

L'entreprise chinoise Z.ai (anciennement Zhipu AI) a une fois de plus fait la une des journaux avec le lancement de sa série open source GLM 4.5. Se positionnant comme une alternative économique et performante aux grands modèles de langage existants, GLM-4.5 promet de remodeler l'économie des jetons et de démocratiser l'accès pour les startups, les entreprises et les instituts de recherche. Cet article complet explore les origines, la structure tarifaire et la valeur réelle de la série GLM-4.5, en abordant les deux questions clés que se posent tous les acteurs : quel est son coût et est-ce rentable ?
Qu'est-ce que la série GLM 4.5 ?
La série GLM 4.5 de Z.ai repose sur un framework d'IA « agentique », ce qui signifie que le modèle peut décomposer de manière autonome des tâches complexes en sous-tâches séquentielles plus petites, améliorant ainsi la précision et réduisant les calculs redondants. Cela contraste avec les LLM plus monolithiques qui gèrent les requêtes en une seule passe. Selon Z.ai, GLM 4.5 intègre nativement le raisonnement et la planification d'actions dans son architecture principale, permettant des workflows en plusieurs étapes, tels que la génération de visualisations de données ou le traitement de documents de bout en bout, sans orchestration externe.
La série GLM 4.5, développée par Z.ai, représente la dernière génération de grands modèles de langage open source, Mixture of Experts (MoE), conçus pour unifier le raisonnement avancé, la génération de code et les capacités agentiques au sein d'une architecture unique. Elle se décline en deux versions principales : la version phare GLM 4.5 (355 B paramètres au total, 32 B actifs) et le plus léger GLM 4.5‑Air (106 B au total, 12 B actifs). Les deux variantes exploitent un mécanisme d'inférence hybride : un « mode de réflexion » pour un raisonnement complexe assisté par des outils et un « mode sans réflexion » pour des complétions rapides et simples, répondant à un large éventail de cas d'utilisation, du développement full-stack aux flux de travail d'agents autonomes.
spécifications techniques de base :
- Paramètres:GLM 4.5 comprend 355 milliards de paramètres, avec un sous-ensemble actif de 32 milliards engagés par inférence pour optimiser l'utilisation du matériel et le débit.
- Mélange d'experts (MoE):La série exploite l'architecture MoE, acheminant les jetons vers des sous-réseaux experts de manière dynamique pour plus d'efficacité.
- Fenêtre contextuelle: Étendu à 128 K jetons sur certaines plates-formes (par exemple, SiliconFlow), prenant en charge les documents et les bases de code volumineux.
- Vitesse de génération:Les variantes à grande vitesse dépassent 100 jetons/s, adaptées aux applications en temps réel.
- Modes d'inférence hybrides:Les utilisateurs peuvent basculer entre le mode « réflexion » (activation complète du MoE pour un raisonnement approfondi) et le mode « non-réflexion » (activation minimale pour des réponses rapides et à la volée), offrant aux développeurs un contrôle précis sur les performances par rapport à la vitesse.
Quelles variantes existent au sein de la série ?
- GLM 4.5 (Standard): 355 B au total / 32 B paramètres actifs. Conçu principalement pour des performances équilibrées entre les tâches de raisonnement, de codage et d'agent.
- GLM 4.5‑Air:Une version légère de 106 B au total / 12 B de paramètres actifs, adaptée aux scénarios avec des contraintes matérielles ou de latence strictes, offrant une précision compétitive dans sa catégorie.
Combien coûte la série GLM 4.5 ?
Quels sont les prix des jetons d'entrée et de sortie ?
Selon les informations publiques sur les prix de l'API de Z.ai, le prix de GLM 4.5 est le suivant :
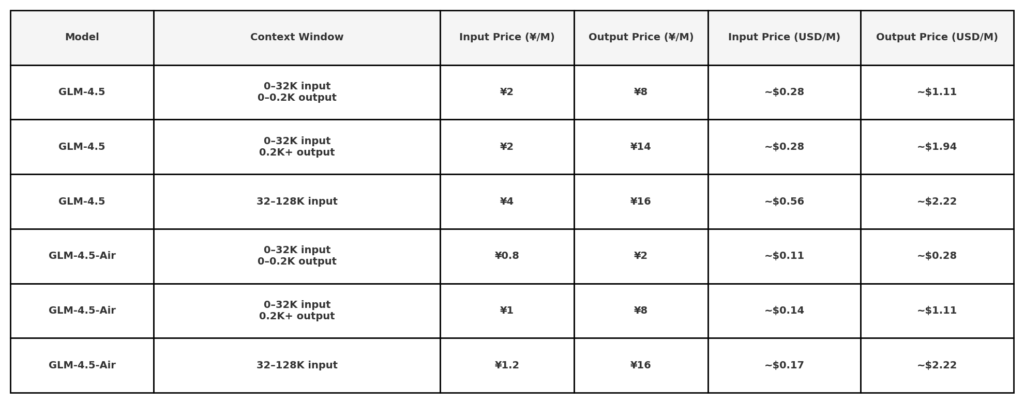
Remarque : les tarifs très bas (0.11 $/0.28 $) peuvent être limités à de petites durées de jetons ou à des promotions spécifiques. 50 % de réduction sur tous les modèles pour une durée limitée, valable jusqu'au 31 août 2025. Pour tout autre modèle, consultez page de prix du bureau.
Sur CometAPI, la série est proposée avec une tarification à plusieurs niveaux légèrement différente, reportez-vous à API GLM-4.5:
| Modèle | introduire | Prix |
glm-4.5 | Notre modèle de raisonnement le plus puissant, avec 355 milliards de paramètres | Jetons d'entrée 0.48 $ Jetons de sortie 1.92 $ |
glm-4.5-air | Rentable Léger Performances élevées | Jetons d'entrée 0.16 $ Jetons de sortie 1.07 $ |
glm-4.5-x | Haute performance Raisonnement puissant Réponse ultra-rapide | Jetons d'entrée 1.60 $ Jetons de sortie 6.40 $ |
glm-4.5-airx | Léger, performant et ultra-rapide | Jetons d'entrée 0.02 $ Jetons de sortie 0.06 $ |
glm-4.5-flash | Excellentes performances pour le codage du raisonnement et les agents | Jetons d'entrée 3.20 $ Jetons de sortie 12.80 $ |
Comment les prix de GLM 4.5 se comparent-ils à ceux de DeepSeek et des LLM occidentaux ?
Lors de la Conférence mondiale sur l'IA de 2025, Z.ai a explicitement positionné GLM 4.5 comme un challenger de DeepSeek, l'ancien leader des coûts en Chine, promettant « une fraction du coût du jeton » et la moitié de l'empreinte matérielle du modèle R1 de DeepSeek.
- DeepSeek R1:Environ 0.14 USD en entrée, 0.60 USD en sortie par million de jetons.
- GLM 4.5:Il prétendait sous-coter DeepSeek de 20 à 30 % en entrée et en sortie.
- Repères occidentaux:GPT-4 d'OpenAI et Gemini de Google coûtent entre 3 et 15 USD par million de jetons, positionnant GLM 4.5 comme une réduction des coûts d'un ordre de grandeur.
Cette stratégie de prix reflète le modèle économique plus large de l'IA en Chine : des capacités de calcul plus légères, des modèles plus petits et une sous-cotation agressive pour conquérir des parts de marché.
La série GLM 4.5 en vaut-elle la peine ?
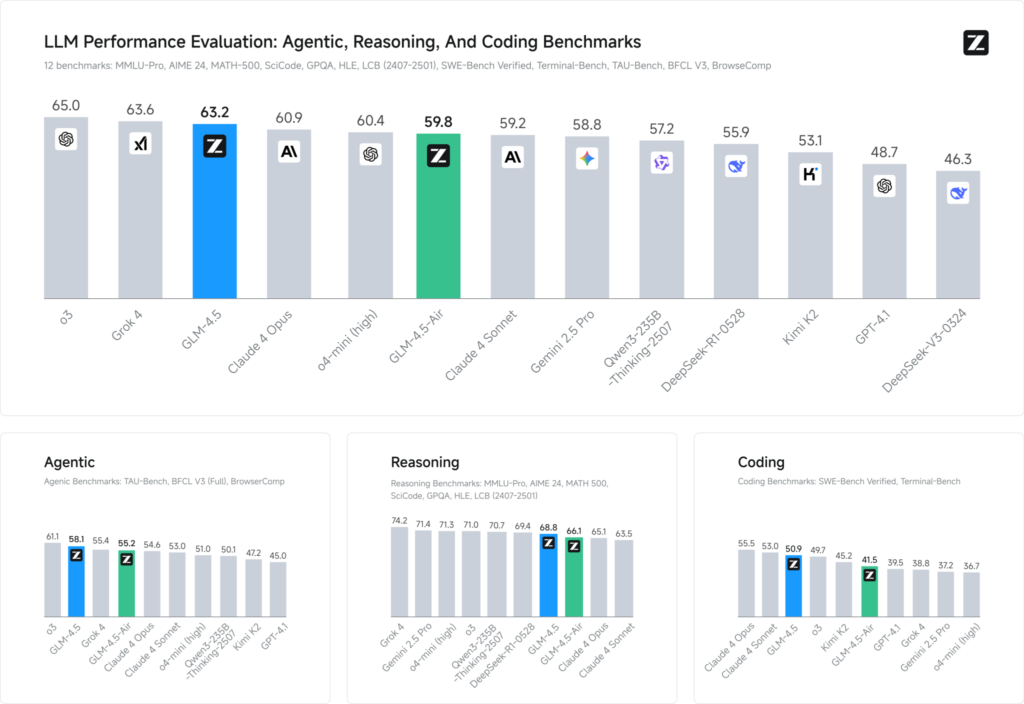
Les évaluations comparatives sur 12 ensembles de données représentatifs (couvrant MMLU Pro, MATH 500, SciCode, Terminal-Bench et TAU-Bench) révèlent que GLM 4.5 obtient un classement mondial n° 3 derrière Grok 4 de xAI et o3 d'OpenAI, tout en se classant n° 1 parmi les offres open source.
Pour les tâches de codage (LiveCodeBench, SWE-Bench), la conception « Mixture-of-Experts » de GLM 4.5 contribue à une qualité de génération de code optimale, tandis qu'en raisonnement (AIME 24, MMLU Pro), sa planification en plusieurs étapes offre une précision robuste comparable à celle de ses homologues à code source fermé. La variante légère Air maintient des scores compétitifs dans sa fourchette de paramètres (échelle 100 B), ce qui en fait un choix attrayant pour les déploiements en périphérie et les systèmes embarqués.
Benchmarks de Performance
- Indice de renseignement: Score GLM 4.5 66 sur un indice d'intelligence composite (MMLU Pro, MATH 500, AIME 24), surpassant de nombreux modèles open source et commerciaux de niveau intermédiaire.
- Latence d'inférence: Moyennes du temps jusqu'au premier jeton 0.89 s, compétitif pour les tâches de raisonnement complexes, bien que légèrement plus lent en termes de débit (≈45.7 jetons/s) par rapport à certains modèles optimisés à source fermée.
- Workflow agentique: Démontre une solide maîtrise de l'utilisation d'outils en plusieurs étapes et de la génération de code dynamique, avec des taux de réussite en tête-à-tête de ~54% contre Kimi K2 et 81 % contre Qwen3-Coder dans les évaluations de codage indépendantes.
Quels cas d’utilisation pratiques illustrent le retour sur investissement ?
- Développement Full-Stack: GLM‑4.5 peut échafauder des applications Web entières, depuis les mises en page frontales en HTML/CSS/JavaScript jusqu'aux schémas de base de données back-end, via des invites multi-tours, réduisant ainsi les cycles de prototypage de plusieurs jours à quelques heures.
- Analyse de documents complexes:La fenêtre de contexte étendue de 128 K permet aux entreprises juridiques, financières et scientifiques d'analyser des contrats de plusieurs pages ou des rapports de recherche en une seule fois, réduisant ainsi les frais de segmentation.
- Flux de travail automatisés des agents:L'inférence hybride permet la création de scripts autonomes (par exemple, des robots de scraping Web, des agents commerciaux) qui raisonnent à travers des processus en plusieurs étapes avec une intervention humaine minimale.
Des études de cas quantitatives suggèrent jusqu'à 60 pour cent réduction des heures de développement pour les tâches centrées sur le code et 40 pour cent un délai d’exécution plus rapide pour l’analyse de contenu long.
Quels sont les inconvénients et les considérations potentiels ?
Aucune technologie n'est exempte de compromis. Les futurs adoptants doivent être attentifs aux facteurs réglementaires, opérationnels et écosystémiques.
Limites
Assistance et SLA:Les fournisseurs open source peuvent ne pas proposer de SLA de niveau entreprise ni d’assistance 24h/7 et XNUMXj/XNUMX, contrairement à leurs homologues commerciaux.
Contraintes de débit:Bien que la fenêtre de contexte soit énorme, les taux de jetons par seconde sont inférieurs à ceux de certains homologues à source fermée optimisés pour l'inférence, ce qui peut affecter les applications en temps réel.
Frais généraux opérationnels:Les modèles MoE auto-hébergés nécessitent une orchestration minutieuse (routage expert, gestion de la mémoire) pour éviter les goulots d'étranglement des performances et les dépassements de coûts.
Quels investissements en infrastructures sont nécessaires ?
- Empreinte de calcul : Même avec l'efficacité du MoE, l'hébergement de la variante standard de GLM-4.5 nécessite des GPU avec ≥ 80 Go de mémoire et des interconnexions NVLink robustes pour une inférence à faible latence.
- Frais généraux de réglage fin : La personnalisation du modèle pour des tâches spécifiques à un domaine peut nécessiter des cycles GPU substantiels, ce qui augmente les coûts initiaux avant que les économies de facturation des jetons ne se matérialisent.
- Entretien: Les déploiements sur site transfèrent la responsabilité des mises à jour, des correctifs de sécurité et de la mise à l’échelle du fournisseur aux équipes DevOps internes.
Comment démarrer avec GLM-4.5 ?
Se lancer dans une intégration GLM-4.5 implique quelques étapes simples, en particulier compte tenu du manuel open source et du support tiers étendu.
Quelles API et plateformes prennent en charge GLM‑4.5 ?
- API Comet API:Point de terminaison entièrement compatible avec OpenAI, doté de SDK en Python, JavaScript et Java.
- Point de terminaison direct Z.ai: Offre un support officiel et des fonctionnalités d'accès anticipé telles que l'orchestration multi-agents.
- Miroirs communautaires:Hôte en croissance rapide d'environnements d'exécution open source (par exemple, Ollama, AutoGPT-CLI) qui permettent l'inférence locale.
Où les développeurs peuvent-ils trouver des outils et de la documentation ?
- Documents officiels de Z.ai : Guides complets sur l'installation, l'ingénierie rapide et l'optimisation du MoE.
- Dépôts GitHub : Exemples de blocs-notes pour la génération de code, la génération augmentée de récupération (RAG) et les frameworks d'agents compatibles avec les principaux outils d'orchestration.
- Forums communautaires: Forums de discussion actifs sur des plateformes comme Hugging Face, où les praticiens partagent des recettes de réglage fin, des bibliothèques d'invites et des repères de performance.
Conclusion
La série GLM‑4.5 revendique un potentiel de croissance important dans le paysage ultra-concurrentiel de l'IA : un rapport coût-performance inégalé pour les développeurs, les entreprises et les instituts de recherche. Avec des prix de jetons aussi bas que 0.11 $ par million de jetons d'entrée et 0.28 $ par million de jetons de sortie (réduction supplémentaire de 50 %) et des performances de référence rivalisant, voire dépassant, avec les modèles propriétaires plus importants, GLM‑4.5 offre un retour sur investissement substantiel pour les applications centrées sur le code, la compréhension détaillée et les workflows agentiques.
Pour commencer
CometAPI est une plateforme d'API unifiée qui regroupe plus de 500 modèles d'IA provenant de fournisseurs leaders, tels que la série GPT d'OpenAI, Gemini de Google, Claude d'Anthropic, Midjourney, Suno, etc., au sein d'une interface unique et conviviale pour les développeurs. En offrant une authentification, un formatage des requêtes et une gestion des réponses cohérents, CometAPI simplifie considérablement l'intégration des fonctionnalités d'IA dans vos applications. Que vous développiez des chatbots, des générateurs d'images, des compositeurs de musique ou des pipelines d'analyse pilotés par les données, CometAPI vous permet d'itérer plus rapidement, de maîtriser les coûts et de rester indépendant des fournisseurs, tout en exploitant les dernières avancées de l'écosystème de l'IA.
Les développeurs peuvent accéder API GLM-4.5 Air et API GLM-4.5 à travers API CometLes dernières versions des modèles Claude répertoriées sont celles à la date de publication de l'article. Pour commencer, explorez les fonctionnalités du modèle dans le cour de récréation et consultez le Guide de l'API Pour des instructions détaillées, veuillez vous connecter à CometAPI et obtenir la clé API avant d'y accéder. API Comet proposer un prix bien inférieur au prix officiel pour vous aider à vous intégrer.