

GLM-5 est le nouveau modèle fondamental à poids ouverts, centré sur les agents, de Zhipu AI, conçu pour la programmation à long horizon et les agents multi-étapes. Il est disponible via plusieurs API hébergées (dont CometAPI et des endpoints de fournisseurs) ainsi qu’en version de recherche avec code et poids ; vous pouvez l’intégrer via des appels REST compatibles OpenAI standard, du streaming et des SDK.
Qu'est-ce que GLM-5 de Z.ai ?
GLM-5 est le modèle fondamental phare de cinquième génération de Z.ai, conçu pour l’ingénierie agentique : planification à long horizon, utilisation multi-étapes d’outils et conception de code/systèmes à grande échelle. Publié publiquement en février 2026, GLM-5 est un modèle Mélange d’Experts (MoE) avec ~744 milliards de paramètres au total et un ensemble actif d’environ 40 milliards par passe avant ; l’architecture et les choix d’entraînement privilégient la cohérence sur de longs contextes, l’appel d’outils et une inférence à coût optimisé pour des charges de production. Ces choix permettent à GLM-5 d’exécuter des workflows agentiques étendus (par exemple : explorer → planifier → écrire/tester du code → itérer) tout en préservant le contexte sur des entrées très longues.
Points techniques clés :
- Architecture MoE à ~744B au total / ~40B de paramètres actifs ; pré-entraînement à l’échelle (~28.5T jetons rapportés) pour réduire l’écart avec les modèles propriétaires de pointe.
- Prise en charge des longs contextes et optimisations (Deep Sparse Attention, DSA) pour réduire les coûts de déploiement par rapport au scaling dense naïf.
- Fonctionnalités agentiques intégrées : appel d’outils/fonctions, prise en charge de sessions avec état et sorties intégrées (capable de produire des artefacts
.docx,.xlsx,.pdfdans le cadre de workflows agentiques dans les interfaces des fournisseurs). - Disponibilité en poids ouverts (poids publiés sur des hubs de modèles) et options d’accès hébergées (API des fournisseurs, microservices d’inférence).
Quels sont les principaux avantages de GLM-5 ?
Planification agentique et mémoire à long horizon
L’architecture et le réglage de GLM-5 privilégient un raisonnement multi-étapes et une mémoire cohérente sur l’ensemble des workflows — utile pour :
- agents autonomes (pipelines CI, orchestrateurs de tâches),
- génération ou refactorisation de code à grande échelle sur plusieurs fichiers, et
- intelligence documentaire nécessitant de conserver de grands historiques.
Fenêtres de contexte larges
GLM-5 prend en charge des tailles de contexte très grandes (de l’ordre de ~200k jetons selon les spécifications publiées), ce qui permet de conserver davantage d’une session dans une seule requête et réduit le besoin de découpage agressif ou de mémoire externe pour de nombreux cas d’usage. (Voir le tableau comparatif ci-dessous.)
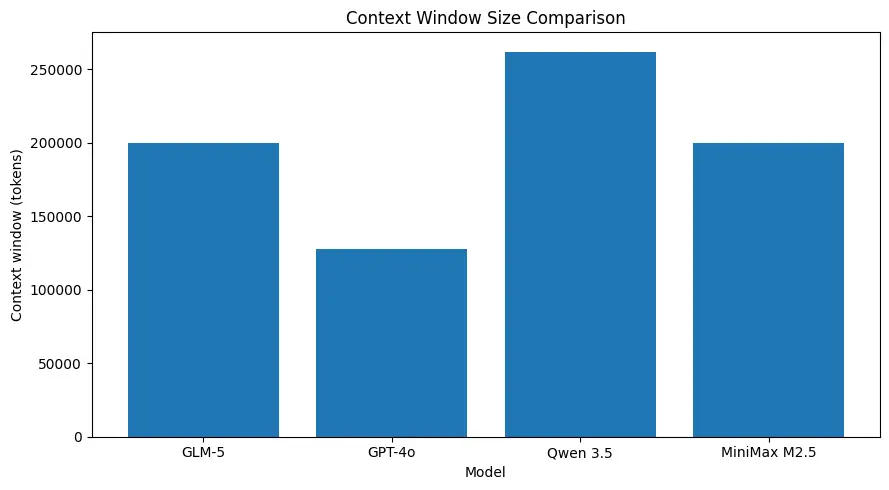
Solides performances en programmation pour des tâches au niveau système
GLM-5 affiche des performances ouvertes de premier plan sur des benchmarks d’ingénierie logicielle (SWE-bench et suites appliquées code + agents). Sur SWE-bench-Verified, il rapporte ~77,8 % ; sur des tests d’agents de style codage/terminal (Terminal-Bench 2.0), les scores se situent au milieu de la tranche des 50 — preuve d’une capacité de programmation pratique approchant les modèles propriétaires de pointe. Ces métriques signifient que GLM-5 convient à des tâches comme la génération de code, le refactoring automatisé, le raisonnement multi-fichiers et des scénarios d’assistance CI/CD.
Compromis coût/efficacité
Parce que GLM-5 utilise le MoE et des innovations d’attention « sparse », il vise à réduire le coût d’inférence par unité de capacité par rapport à un scaling dense « brute force ». CometAPI propose des tarifs compétitifs qui rendent GLM-5 attractif pour des charges agentiques à fort débit.
Comment utiliser l’API GLM-5 via CometAPI ?
Réponse courte : considérez CometAPI comme une passerelle compatible OpenAI — définissez votre URL de base et votre clé API, choisissez glm-5 comme modèle, puis appelez l’endpoint chat/completions. CometAPI fournit une surface REST de style OpenAI (endpoints comme /v1/chat/completions) ainsi que des SDK et des projets d’exemple qui rendent la migration triviale.
Ci-dessous un « cookbook » pratique orienté production : authentification, appel de chat basique, streaming, appel de fonctions/outils et gestion du coût/réponse.
Les étapes de base pour accéder à GLM-5 via CometAPI sont :
- Inscrivez-vous sur CometAPI, obtenez une clé API.
- Trouvez l’identifiant exact du modèle pour GLM-5 dans le catalogue de CometAPI (
"glm-5"selon la liste). - Envoyez une requête POST authentifiée vers l’endpoint chat/completions de CometAPI (style OpenAI).
Détails de base (schémas CometAPI) : la plateforme prend en charge des chemins de type OpenAI comme https://api.cometapi.com/v1/chat/completions, l’authentification Bearer, le paramètre model, des messages system/user, le streaming, et des exemples à la fois en curl/python dans la documentation.
Exemple : complétion de chat Python (requests) rapide avec GLM-5
# Python requests example (blocking)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # store your key securelyURL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # CometAPI model identifier for GLM-5 "messages": [ {"role": "system", "content": "You are a helpful devops assistant."}, {"role": "user", "content": "Create a bash script to backup /etc daily and keep 30 days."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
Exemple : curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Summarize the following architecture doc..." }], "max_tokens": 600 }'
Réponses en streaming (schéma pratique)
CometAPI prend en charge le streaming de style OpenAI (SSE / en chunks). L’approche la plus simple en Python est de demander "stream": true et d’itérer sur les données de la réponse à mesure qu’elles arrivent. C’est important lorsque vous avez besoin d’une sortie partielle à faible latence (construire des assistants dev en temps réel, des interfaces en streaming).
# Streaming (requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Write a test scaffold for the following function..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # Each line is a JSON chunk (OpenAI-compatible). Parse carefully. print(chunk)
Référence : streaming de style OpenAI et documentation de compatibilité CometAPI.
Appel de fonctions / d’outils (comment appeler un outil externe)
GLM-5 prend en charge des schémas d’appel de fonctions ou d’outils compatibles avec les conventions OpenAI / agrégateurs (la passerelle transmet des appels de fonctions structurés dans la réponse du modèle). Exemple d’usage : demander à GLM-5 d’appeler un outil local “run_tests” ; le modèle renvoie une instruction structurée que vous pouvez analyser et exécuter.
# Example request fragment (pseudo-JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"You can call the 'run_tests' tool to run unit tests."}, {"role":"user","content":"Run tests for repo X and summarize failures."} ], "functions": [ {"name":"run_tests","description":"Run pytest in the repo root","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
Quand le modèle renvoie une charge function_call, exécutez l’outil côté serveur, puis réinjectez le résultat de l’outil en tant que message avec le rôle "tool" et reprenez la conversation. Ce schéma permet une invocation d’outils sûre et des flux d’agents avec état. Voir la documentation et les exemples de CometAPI pour des assistants SDK concrets.
Paramètres pratiques et réglages
function_call : utilisez pour activer l’invocation d’outils structurée et des flux d’exécution plus sûrs.
temperature : 0–0,3 pour des sorties déterministes au niveau système (code, infra), plus élevé pour l’idéation.
max_tokens : définissez selon la longueur de sortie attendue ; GLM-5 prend en charge des sorties très longues lorsqu’il est hébergé (les limites des fournisseurs varient).
top_p / nucleus sampling : utile pour limiter les queues improbables.
stream : true pour des interfaces interactives.
Comparaison de GLM-5 avec Claude Opus d’Anthropic et autres modèles de pointe
Réponse courte : GLM-5 réduit l’écart avec les modèles propriétaires de pointe sur les benchmarks agentiques et de programmation tout en offrant un déploiement à poids ouverts et souvent un meilleur coût par jeton lorsqu’il est hébergé par des agrégateurs. Nuance : sur certains benchmarks de programmation absolus (SWE-bench, variantes Terminal-Bench), Claude Opus (4.5/4.6) d’Anthropic reste en tête de quelques points dans de nombreux classements publiés — mais GLM-5 est très compétitif et surpasse de nombreux autres modèles ouverts.
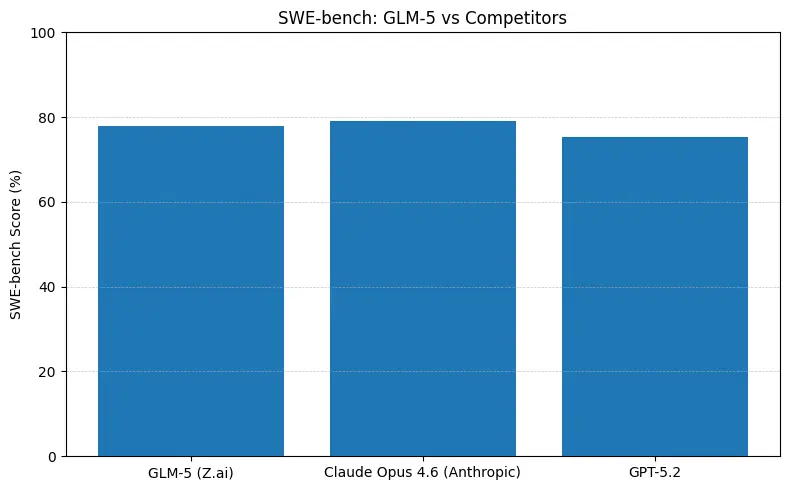
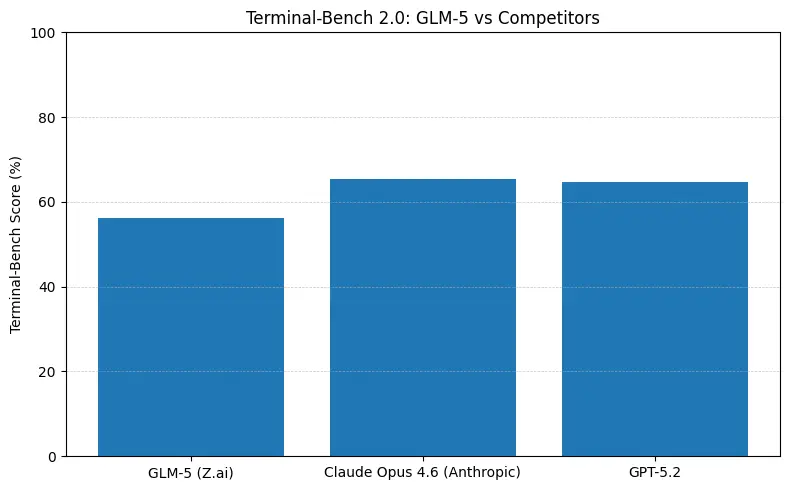
Ce que les chiffres signifient en pratique
- SWE-bench (~correction du code / ingénierie) : Claude Opus montre une avance marginale (≈79 % vs GLM-5 ≈77,8 %) sur les classements publiés ; pour de nombreuses tâches réelles, cet écart se traduira par moins de modifications manuelles, mais pas nécessairement par un choix d’architecture différent pour le prototypage ou des workflows agentiques à l’échelle.
- Terminal-Bench (tâches agentiques en ligne de commande) : Opus 4.6 est en tête (≈65,4 % vs GLM-5 ≈56,2 %) — si vous avez besoin d’une automatisation terminal robuste et de la plus haute fiabilité sur des opérations shell hors distribution, Opus est souvent meilleur à la marge.
- Agentique et long horizon : GLM-5 performe extrêmement bien sur des simulations commerciales à long horizon (Vending-Bench 2 balance 4 432 $ rapportée) et montre une forte cohérence de planification pour des workflows multi-étapes. Si votre produit est un agent de longue durée (finance, opérations), GLM-5 est solide.
Comment concevoir des invites et des systèmes pour obtenir des sorties fiables de GLM-5 ?
Messages système et contraintes explicites
Donnez à GLM-5 un rôle strict et des contraintes, en particulier pour des tâches de code ou d’appel d’outils. Exemple :
{"role":"system","content":"You are GLM-5, an expert engineer. Return concise, tested Python code that follows PEP8 and includes unit tests."}
Demandez des tests et un court raisonnement pour chaque modification non triviale.
Décomposer les tâches complexes
Plutôt que « écrire le produit complet », demandez :
- l’ossature de conception,
- les signatures d’interface,
- l’implémentation et les tests,
- le script d’intégration final.
Cette décomposition étape par étape réduit les hallucinations et fournit des points de contrôle déterministes que vous pouvez valider.
Utiliser une faible température pour un code déterministe
Lorsque vous demandez du code, réglez temperature sur 0–0,2 et max_tokens sur une borne supérieure sûre. Pour l’écriture créative ou le brainstorming de conception, augmentez la température.
Bonnes pratiques lors de l’intégration de GLM-5 (via CometAPI ou hébergeurs directs)
Ingénierie de l’invite et invites système
- Utilisez des instructions system explicites qui définissent les rôles des agents, les politiques d’accès aux outils et les contraintes de sécurité. Exemple : « Vous êtes un architecte système : ne proposez des changements que lorsque les tests unitaires réussissent localement ; listez les commandes CLI exactes à exécuter. »
- Pour les tâches de codage, fournissez le contexte du dépôt (liste des fichiers, extraits de code clés) et joignez les sorties des tests unitaires si disponibles. La gestion du long contexte de GLM-5 aide — mais gardez toujours le contexte essentiel en premier (rôle, tâche) puis les artefacts de support.
Gestion de session et d’état
- Utilisez des IDs de session pour les conversations d’agent longues et conservez une « mémoire » compactée des étapes précédentes (résumés) pour éviter le gonflement du contexte. CometAPI et des passerelles similaires fournissent des aides de session/état — mais la compaction d’état au niveau application est essentielle pour des agents longue durée.
Outils et appels de fonctions (sécurité + fiabilité)
- Exposez un ensemble d’outils restreint et auditable. N’autorisez pas l’exécution shell arbitraire sans supervision humaine. Utilisez des définitions de fonctions structurées et validez leurs arguments côté serveur.
- Journalisez toujours les appels d’outils et les réponses du modèle pour la traçabilité et le debugging post-mortem.
Contrôle des coûts et traitement par lots
- Pour des agents à fort volume, routez les traitements d’arrière-plan vers des variantes de modèle moins coûteuses lorsque les compromis de qualité sont acceptables (CometAPI permet de basculer les modèles par nom). Regroupez les requêtes similaires et réduisez
max_tokenslorsque c’est possible. Surveillez le ratio jetons d’entrée vs de sortie — les jetons de sortie sont souvent plus chers.
Ingénierie de la latence et du débit
- Utilisez le streaming pour des sessions interactives. Pour des travaux d’agents en arrière-plan, privilégiez des runtimes asynchrones, des files de travailleurs et des limiteurs de débit. Si vous auto-hébergez (poids ouverts), adaptez votre topologie d’accélérateur à l’architecture MoE — des options FPGA / Ascend / silicium spécialisé peuvent offrir des gains de coût.
Notes finales
GLM-5 représente une avancée pratique à poids ouverts vers l’ingénierie agentique : grandes fenêtres de contexte, capacités de planification et solides performances en code le rendent attractif pour des outils développeurs, l’orchestration d’agents et l’automatisation au niveau système. Utilisez CometAPI pour une intégration rapide ou un « model garden » cloud pour un hébergement géré ; validez toujours sur votre charge et instrumentez fortement pour le contrôle des coûts et des hallucinations.
Les développeurs peuvent accéder à GLM-5 via CometAPI dès maintenant. Pour commencer, explorez les capacités du modèle dans le Playground et consultez le Guide de l’API pour des instructions détaillées. Avant d’y accéder, assurez-vous de vous être connecté à CometAPI et d’avoir obtenu la clé API. CometAPI propose un prix bien inférieur au prix officiel pour vous aider à intégrer.
Prêt à démarrer ? → Inscrivez-vous à M2.5 dès aujourd’hui !
Si vous voulez davantage de conseils, guides et actualités sur l’IA, suivez-nous sur VK, X et Discord !