer les classificateurs de triage ou d'orienter la réécriture des politiques. À terme, un petit ensemble de données étiquetées de haute qualité, associé à un classificateur efficace, réduit souvent le recours à l'inférence CoT complète pour le contenu de routine.
6) Surveiller les ressources de calcul et les coûts ; utiliser des flux asynchrones
Pour les applications grand public à faible latence, privilégiez les contrôles de sécurité asynchrones avec une expérience utilisateur conservatrice à court terme (par exemple, masquer temporairement le contenu en attente de validation) plutôt que d'effectuer des vérifications de traçabilité (CoT) synchrones complexes. OpenAI indique que Safety Reasoner utilise des flux asynchrones en interne pour gérer la latence des services en production.
7) Tenir compte de la confidentialité et du lieu de déploiement
Comme les pondérations sont ouvertes, vous pouvez exécuter l'inférence entièrement sur site pour vous conformer à une gouvernance des données stricte ou réduire l'exposition aux API tierces, ce qui est précieux pour les secteurs réglementés.
Conclusion:
gpt-oss-safeguard est un outil pratique, transparent et flexible pour raisonnement en matière de sécurité axé sur les politiquesElle brille quand on en a besoin. des décisions vérifiables liées à des politiques explicites, lorsque vos politiques changent fréquemment, ou lorsque vous souhaitez maintenir des contrôles de sécurité sur place. C'est pas Il ne s'agit pas d'une solution miracle qui remplacerait automatiquement les classificateurs spécialisés à haut débit : les évaluations d'OpenAI montrent que les classificateurs dédiés, entraînés sur de vastes corpus étiquetés, peuvent surpasser ces modèles en termes de précision brute pour des tâches spécifiques. Il convient plutôt de considérer gpt-oss-safeguard comme un composant stratégique : le moteur de raisonnement explicable au cœur d'une architecture de sécurité multicouche (tri rapide → raisonnement explicable → supervision humaine).
Pour commencer
CometAPI est une plateforme d'API unifiée qui regroupe plus de 500 modèles d'IA provenant de fournisseurs leaders, tels que la série GPT d'OpenAI, Gemini de Google, Claude d'Anthropic, Midjourney, Suno, etc., au sein d'une interface unique et conviviale pour les développeurs. En offrant une authentification, un formatage des requêtes et une gestion des réponses cohérents, CometAPI simplifie considérablement l'intégration des fonctionnalités d'IA dans vos applications. Que vous développiez des chatbots, des générateurs d'images, des compositeurs de musique ou des pipelines d'analyse pilotés par les données, CometAPI vous permet d'itérer plus rapidement, de maîtriser les coûts et de rester indépendant des fournisseurs, tout en exploitant les dernières avancées de l'écosystème de l'IA.
La dernière intégration gpt-oss-safeguard sera bientôt disponible sur CometAPI, alors restez à l'écoute ! En attendant la finalisation du chargement du modèle gpt-oss-safeguard, les développeurs peuvent y accéder. API GPT-OSS-20B et API GPT-OSS-120B via CometAPI, la dernière version du modèle est constamment mis à jour avec le site officiel. Pour commencer, explorez les capacités du modèle dans la section cour de récréation et consultez le Guide de l'API Pour des instructions détaillées, veuillez vous connecter à CometAPI et obtenir la clé API avant d'y accéder. API Comet proposer un prix bien inférieur au prix officiel pour vous aider à vous intégrer.
Prêt à partir ?→ Inscrivez-vous à CometAPI dès aujourd'hui !
Si vous souhaitez connaître plus de conseils, de guides et d'actualités sur l'IA, suivez-nous sur VK, X et Discord!