

DeepSeek-V3.1 est le dernier modèle de raisonnement hybride de DeepSeek. Il prend en charge un mode de chat rapide « non-réflexif » et un mode « réflexion/raisonnement » plus réfléchi. Il offre un contexte long (jusqu'à 128 Ko), des sorties structurées et des appels de fonctions. Il est accessible directement via l'API DeepSeek compatible OpenAI, un point de terminaison compatible Anthropic ou CometAPI. Je vous présente ci-dessous le modèle, les points forts des benchmarks et des coûts, ainsi que ses fonctionnalités avancées (appels de fonctions, sorties JSON, mode de raisonnement). Je vous propose ensuite des exemples de code concrets de bout en bout : appels REST DeepSeek directs (curl / Node / Python), utilisation du client Anthropic et appels via CometAPI.
Qu'est-ce que DeepSeek-V3.1 et quelles sont les nouveautés de cette version ?
DeepSeek-V3.1 est la version la plus récente de la famille DeepSeek V3 : une gamme de modèles linguistiques de grande capacité, composée d'experts variés, qui propose un conception d'inférence hybride avec deux « modes » opérationnels — un rapide conversation sans réflexion mode et un pensant / raisonneur Mode permettant d'exposer des traces de type chaîne de pensée pour les tâches de raisonnement plus complexes et l'utilisation d'agents/outils. Cette version met l'accent sur une latence de « réflexion » plus rapide, des fonctionnalités d'outils/agents améliorées et une gestion du contexte plus longue pour les workflows à l'échelle des documents.
Principaux points pratiques à retenir :
- Deux modes de fonctionnement :
deepseek-chatpour le débit et le coût,deepseek-reasoner(un modèle de raisonnement) lorsque vous souhaitez des traces de chaîne de pensée ou une plus grande fidélité de raisonnement. - Gestion améliorée des agents/outils et améliorations du tokenizer/contexte pour les documents longs.
- Longueur du contexte : jusqu'à ~128 XNUMX jetons (permet des documents longs, des bases de code, des journaux).
Percée de référence
DeepSeek-V3.1 a démontré des améliorations significatives face aux défis de codage réels. Lors de l'évaluation SWE-bench Verified, qui mesure la fréquence à laquelle le modèle corrige les problèmes GitHub pour garantir la réussite des tests unitaires, la version 3.1 a atteint un taux de réussite de 66 %, contre 45 % pour les versions V3-0324 et R1. Dans la version multilingue, la version 3.1 a résolu 54.5 % des problèmes, soit près du double du taux de réussite d'environ 30 % des autres versions. Lors de l'évaluation Terminal-Bench, qui teste la capacité du modèle à exécuter des tâches dans un environnement Linux réel, DeepSeek-V3.1 a réussi 31 % des tâches, contre respectivement 13 % et 6 % pour les autres versions. Ces améliorations démontrent que DeepSeek-V3.1 est plus fiable pour l'exécution de code et le fonctionnement dans des environnements d'outils réels.
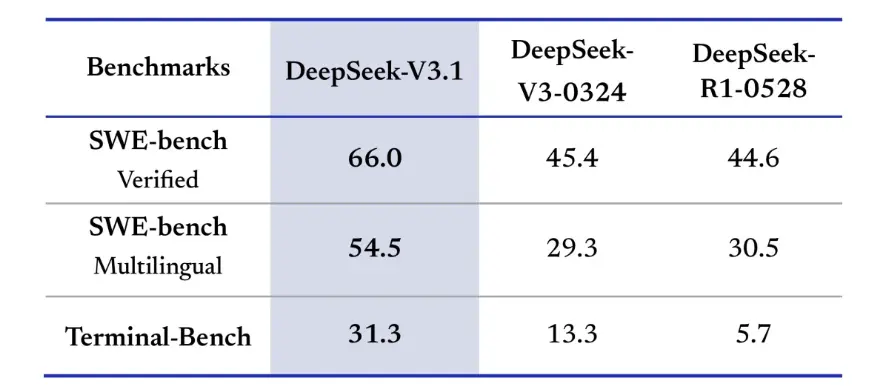
Les tests de recherche d'information privilégient également DeepSeek-V3.1 pour la navigation, la recherche et la réponse aux questions. Lors de l'évaluation BrowseComp, qui nécessite la navigation et l'extraction de réponses à partir d'une page web, la version 3.1 a répondu correctement à 30 % des questions, contre 9 % pour R1. Dans la version chinoise, DeepSeek-V3.1 a atteint une précision de 49 %, contre 36 % pour R1. Lors du Hard Language Exam (HLE), la version 3.1 a légèrement surpassé R1, avec une précision respective de 30 % et 25 %. Pour les tâches de recherche approfondie telles que xbench-DeepSearch, qui nécessitent la synthèse d'informations provenant de différentes sources, la version 3.1 a obtenu un score de 71 %, contre 1 % pour R55. DeepSeek-V3.1 a également affiché une avance modeste mais constante sur des tests tels que le raisonnement structuré, SimpleQA (réponse à des questions factuelles) et Seal0 (réponse à des questions spécifiques à un domaine). Dans l’ensemble, la version V3.1 a nettement surpassé la version R1 en termes de recherche d’informations et de réponses aux questions légères.
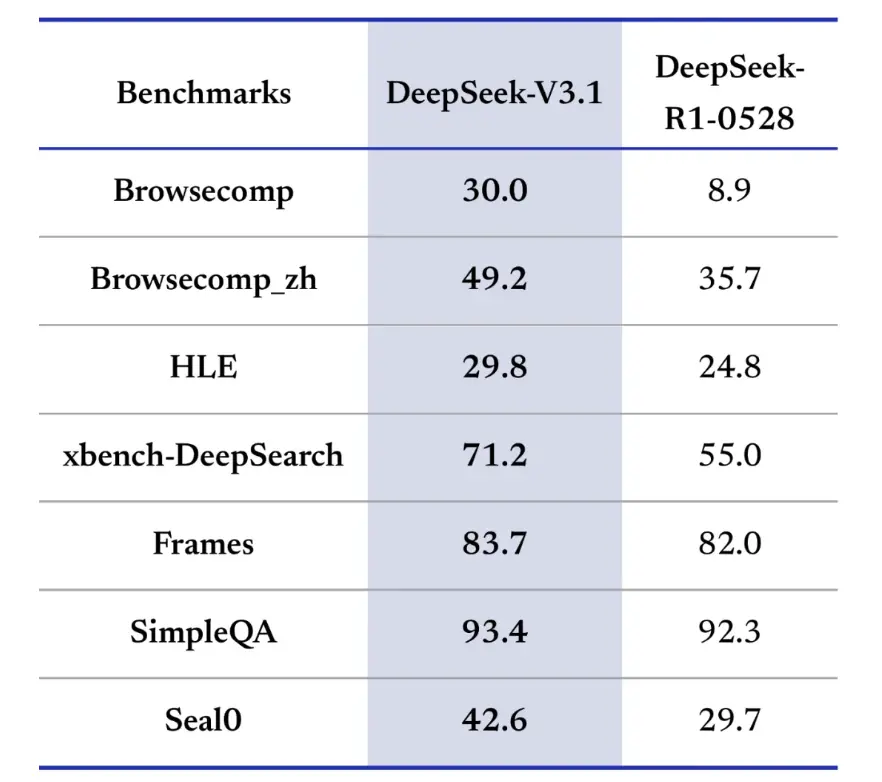
En termes d'efficacité du raisonnement, les résultats d'utilisation des jetons démontrent son efficacité. Lors de l'AIME 2025 (un examen de mathématiques difficile), V3.1-Think a atteint une précision comparable ou légèrement supérieure à R1 (88.4 % contre 87.5 %), mais a utilisé environ 30 % de jetons en moins. Lors de l'examen GPQA Diamond (un examen de deuxième cycle multi-domaines), les deux modèles étaient presque identiques (80.1 % contre 81.0 %), mais V3.1 a utilisé près de la moitié des jetons de R1. Lors du benchmark LiveCodeBench, qui évalue le raisonnement du code, V3.1 s'est avéré non seulement plus précis (74.8 % contre 73.3 %), mais aussi plus concis. Cela démontre que V3.1-Think est capable de fournir un raisonnement détaillé tout en évitant la verbosité.
Globalement, la version 3.1 représente un saut générationnel significatif par rapport à la version 3-0324. Comparée à la version R1, la version 3.1 a obtenu une précision supérieure sur presque tous les tests et s'est montrée plus efficace sur les tâches de raisonnement complexes. Le seul test où la version R1 a égalé la performance était GPQA, mais à un coût presque deux fois supérieur.
Comment obtenir une clé API et configurer un compte de développement ?
Étape 1 : Inscrivez-vous et créez un compte
- Visitez le portail des développeurs de DeepSeek (documentation DeepSeek / console). Créez un compte avec votre adresse e-mail ou votre fournisseur SSO.
- Effectuez toutes les vérifications d’identité ou configurations de facturation requises par le portail.
Étape 2 : Créer une clé API
- Dans le tableau de bord, accédez à Clés de l'API → Créer une cléNommez votre clé (par exemple,
dev-local-01). - Copiez la clé et stockez-la dans un gestionnaire de secrets sécurisé (voir les meilleures pratiques de production ci-dessous).
Astuce : certaines passerelles et routeurs tiers (par exemple, CometAPI) vous permettent d'utiliser une seule clé de passerelle pour accéder aux modèles DeepSeek via eux, ce qui est utile pour la redondance multi-fournisseurs (voir le API DeepSeek V3.1 section).
Comment configurer mon environnement de développement (Linux/macOS/Windows) ?
Il s'agit d'une configuration simple et reproductible pour Python et Node.js qui fonctionne pour DeepSeek (points de terminaison compatibles OpenAI), CometAPI et Anthropic.
Pré-requis :
- Python 3.10+ (recommandé), pip, virtualenv.
- Node.js 18+ et npm/yarn.
- curl (pour des tests rapides).
Environnement Python (étape par étape)
- Créer un répertoire de projet :
mkdir deepseek-demo && cd deepseek-demo
python -m venv .venv
source .venv/bin/activate # macOS / Linux
# .venv\Scripts\activate # Windows PowerShell
- Installer les packages minimaux :
pip install --upgrade pip
pip install requests
# Optional: install an OpenAI-compatible client if you prefer one:
pip install openai
- Enregistrez votre clé API dans les variables d'environnement (ne jamais valider) :
export DEEPSEEK_KEY="sk_live_xxx"
export CometAPI_KEY="or_xxx"
export ANTHROPIC_KEY="anthropic_xxx"
(Utilisation de Windows PowerShell $env:DEEPSEEK_KEY = "…")
Environnement de nœud (étape par étape)
- Initialiser:
mkdir deepseek-node && cd deepseek-node
npm init -y
npm install node-fetch dotenv
- Créer un
.envfichier:
DEEPSEEK_KEY=sk_live_xxx
CometAPI_KEY=or_xxx
ANTHROPIC_KEY=anthropic_xxx
Comment appeler DeepSeek-V3.1 directement — exemples de code étape par étape ?
L'API de DeepSeek est compatible avec OpenAI. Voici les informations suivantes : copier-coller exemples : curl, Python (requêtes et style SDK OpenAI) et Node.
Étape 1 : Exemple de boucle simple
curl https://api.deepseek.com/v1/chat/completions \
-H "Authorization: Bearer $DEEPSEEK_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-chat-v3.1",
"messages": [
{"role":"system","content":"You are a concise engineering assistant."},
{"role":"user","content":"Give a 5-step secure deployment checklist for a Django app."}
],
"max_tokens": 400,
"temperature": 0.0,
"reasoning_enabled": true
}'
Remarques : reasoning_enabled Active/désactive le mode Réflexion (indicateur du fournisseur). Le nom exact de l'indicateur peut varier selon le fournisseur ; consultez la documentation du modèle.
Étape 2 : Python (requêtes) avec télémétrie simple
import os, requests, time, json
API_KEY = os.environ
URL = "https://api.deepseek.com/v1/chat/completions"
payload = {
"model": "deepseek-chat-v3.1",
"messages": [
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Refactor this Flask function to be testable: ..."}
],
"max_tokens": 600,
"temperature": 0.1,
"reasoning_enabled": True
}
start = time.time()
r = requests.post(URL, headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}, json=payload, timeout=60)
elapsed = time.time() - start
print("Status:", r.status_code, "Elapsed:", elapsed)
data = r.json()
print(json.dumps(data, indent=2))
CometAPI : accès entièrement gratuit à DeepSeek V3.1
Pour les développeurs souhaitant un accès immédiat sans inscription, CometAPI offre une alternative intéressante à DeepSeek V3.1 (nom du modèle : deepseek-v3-1-250821 ; deepseek-v3.1). Ce service de passerelle regroupe plusieurs modèles d'IA via une API unifiée, donnant accès à DeepSeek et offrant d'autres avantages, notamment le basculement automatique, l'analyse de l'utilisation et la facturation inter-fournisseurs simplifiée.
Tout d’abord, créez un compte CometAPI sur https://www.cometapi.com/—Le processus ne prend que deux minutes et nécessite simplement une vérification de l'adresse e-mail. Une fois connecté, générez une nouvelle clé dans la section « Clé API ». https://www.cometapi.com/ offre des crédits gratuits pour les nouveaux comptes et une réduction de 20 % sur le prix officiel de l'API.
La mise en œuvre technique nécessite des modifications de code minimales. Il suffit de remplacer votre point de terminaison d'API par une URL DeepSeek directe par la passerelle CometAPI.
Remarque : l’API prend en charge le streaming (
stream: true),max_tokens, température, séquences d'arrêt et fonctionnalités d'appel de fonctions similaires à d'autres API compatibles OpenAI.
Comment puis-je appeler DeepSeek à l'aide des SDK Anthropic ?
DeepSeek fournit un point de terminaison compatible Anthropic afin que vous puissiez réutiliser les SDK Anthropc ou les outils Claude Code en pointant le SDK vers https://api.deepseek.com/anthropic et en définissant le nom du modèle sur deepseek-chat (ou deepseek-reasoner (là où pris en charge).
Invoquer le modèle DeepSeek via l'API anthropique
Installez le SDK Anthropic : pip install anthropic. Configurez votre environnement :
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_API_KEY=YOUR_DEEPSEEK_KEY
Créer un message:
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="deepseek-chat",
max_tokens=1000,
system="You are a helpful assistant.",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Hi, how are you?"
}
]
}
]
)
print(message.content)
Utiliser DeepSeek dans Claude Code
Installation : npm install -g @anthropic-ai/claude-code. Configuration de votre environnement :
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_AUTH_TOKEN=${YOUR_API_KEY}
export ANTHROPIC_MODEL=deepseek-chat
export ANTHROPIC_SMALL_FAST_MODEL=deepseek-chat
Entrez dans le répertoire du projet et exécutez le code Claude :
cd my-project
claude
Utiliser DeepSeek dans Claude Code via CometAPI
CometAPI prend en charge Claude Code. Après l'installation, lors de la configuration de l'environnement, remplacez simplement l'URL de base par https://www.cometapi.com/console/ et la clé par la clé CometAPI pour utiliser le modèle DeepSeek de CometAPI dans Claude Code.
# Navigate to your project folder cd your-project-folder
# Set environment variables (replace sk-... with your actual token)
export ANTHROPIC_AUTH_TOKEN=sk-...
export ANTHROPIC_BASE_URL=https://www.cometapi.com/console/
# Start Claude Code
claude
Remarques :
- DeepSeek mappe les noms de modèles anthropiques non pris en charge à
deepseek-chat. - La couche de compatibilité anthropique prend en charge
system,messages,temperature, streaming, séquences d'arrêt et tableaux de réflexion.
Quelles sont les bonnes pratiques concrètes de production (sécurité, coût, fiabilité) ?
Vous trouverez ci-dessous des modèles de production recommandés qui s'appliquent à DeepSeek ou à toute utilisation LLM à volume élevé.
Secrets et identité
- Stockez les clés API dans un gestionnaire de secrets (ne pas utiliser
.enven production). Faites tourner les clés régulièrement et créez des clés par service avec le minimum de privilèges. - Utilisez des projets/comptes distincts pour le développement/la préparation/la production.
Limites de débit et nouvelles tentatives
- Mettre en œuvre le ralentissement exponentiel sur HTTP 429/5xx avec jitter. Limiter les tentatives de nouvelle tentative (par exemple, 3 tentatives).
- Utilisez des clés d’idempotence pour les demandes qui peuvent être répétées.
Exemple Python — réessayer avec backoff
import time, random, requests
def post_with_retries(url, headers, payload, attempts=3):
for i in range(attempts):
r = requests.post(url, json=payload, headers=headers, timeout=60)
if r.status_code == 200:
return r.json()
if r.status_code in (429, 502, 503, 504):
backoff = (2 ** i) + random.random()
time.sleep(backoff)
continue
r.raise_for_status()
raise RuntimeError("Retries exhausted")
La gestion des coûts
- Limiter
max_tokenset évitez de demander accidentellement des sorties énormes. - Réponses du modèle de cache le cas échéant (en particulier pour les invites répétées). DeepSeek distingue explicitement les succès et les échecs de cache dans sa tarification : la mise en cache permet de réaliser des économies.
- Utilisez le
deepseek-chatpour les petites réponses de routine ; réservedeepseek-reasonerpour les cas qui nécessitent vraiment un CoT (c'est plus cher).
Observabilité et journalisation
- Enregistrez uniquement les métadonnées des requêtes en texte clair (hachages d'invite, nombre de jetons, latences). Évitez d'enregistrer l'intégralité des données utilisateur ou du contenu sensible. Enregistrez les identifiants de requête/réponse pour le support et le rapprochement de facturation.
- Suivez l'utilisation des jetons par demande et exposez la budgétisation/les alertes sur les coûts.
Contrôles de sécurité et d'hallucinations
- Utilisez le sorties d'outils et validateurs déterministes pour tout ce qui est critique pour la sécurité (financière, juridique, médicale).
- Pour les sorties structurées, utilisez
response_format+Schéma JSON et valider les sorties avant de prendre des mesures irréversibles.
Modèles de déploiement
- Exécutez des appels de modèle à partir d’un processus de travail dédié pour contrôler la concurrence et la mise en file d’attente.
- Déchargez les tâches lourdes vers les travailleurs asynchrones (tâches Celery, Fargate, tâches Cloud Run) et répondez aux utilisateurs avec des indicateurs de progression.
- Pour les besoins de latence/débit extrêmes, tenez compte des SLA des fournisseurs et déterminez s'il faut auto-héberger ou utiliser des accélérateurs de fournisseurs.
Note de clôture
DeepSeek-V3.1 est un modèle hybride pragmatique, conçu pour les conversations rapides et les tâches agentiques complexes. Son architecture d'API compatible OpenAI simplifie la migration pour de nombreux projets, tandis que les couches de compatibilité Anthropic et CometAPI le rendent flexible pour les écosystèmes existants. Les benchmarks et les rapports de la communauté montrent des compromis coût/performance prometteurs. Cependant, comme pour tout nouveau modèle, validez-le sur vos charges de travail réelles (invite, appel de fonctions, contrôles de sécurité, latence) avant le déploiement en production.
Sur CometAPI, vous pouvez l'exécuter en toute sécurité et interagir avec lui via une API compatible OpenAI ou conviviale cour de récréation, sans limite de débit.
👉 Déployez DeepSeek-V3.1 sur CometAPI maintenant!
Pourquoi utiliser CometAPI ?
- Multiplexage des fournisseurs: changer de fournisseur sans réécriture de code.
- Facturation/métriques unifiées: si vous acheminez plusieurs modèles via CometAPI, vous obtenez une seule surface d'intégration.
- Métadonnées du modèle: afficher la longueur du contexte et les paramètres actifs par variante de modèle.