

La série GLM-4.5, développée par Zhipu AI (Z.ai), représente une avancée significative dans le domaine des grands modèles de langage (LLM) open source. Conçue pour unifier le raisonnement, le codage et les capacités d'agent, GLM-4.5 offre des performances robustes pour diverses applications. Que vous soyez développeur, chercheur ou passionné, ce guide vous explique en détail comment accéder et utiliser efficacement la série GLM-4.5.
Qu'est-ce que la série GLM-4.5 et pourquoi est-elle importante ?
GLM-4.5 est un modèle de raisonnement hybride combinant deux modes distincts : un « mode pensée » pour le raisonnement complexe et l'utilisation d'outils, et un « mode non pensée » pour les réponses immédiates. Cette approche bimodale permet au modèle de gérer efficacement un large éventail de tâches. La série comprend deux variantes principales :
- GLM-4.5:Avec 355 milliards de paramètres au total avec 32 milliards de paramètres actifs, ce modèle est conçu pour un déploiement à grande échelle dans les tâches de raisonnement, de génération et multi-agents.
- GLM-4.5-Air:Une version légère avec 106 milliards de paramètres au total et 12 milliards de paramètres actifs, optimisée pour l'inférence cloud sur l'appareil et à plus petite échelle sans sacrifier les capacités de base.
Les deux modèles prennent en charge les modes de raisonnement hybrides, offrant des modes « pensée » et « non pensée » pour équilibrer les tâches de raisonnement complexes et les réponses rapides. Ils sont open source et publiés sous la licence MIT, ce qui les rend accessibles à un usage commercial et au développement secondaire.
Principes d'architecture et de conception
Fondamentalement, GLM-4.5 exploite le MoE pour acheminer dynamiquement les jetons via des sous-réseaux experts spécialisés, ce qui permet une efficacité des paramètres et une évolutivité supérieures (). Cette approche réduit le nombre de paramètres à activer par passe, ce qui réduit les coûts opérationnels tout en maintenant des performances de pointe pour les tâches de raisonnement et de codage ().
Capacités clés
- Raisonnement et codage hybrides:GLM-4.5 démontre les performances de SOTA à la fois sur les tests de compréhension du langage naturel et sur les tests de génération de code, rivalisant souvent avec les modèles propriétaires en termes de précision et de fluidité.
- Intégration agentique:Les interfaces d'appel d'outils intégrées permettent à GLM-4.5 d'orchestrer des flux de travail en plusieurs étapes, tels que des requêtes de base de données, l'orchestration d'API et la génération de front-end interactif, au sein d'une seule session.
- Artefacts multimodaux:Des mini-applications HTML/CSS aux simulations basées sur Python et aux SVG interactifs, GLM-4.5 peut générer des artefacts entièrement fonctionnels, améliorant l'engagement des utilisateurs et la productivité des développeurs.
Pourquoi GLM-4.5 est-il un changement de donne ?
GLM-4.5 a été salué non seulement pour ses performances brutes, mais également pour avoir redéfini la proposition de valeur des LLM open source dans les environnements d'entreprise et de recherche.
Benchmarks de Performance
Lors d'évaluations indépendantes portant sur 52 tâches de programmation, couvrant le développement web, l'analyse de données et l'automatisation, GLM-4.5 a systématiquement surpassé les autres principaux modèles open source en termes de fiabilité des appels d'outils et d'exécution globale des tâches. Lors de tests comparatifs avec Claude Code, Kimi-K2 et Qwen3-Coder, GLM-4.5 a obtenu les meilleurs scores de sa catégorie sur des benchmarks tels que le classement « SWE-bench Verified ».
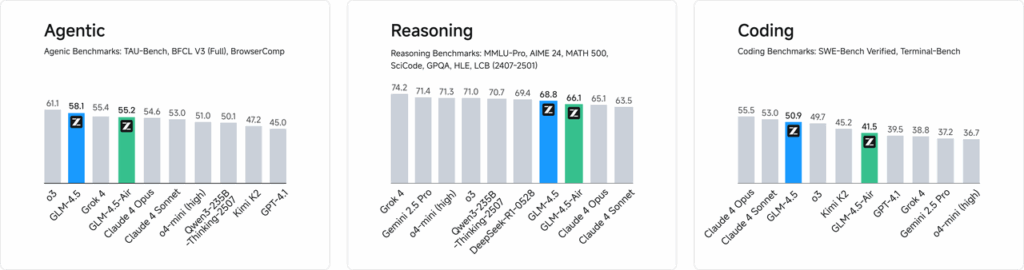
Efficacité des coûts
Au-delà de la précision, la conception MoE de GLM-4.5 réduit considérablement les coûts d'inférence. Les prix publics des appels d'API démarrent à 0.8 RMB par million de jetons d'entrée et 2 RMB par million de jetons de sortie, soit environ un tiers du coût des offres propriétaires comparables. Associé à des vitesses de génération maximales de 100 jetons/s, le modèle prend en charge des déploiements à haut débit et à faible latence sans coûts prohibitifs.
Comment accéder à GLM-4.5 ?
1. Accès direct via la plateforme Z.ai
La méthode la plus simple pour interagir avec GLM-4.5 est d'utiliser la plateforme Z.ai. En visitant chat.z.aiLes utilisateurs peuvent sélectionner le modèle GLM-4.5 et commencer à interagir via une interface conviviale. Cette plateforme permet des tests et un prototypage immédiats, sans intégration complexe. Les utilisateurs peuvent sélectionner le modèle GLM-4.5 ou GLM-4.5-Air en haut à gauche et commencer à discuter immédiatement. Cette interface conviviale et sans configuration est idéale pour des interactions et des démonstrations rapides.
2. Accès API pour les développeurs
Pour les développeurs souhaitant intégrer GLM-4.5 à leurs applications, la plateforme API Z.ai offre un support complet. L'API propose des interfaces compatibles OpenAI pour les modèles GLM-4.5 et GLM-4.5-Air, facilitant ainsi une intégration fluide aux workflows existants. Une documentation détaillée et des instructions d'intégration sont disponibles à l'adresse suivante : Documentation de l'API Z.ai .
3. Déploiement open source
Pour ceux qui s'intéressent au déploiement local, les modèles GLM-4.5 sont disponibles sur des plateformes comme Hugging Face et ModelScope. Ces modèles sont publiés sous licence open source du MIT, ce qui permet une utilisation commerciale et un développement secondaire. Ils peuvent être intégrés aux principaux frameworks d'inférence tels que vLLM et SGLang.
4. Intégration avec CometAPI
API Comet offre un accès simplifié aux modèles GLM-4.5 via leur plateforme API unifiée à Tableau de bordCette intégration simplifie l'authentification, la limitation du débit et la gestion des erreurs, ce qui en fait un excellent choix pour les développeurs recherchant une configuration simple. De plus, le format d'API standardisé de CometAPI facilite le changement de modèle et les tests A/B entre GLM-4.5 et les autres modèles disponibles.
Comment les développeurs peuvent-ils accéder à la série GLM-4.5 ?
Il existe plusieurs canaux pour obtenir et déployer GLM-4.5, des téléchargements directs de modèles aux API gérées.
Via Hugging Face et ModelScope
Hugging Face et ModelScope hébergent tous deux l'intégralité de la série GLM-4.5 sous l'espace de noms zai-org. Après avoir accepté la licence MIT, les développeurs peuvent :
- Cloner le référentiel:
git clone https://huggingface.co/zai-org/GLM-4.5
- Installer les dépendances:
pip install transformers accelerate
- Charger le modèle:
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("zai-org/GLM-4.5")
model = AutoModelForCausalLM.from_pretrained("zai-org/GLM-4.5")
``` :contentReference{index=15}.
Via CometAPI
API Comet fournit une API sans serveur pour GLM-4.5 et API GLM-4.5 Air à des tarifs de paiement par jeton, accessibles via, en configurant des points de terminaison compatibles OpenAI, vous pouvez appeler GLM-4.5 via le client Python d'OpenAI avec des ajustements minimes aux bases de code existantes. CometAPI fournit non seulement GLM4.5 et GLM-4.5-air mais également tous les modèles officiels :
| Nom du modèle | introduire | Prix |
glm-4.5 | Notre modèle de raisonnement le plus puissant, avec 355 milliards de paramètres | Jetons d'entrée 0.48 $ Jetons de sortie 1.92 $ |
glm-4.5-air | Rentable Léger Performances élevées | Jetons d'entrée 0.16 $ Jetons de sortie 1.07 $ |
glm-4.5-x | Haute performance Raisonnement puissant Réponse ultra-rapide | Jetons d'entrée 1.60 $ Jetons de sortie 6.40 $ |
glm-4.5-airx | Léger, performant et ultra-rapide | Jetons d'entrée 0.02 $ Jetons de sortie 0.06 $ |
glm-4.5-flash | Excellentes performances pour le codage du raisonnement et les agents | Jetons d'entrée 3.20 $ Jetons de sortie 12.80 $ |
Intégration Python et API REST
Pour des déploiements sur mesure, les entreprises peuvent héberger GLM-4.5 sur des clusters GPU dédiés utilisant Docker ou Kubernetes. Une configuration RESTful typique comprend :
Lancement du serveur d'inférence:
bashdocker run -p 8000:8000 zai-org/glm-4.5:latest
Envoi de demandes:
bashcurl -X POST http://localhost:8000/generate \ -H "Content-Type: application/json" \ -d '{"prompt": "Translate to French: Hello.", "max_tokens": 50}' Responses conform to the JSON formats used by popular LLM APIs .
Quelles sont les meilleures pratiques pour intégrer GLM-4.5 dans les applications ?
Pour maximiser le retour sur investissement et garantir des performances solides, les équipes doivent prendre en compte les éléments suivants :
Optimisation de l'API et limites de débit
- Requêtes par lots: Regroupez des invites similaires pour réduire les frais généraux et exploiter le débit du GPU.
- Mise en cache des requêtes courantes: Stockez les complétions fréquentes localement pour éviter les appels d'inférence redondants.
- Échantillonnage adaptatif: Ajuster dynamiquement
temperatureettop_pbasé sur la complexité des requêtes pour équilibrer créativité et déterminisme.
Sécurité et conformité
- Assainissement des données: Prétraiter les entrées pour supprimer les informations sensibles avant de les envoyer au modèle.
- Contrôle d'Accès: Implémentez des clés API, des listes d'autorisation IP et une limitation du débit pour éviter toute utilisation abusive.
- Enregistrement d'audit:Enregistrez les invites, les complétions et les métadonnées pour vous conformer aux exigences de l'entreprise et réglementaires, en particulier dans les contextes financiers ou de santé.
Pour commencer
CometAPI est une plateforme d'API unifiée qui regroupe plus de 500 modèles d'IA provenant de fournisseurs leaders, tels que la série GPT d'OpenAI, Gemini de Google, Claude d'Anthropic, Midjourney, Suno, etc., au sein d'une interface unique et conviviale pour les développeurs. En offrant une authentification, un formatage des requêtes et une gestion des réponses cohérents, CometAPI simplifie considérablement l'intégration des fonctionnalités d'IA dans vos applications. Que vous développiez des chatbots, des générateurs d'images, des compositeurs de musique ou des pipelines d'analyse pilotés par les données, CometAPI vous permet d'itérer plus rapidement, de maîtriser les coûts et de rester indépendant des fournisseurs, tout en exploitant les dernières avancées de l'écosystème de l'IA.
Pour les développeurs souhaitant intégrer GLM-4.5 à leurs applications, la plateforme CometAPI offre une solution robuste. L'API propose des interfaces compatibles OpenAI, permettant une intégration transparente aux workflows existants. Une documentation détaillée et des instructions d'utilisation sont disponibles sur le site. Page API Comet.
Les développeurs peuvent accéder GLM-4.5 et API GLM-4.5 Air à travers API CometLes dernières versions des modèles répertoriés sont celles en vigueur à la date de publication de l'article. Pour commencer, explorez les fonctionnalités du modèle dans la section cour de récréation et consultez le Guide de l'API Pour des instructions détaillées, veuillez vous connecter à CometAPI et obtenir la clé API avant d'y accéder. API Comet proposer un prix bien inférieur au prix officiel pour vous aider à vous intégrer.
Conclusion
GLM-4.5 représente une avancée significative dans le domaine des grands modèles de langage, offrant une solution polyvalente pour un large éventail d'applications. Son architecture de raisonnement hybride, ses capacités d'agent et son caractère open source en font une option attrayante pour les développeurs et les organisations souhaitant exploiter les technologies d'IA avancées. En explorant les différentes méthodes d'accès décrites dans ce guide, les utilisateurs peuvent intégrer efficacement GLM-4.5 à leurs projets et contribuer à son développement continu.