

Démarrer avec Gemini 2.5 Flash-Lite via CometAPI est une excellente occasion d'exploiter l'un des modèles d'IA générative les plus économiques et à faible latence disponibles aujourd'hui. Ce guide regroupe les dernières annonces de Google DeepMind, les spécifications détaillées de la documentation Vertex AI et des étapes pratiques d'intégration avec CometAPI pour vous aider à être opérationnel rapidement et efficacement.
Qu'est-ce que Gemini 2.5 Flash-Lite et pourquoi devriez-vous l'envisager ?
Présentation de la famille Gemini 2.5
Mi-juin 2025, Google DeepMind a officiellement lancé la série Gemini 2.5, comprenant les versions GA stables de Gemini 2.5 Pro et Gemini 2.5 Flash, ainsi qu'un aperçu d'un tout nouveau modèle léger : Gemini 2.5 Flash-Lite. Conçue pour allier vitesse, coût et performances, la série 2.5 illustre la volonté de Google de répondre à un large éventail de cas d'utilisation, des charges de travail de recherche intensives aux déploiements à grande échelle et économiques.
Caractéristiques principales de Flash-Lite
Flash-Lite se distingue par ses capacités multimodales (texte, images, audio, vidéo) à latence extrêmement faible, avec une fenêtre contextuelle prenant en charge jusqu'à un million de jetons et des intégrations d'outils, notamment la recherche Google, l'exécution de code et l'appel de fonctions. Point essentiel, Flash-Lite introduit le contrôle du « budget de réflexion », permettant aux développeurs de concilier profondeur de raisonnement, temps de réponse et coût, en ajustant un paramètre interne de budget de jetons.
Positionnement dans la gamme de modèles
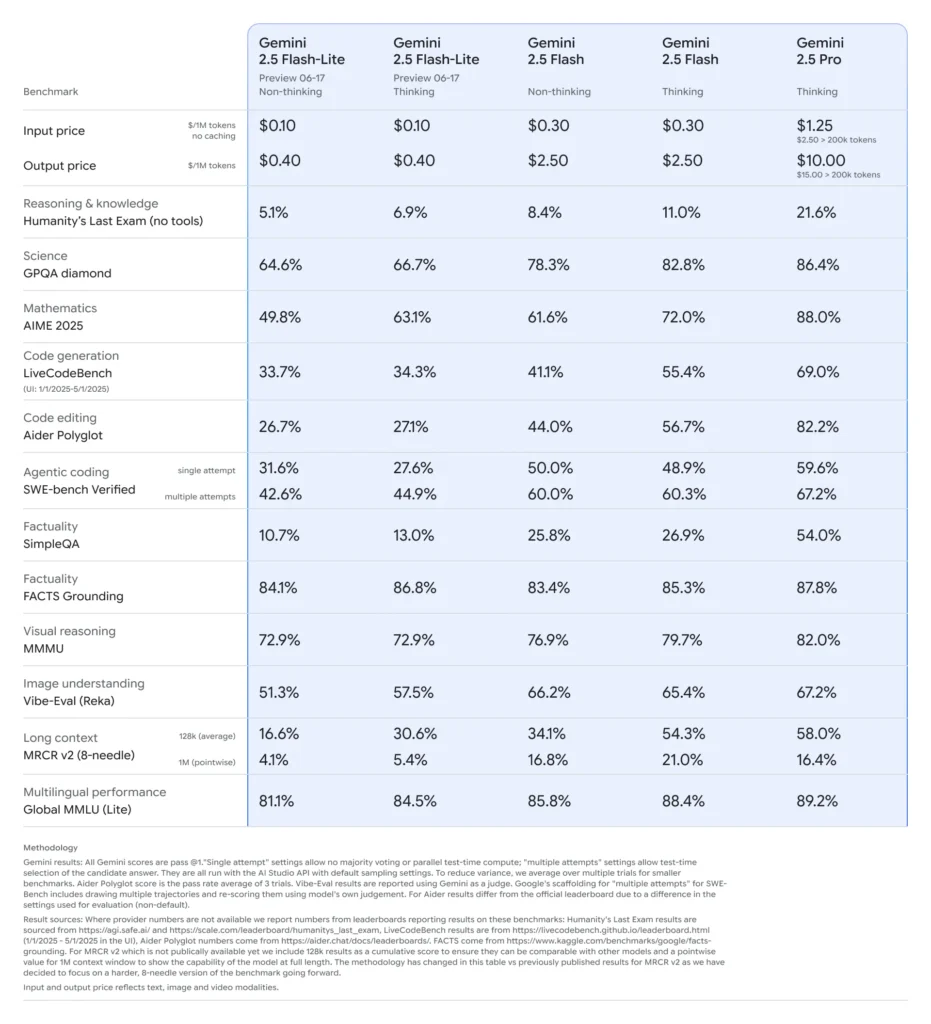
Comparé à ses homologues, Flash-Lite se situe à la frontière de Pareto en termes de rentabilité : avec un prix d'environ 0.10 $ par million de jetons d'entrée et 0.40 $ par million de jetons de sortie en version préliminaire, il est moins cher que Flash (à 0.30 $/2.50 $) et Pro (à 1.25 $/10 $), tout en conservant l'essentiel de leurs capacités multimodales et de leur prise en charge des appels de fonctions. Flash-Lite est donc idéal pour les tâches volumineuses et peu complexes, telles que la synthèse, la classification et les agents conversationnels légers.
Pourquoi les développeurs devraient-ils envisager Gemini 2.5 Flash-Lite ?
Tests de performance et tests en conditions réelles
Dans des comparaisons directes, Flash-Lite a démontré :
- Débit 2 fois plus rapide que Gemini 2.5 Flash sur les tâches de classification.
- 3× d'économies de coûts pour les pipelines de synthèse à l'échelle de l'entreprise.
- Précision compétitive sur les benchmarks de logique, de mathématiques et de code, égalant ou dépassant les aperçus Flash-Lite précédents.
Cas d'utilisation idéaux
- Chatbots à haut volume: Offrez des expériences conversationnelles cohérentes et à faible latence à des millions d'utilisateurs.
- Génération de contenu automatisée:Résumé de documents à l'échelle, traduction et création de microcopies.
- Pipelines de recherche et de recommandation: Tirez parti de l’inférence rapide pour une personnalisation en temps réel.
- Traitement de données par lots: Annotez de grands ensembles de données avec des coûts de calcul minimes.
Comment obtenir et gérer l'accès API pour Gemini 2.5 Flash-Lite via CometAPI ?
Pourquoi utiliser CometAPI comme passerelle ?
CometAPI regroupe plus de 500 modèles d'IA, dont la série Gemini de Google, sous un point de terminaison REST unifié, simplifiant ainsi l'authentification, la limitation de débit et la facturation entre les fournisseurs. Plutôt que de jongler avec plusieurs URL de base et clés API, vous pointez toutes les requêtes vers https://api.cometapi.com/v1, spécifiez le modèle cible dans la charge utile et gérez l'utilisation via un tableau de bord unique.
Prérequis et inscription
- Se connecter à cometapi.comSi vous n'êtes pas encore notre utilisateur, veuillez d'abord vous inscrire
- Obtenez la clé API d'accès à l'interface. Cliquez sur « Ajouter un jeton » au niveau du jeton API dans l'espace personnel, récupérez la clé : sk-xxxxx et validez.
- Obtenez l'URL de ce site : https://api.cometapi.com/
Gérer vos jetons et vos quotas
Le tableau de bord de CometAPI fournit des quotas de jetons unifiés, partageables entre Google, OpenAI, Anthropic et d'autres modèles. Utilisez les outils de surveillance intégrés pour définir des alertes d'utilisation et des limites de débit afin de ne jamais dépasser les allocations budgétisées ni engendrer de frais imprévus.
Comment configurer votre environnement de développement pour l'intégration de CometAPI ?
Installation des dépendances requises
Pour l’intégration Python, installez les packages suivants :
pip install openai requests pillow
- ouvert: SDK compatible pour communiquer avec CometAPI.
- demandes:Pour les opérations HTTP telles que le téléchargement d'images.
- oreiller: Pour la gestion des images lors de l'envoi d'entrées multimodales.
Initialisation du client CometAPI
Utilisez des variables d’environnement pour garder votre clé API hors du code source :
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
Cette instance client peut désormais cibler n'importe quel modèle pris en charge en spécifiant son ID (par exemple, gemini-2.5-flash-lite-preview-06-17) dans vos demandes.
Configuration du budget de réflexion et d'autres paramètres
Lorsque vous envoyez une demande, vous pouvez inclure des paramètres facultatifs :
- température/top_p:Contrôler le caractère aléatoire de la génération.
- nombre de candidats: Nombre de sorties alternatives.
- max_tokens:Capuchon de jeton de sortie.
- budget_pensée:Paramètre personnalisé pour Flash-Lite pour trouver un compromis entre la profondeur, la vitesse et le coût.
À quoi ressemble une requête de base vers Gemini 2.5 Flash-Lite via CometAPI ?
Exemple de texte uniquement
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "You are a concise summarizer."},
{"role": "user", "content": "Summarize the latest trends in AI model pricing."}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices.message.content)
Cet appel renvoie un résumé succinct en moins de 200 ms, idéal pour les chatbots ou les pipelines d'analyse en temps réel.
Exemple d'entrée multimodale
from PIL import Image
import requests
# Load an image from a URL
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
max_tokens=200,
)
print(response.choices.message.content)
Flash-Lite traite jusqu'à 7 Mo d'images et renvoie des descriptions contextuelles, ce qui le rend adapté à la compréhension des documents, à l'analyse de l'interface utilisateur et à la création de rapports automatisés.
Comment pouvez-vous tirer parti de fonctionnalités avancées telles que le streaming et l'appel de fonctions ?
Réponses en streaming pour les applications en temps réel
Pour les interfaces de chatbot ou le sous-titrage en direct, utilisez l'API de streaming :
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
):
print(chunk.choices.delta.content, end="")
Cela fournit des sorties partielles dès qu'elles sont disponibles, réduisant ainsi la latence perçue dans les interfaces utilisateur interactives.
Fonction appelant pour la sortie de données structurées
Définissez des schémas JSON pour appliquer des réponses structurées :
functions = [{
"name": "extract_entities",
"description": "Extract named entities from text.",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required":
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices.message.function_call.arguments)
Cette approche garantit des sorties conformes à JSON, simplifiant ainsi les pipelines de données et les intégrations en aval.
Comment optimiser les performances, les coûts et la fiabilité lors de l'utilisation de Gemini 2.5 Flash-Lite ?
Ajustement du budget de la pensée
Le paramètre de budget de réflexion de Flash-Lite vous permet de définir l'effort cognitif que le modèle doit fournir. Un budget faible (par exemple, 0) privilégie la vitesse et le coût, tandis que des valeurs plus élevées permettent un raisonnement plus approfondi au détriment de la latence et des jetons.
Gestion des limites de jetons et du débit
- Jetons d'entrée:Jusqu'à 1,048,576 XNUMX XNUMX jetons par demande.
- Jetons de sortie:Limite par défaut de 65,536 XNUMX jetons.
- Entrées multimodales: Jusqu'à 500 Mo de ressources image, audio et vidéo.
Implémentez le traitement par lots côté client pour les charges de travail à volume élevé et exploitez la mise à l'échelle automatique de CometAPI pour gérer le trafic en rafale sans intervention manuelle.
Stratégies de rentabilité
- Regroupez les tâches de faible complexité sur Flash-Lite tout en réservant Flash Pro ou standard pour les tâches lourdes.
- Utilisez les limites de taux et les alertes budgétaires dans le tableau de bord CometAPI pour éviter les dépenses incontrôlables.
- Surveillez l'utilisation par ID de modèle pour comparer le coût par demande et ajustez votre logique de routage en conséquence.
Quelles sont les meilleures pratiques et les prochaines étapes après l’intégration initiale ?
Surveillance, journalisation et sécurité
- Journal: Capturez les métadonnées de demande/réponse (horodatages, latences, utilisation des jetons) pour les audits de performances.
- Alertes: Configurez des notifications de seuil pour les taux d'erreur ou les dépassements de coûts dans CometAPI.
- Sécurité: Faites tourner régulièrement les clés API et stockez-les dans des coffres sécurisés ou des variables d'environnement.
Modèles d'utilisation courants
- Chatbots:Utilisez Flash-Lite pour les requêtes rapides des utilisateurs et revenez à Pro pour les suivis complexes.
- Traitement des documents: Analyses par lots de PDF ou d'images pendant la nuit avec un budget réduit.
- Analyse en temps réel: Diffusez des données financières ou opérationnelles pour obtenir des informations instantanées via l'API de streaming.
Explorer plus loin
- Expérimentez avec des invites hybrides : combinez des entrées de texte et d'image pour un contexte plus riche.
- Prototype RAG (Retrieval-Augmented Generation) en intégrant des outils de recherche vectorielle avec Gemini 2.5 Flash-Lite.
- Comparez les offres concurrentes (par exemple, GPT-4.1, Claude Sonnet 4) pour valider les compromis entre coûts et performances.
Mise à l'échelle en production
- Tirez parti du niveau entreprise de CometAPI pour des pools de quotas dédiés et des garanties SLA.
- Mettez en œuvre des stratégies de déploiement bleu-vert pour tester de nouvelles invites ou de nouveaux budgets sans perturber les utilisateurs en direct.
- Examinez régulièrement les mesures d’utilisation du modèle pour identifier les opportunités de nouvelles économies de coûts ou d’améliorations de la qualité.
Pour commencer
CometAPI fournit une interface REST unifiée qui regroupe des centaines de modèles d'IA sous un point de terminaison cohérent, avec gestion intégrée des clés API, des quotas d'utilisation et des tableaux de bord de facturation. Plus besoin de jongler avec plusieurs URL et identifiants de fournisseurs.
Les développeurs peuvent accéder API Gemini 2.5 Flash-Lite (aperçu)(Modèle: gemini-2.5-flash-lite-preview-06-17) À travers API CometLes derniers modèles listés sont ceux en vigueur à la date de publication de l'article. Pour commencer, explorez les fonctionnalités du modèle dans la section cour de récréation et consultez le Guide de l'API Pour des instructions détaillées, veuillez vous connecter à CometAPI et obtenir la clé API avant d'y accéder. API Comet proposer un prix bien inférieur au prix officiel pour vous aider à vous intégrer.
En quelques étapes seulement, vous pouvez intégrer Gemini 2.5 Flash-Lite à vos applications via CometAPI, vous permettant ainsi de bénéficier d'une puissante combinaison de vitesse, d'accessibilité et d'intelligence multimodale. En suivant les instructions ci-dessus (configuration, requêtes de base, fonctionnalités avancées et optimisation), vous serez parfaitement préparé à offrir des expériences d'IA nouvelle génération à vos utilisateurs. L'avenir de l'IA rentable et à haut débit est arrivé : commencez dès aujourd'hui avec Gemini 2.5 Flash-Lite.