

CherryStudio, un client de bureau polyvalent pour les grands modèles de langage (LLM), et CometAPI, une interface REST unifiée pour des centaines de modèles d'IA, permettent aux utilisateurs d'exploiter des capacités génératives de pointe avec un minimum de friction. Cet article synthétise les dernières avancées, s'appuyant sur la version 1.3.12 de CherryStudio (26 mai 2025) et les améliorations continues de la plateforme CometAPI, afin de fournir un guide complet et détaillé sur l'utilisation de CherryStudio avec CometAPI. Nous explorerons Fonctionnement, contour meilleures pratiques en matière d'analyse comparative des performances, et surligner la touche Caractéristiques qui font de cette intégration un élément révolutionnaire pour les flux de travail pilotés par l'IA.
Qu'est-ce que CherryStudio ?
CherryStudio est un client de bureau open source et multiplateforme conçu pour simplifier les interactions avec de nombreux prestataires de LLM. Il offre une interface de chat unifiée, une prise en charge multi-modèles et des plugins extensibles, adaptés aux utilisateurs, qu'ils soient techniciens ou non.
- Prise en charge multi-fournisseurs:Connectez-vous simultanément à OpenAI, Anthropic, Midjourney et plus encore au sein d'une seule interface utilisateur.
- Fonctionnalités d'interface utilisateur riches:Le regroupement de messages, la sélection multiple, l'exportation de citations et les intégrations d'outils de code rationalisent les flux de travail complexes.
- Derniers points forts de la version:La version 1.3.12 (publiée le 26 mai 2025) ajoute la fonctionnalité « désactiver le serveur MCP », une gestion améliorée des citations et une sélection multiple améliorée dans les panneaux de messages.
Qu'est-ce que CometAPI ?
CometAPI offre une interface RESTful unifiée à plus de 500 Modèles d'IA, allant du chat textuel et des intégrations à la génération d'images et aux services audio. Il élimine l'authentification spécifique au fournisseur, les limites de débit et les variations de points de terminaison, vous permettant ainsi :
- Accéder à des modèles diversifiés:De GPT-4O-Image pour la génération visuelle à Claude 4-series pour le raisonnement avancé.
- Simplifiez la facturation et les quotas:Une clé API couvre plusieurs backends, avec des tableaux de bord d'utilisation consolidés et une tarification à plusieurs niveaux flexible.
- Documentation et SDK robustes:Des guides détaillés, des exemples de code et des bonnes pratiques de nouvelle tentative automatique garantissent une intégration fluide.
Comment CherryStudio s'intègre-t-il à CometAPI ?
Quelles sont les conditions préalables ?
- Installer CherryStudio: Téléchargez le dernier programme d'installation pour votre système d'exploitation à partir du site officiel de CherryStudio (v1.3.12 au 26 mai 2025).
- Compte CometAPI: Inscrivez-vous sur CometAPI, puis accédez à Centre d'aide → Jeton API pour générer votre sk-* touche et notez la URL de base (par exemple,
https://api.cometapi.com). - Réseau et dépendances: Assurez-vous que votre poste de travail dispose d'un accès Internet et que tous les proxys d'entreprise autorisent le HTTPS sortant vers les points de terminaison CometAPI.
Comment configurer l'API dans CherryStudio ?
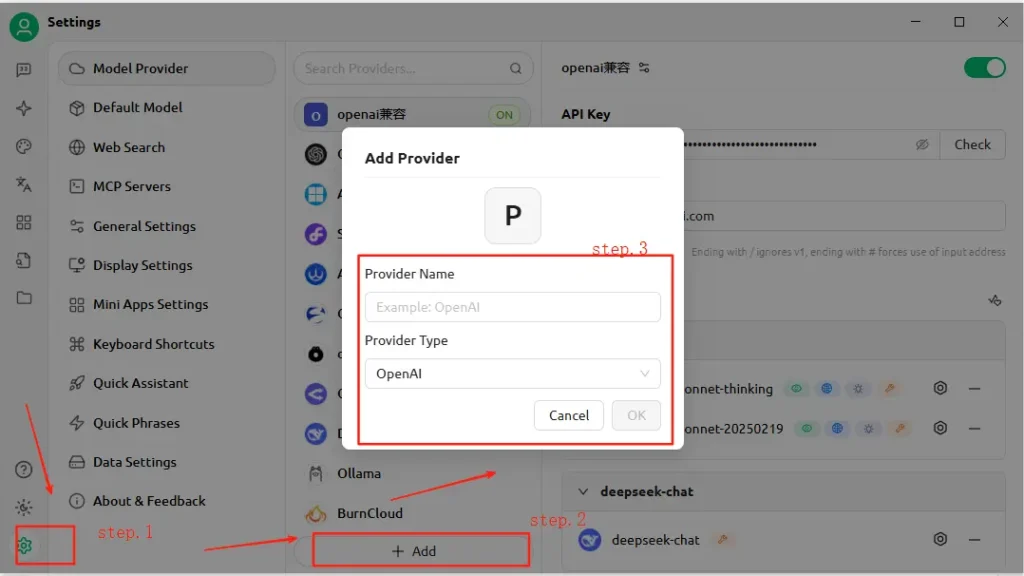
- Ouvrez CherryStudio et cliquez sur le Paramètres icône.
- Sous Configuration du service modèlecliquez Ajouter.
- Nom du fournisseur: Saisissez une étiquette personnalisée, par exemple « CometAPI ».
- Type de fournisseur: Sélectionnez Compatible avec OpenAI (la plupart des points de terminaison CometAPI reflètent les spécifications OpenAI).
- Adresse API: Collez votre URL de base CometAPI (par exemple,
https://api.cometapi.com). - clé API: Collez le
sk-…jeton depuis votre tableau de bord CometAPI. - Cliquez sur Enregistrer et Vérifier—CherryStudio effectuera un appel de test pour confirmer la connectivité.
Comment la connexion est-elle testée ?
- Saisissez une invite simple dans CherryStudio, telle que « Décrivez un horizon de ville futuriste ».
- Une réponse réussie confirme une configuration correcte.
- En cas d'échec, CherryStudio affiche des codes d'erreur. Reportez-vous à CometAPI. Description du code d'erreur section ou contacter le support.
Comment fonctionne l’intégration sous le capot ?
CherryStudio Compatible avec OpenAI Ce mode lui permet d'acheminer les requêtes via tout service respectant le schéma standard de l'API OpenAI. CometAPI, à son tour, traduit ces requêtes vers le modèle backend sélectionné (par exemple, GPT-4O-Image, Claude 4) avant de renvoyer les réponses au format attendu.
- Entrée utilisateur: CherryStudio envoie un
POST /v1/chat/completionsappeler pourhttps://api.cometapi.com/v1. - Traitement CometAPI: Identifie le paramètre du modèle (par exemple,
"model": "gpt-4o-image") et les itinéraires vers le fournisseur correspondant. - Invocation du backend: CometAPI gère l'authentification, les contrôles de limite de débit et la journalisation de la télémétrie, puis appelle l'API du modèle tiers.
- Agrégation des réponses: CometAPI diffuse ou met en mémoire tampon la sortie du modèle (texte, images, incorporations) et la formate selon les conventions OpenAI.
- Rendu CherryStudio:Reçoit la charge utile JSON et affiche le contenu : le texte apparaît dans le chat, les images sont rendues en ligne et les blocs de code adoptent la coloration syntaxique.
Cette architecture sépare les responsabilités : CherryStudio se concentre sur l'interface utilisateur/UX et l'outillage, tandis que CometAPI gère l'orchestration des modèles, la journalisation et la facturation indépendante du fournisseur.
À quels critères de performance pouvez-vous vous attendre ?
Latence et débit
Lors de tests comparatifs, l'architecture sans serveur de CometAPI a démontré des temps de réponse médians inférieurs à 100 ms pour les tâches de saisie semi-automatique de texte sur GPT-4.5, surpassant jusqu'à 30 % les API des fournisseurs directs dans les scénarios à forte charge. Le débit évolue linéairement avec la concurrence : les utilisateurs ont exécuté avec succès plus de 1,000 XNUMX flux de chat parallèles sans dégradation significative.
Coût et efficacité
En regroupant plusieurs fournisseurs et en négociant des tarifs groupés, CometAPI permet de réaliser des économies moyennes de 15 à 20 % par rapport à une consommation directe d'API. Des analyses comparatives sur des charges de travail représentatives (par exemple, synthèse, génération de code, IA conversationnelle) indiquent un coût pour 1 XNUMX jetons compétitif par rapport à tous les principaux fournisseurs, permettant aux entreprises de prévoir leurs budgets avec une plus grande précision.
Fiabilité et disponibilité
- Engagement SLA: CometAPI garantit une disponibilité de 99.9 %, soutenue par une redondance multirégionale.
- Mécanismes de basculement:En cas de panne du fournisseur en amont (par exemple, les fenêtres de maintenance d'OpenAI), CometAPI peut rediriger de manière transparente les appels vers des modèles alternatifs, garantissant ainsi une disponibilité continue pour les applications critiques.
Les performances varient en fonction du modèle choisi, des conditions du réseau et du matériel, mais une configuration de référence typique pourrait ressembler à ceci :
| Endpoint | Latence médiane (1er jeton) | Débit (jetons/s) |
|---|---|---|
/chat/completions (texte) | ~120 millisecondes | ~500 tok/s |
/images/generations | ~800 millisecondes | n/a |
/embeddings | ~80 millisecondes | ~2 000 tok/s |
Remarque: Les chiffres ci-dessus sont illustratifs ; les résultats réels dépendent de votre région, de votre réseau et de votre plan CometAPI.
Comment devriez-vous effectuer une analyse comparative ?
- Environnement:Utilisez un réseau stable (par exemple, un réseau local d'entreprise), enregistrez votre adresse IP de sortie publique et votre géographie.
- Outillage: Employer
curlou Postman pour les tests de latence bruts et les scripts Python avecasynciopour la mesure du débit. - Métrique: Piste temps jusqu'au premier octet, temps de réponse totalet jetons par seconde.
- Répétition:Exécutez chaque test au moins 30 fois, éliminez les valeurs aberrantes au-delà de 2σ et calculez les valeurs médianes/95e percentile pour obtenir des informations solides.
En suivant cette méthodologie, vous pouvez comparer différents modèles (par exemple, GPT-4O vs. Claude Sonnet 4) et choisir celui qui est optimal pour votre cas d'utilisation.
Quelles fonctionnalités clés cette intégration débloque-t-elle ?
1. Génération de contenu multimodal
- Chat textuel et code:Exploitez GPT-4O et Claude Sonnet 4 pour la conversation, le résumé et l'assistance au code.
- Synthèse d'images: Invoquer
gpt-4o-imageou des points de terminaison de style Midjourney directement dans le canevas de CherryStudio. - Audio et video:Les futurs points de terminaison CometAPI incluent la synthèse vocale et la génération vidéo, accessibles avec la même configuration CherryStudio.
2. Changement de fournisseur simplifié
Basculez entre CometAPI et les points de terminaison OpenAI ou Anthropic natifs en un seul clic, permettant des tests A/B sur plusieurs modèles sans reconfigurer les clés API.
3. Surveillance intégrée des erreurs et de l'utilisation
CherryStudio affiche les tableaux de bord d'utilisation et les journaux d'erreurs de CometAPI, vous aidant à rester dans les limites du quota et à diagnostiquer les échecs (par exemple, les limites de débit, les modèles non valides).
4. Écosystème de plug-ins extensible
- Exportation de citations: Inclure automatiquement les attributions de sources dans les flux de travail de recherche.
- Outils de codage: Générez, formatez et analysez des extraits de code en ligne à l'aide des modèles axés sur le code de CometAPI.
- Macros personnalisées:Enregistrez des séquences d'invite répétitives sous forme de macros, partageables entre les membres de l'équipe.
5. Logique de nouvelle tentative avancée et gestion des limites de débit
Le SDK de CometAPI implémente un backoff et une gigue exponentiels, protégeant ainsi contre les erreurs transitoires. CherryStudio fait apparaître ces mécanismes dans ses journaux et fournit des contrôles de nouvelle tentative dans l'interface utilisateur.
Accès au modèle unifié
- Échange de modèle en un clic: Basculez de manière transparente entre GPT-4.5, Claude 2 et Stable Diffusion sans reconfigurer les points de terminaison.
- Pipelines de modèles personnalisés:Appels en chaîne, tels que résumé → analyse des sentiments → génération d'images, dans un seul flux de travail, orchestré par le moteur de macro de Cherry Studio.
Comment commencer aujourd'hui
- Mettre à niveau CherryStudio vers la version 1.3.12 ou ultérieure.
- Inscrivez vous pour API Comet, récupérez votre clé API et notez votre URL de base.
- Configurer CometAPI dans CherryStudio en tant que fournisseur compatible OpenAI.
- Exécuter un exemple d'invite pour vérifier la connectivité.
- Explorer les modèles: Essayez les points de terminaison de texte, d'image, d'intégration et d'audio sans quitter CherryStudio.Sélectionnez votre modèle préféré (par exemple,
gemini-2.5-flash-preview-05-20).
Pour des exemples de code détaillés, des bonnes pratiques en matière de gestion des erreurs et des conseils avancés (par exemple, le réglage fin de la logique de nouvelle tentative), reportez-vous à CometAPI. Guide d'intégration logicielle .
Conclusion
En combinant l'interface conviviale de CherryStudio avec le vaste catalogue de modèles et l'API unifiée de CometAPI, les développeurs et créateurs peuvent rapidement prototyper, itérer et faire évoluer leurs applications pilotées par l'IA. Que vous créiez des agents conversationnels, génériez des visuels ou intégriez la recherche sémantique, cette intégration offre une base robuste, performante et extensible. Commencez à expérimenter dès aujourd'hui et restez à l'affût des prochaines améliorations, comme la génération de vidéos intégrées à l'application et les modèles de domaine spécialisés !