

Kling O1, lancé lors de la semaine de présentation d'« Omni » de Kling AI, se positionne comme un modèle de base vidéo multimodal unique et unifié. Il accepte le texte, les images et les vidéos dans une même requête et permet de générer et de monter des vidéos grâce à des flux de travail itératifs de niveau réalisateur. L'équipe de Kling présente O1 comme le « premier modèle vidéo multimodal unifié à grande échelle au monde ». Les tests internes de Kling font état de performances nettement supérieures à celles de Veo 3.1 de Google et de Runway Aleph.
Qu'est-ce que Kling O1 ?
Kling O1 (souvent commercialisé sous le nom de Vidéo O1 or Omni unKling AI a récemment lancé un nouveau modèle de base pour la vidéo qui unifie la génération et le montage de textes, d'images et de vidéos au sein d'un cadre unique piloté par des instructions. Au lieu de traiter la conversion texte-vidéo, la conversion image-vidéo et le montage vidéo comme des processus distincts, Kling O1 accepte des entrées mixtes (texte + plusieurs images + vidéo de référence optionnelle) dans une seule instruction, les analyse et produit de courts clips cohérents ou monte des séquences existantes avec une grande précision. L'entreprise a présenté ce lancement comme faisant partie d'un « lancement global » et décrit O1 comme un « moteur vidéo multimodal » construit autour d'un paradigme de langage visuel multimodal (MVL) et d'un chemin de raisonnement de type « chaîne de pensée » (CoT) pour interpréter des instructions créatives complexes et multipartites.
Le système de communication de Kling met l'accent sur trois flux de travail pratiques : (1) texte → génération vidéo, (2) image/élément → vidéo (composition et permutation sujet/accessoire à l'aide de références explicites), et (3) montage vidéo/continuation de plans (restyle, ajout/suppression d'objets, contrôle des images de début et de fin). Le modèle prend en charge les invites multi-éléments (y compris une syntaxe « @ » pour cibler des images de référence spécifiques) et propose des commandes de type réalisateur, telles que l'ancrage des images de début et de fin et la continuation vidéo, pour créer des séquences multi-plans.
5 points clés du Kling O1
1) Véritable entrée multimodale unifiée (MVL)
La fonctionnalité phare de Kling O1 est le traitement simultané de textes, d'images fixes (références multiples) et de vidéos comme des entrées de premier ordre. Les utilisateurs peuvent fournir plusieurs images de référence (ou un court extrait vidéo). et une instruction en langage naturel ; le modèle analysera toutes les entrées pour produire ou modifier une sortie cohérente. Cela réduit les frictions au sein de la chaîne d'outils et permet des flux de travail tels que « utiliser le sujet de » @image1, placez-les dans l'environnement à partir de @image2, faire correspondre le mouvement à ref_video.mp4et appliquer l'étalonnage des couleurs cinématographiques X. Ce cadre de « langage visuel multimodal » (MVL) est au cœur de l'argumentaire de Kling.
Pourquoi c'est important: Les processus créatifs réels nécessitent souvent de combiner des références : un personnage issu d’une ressource, un mouvement de caméra provenant d’une autre et une instruction narrative textuelle. L’unification de ces éléments permet une génération en une seule passe et réduit le nombre d’étapes de composition manuelles.
2) Édition + génération dans un seul modèle (mode multi-éléments)
La plupart des systèmes précédents séparaient la génération (texte → vidéo) du montage image par image. O1 les combine intentionnellement : le même modèle qui crée un clip à partir de zéro peut également modifier des séquences existantes (échange d’objets, modification du style vestimentaire, suppression d’accessoires ou extension d’un plan), le tout par le biais d’instructions en langage naturel. Cette convergence simplifie considérablement le flux de travail des équipes de production.
Le modèle O1 assure une intégration poussée de multiples tâches vidéo en son cœur :
- Génération de texte en vidéo
- génération de références image/sujet
- Montage vidéo et inpainting
- Refonte vidéo
- Génération de plan suivant/précédent
- Génération vidéo contrainte par images clés
L'intérêt majeur de cette conception réside dans le fait que des processus complexes qui nécessitaient auparavant plusieurs modèles ou outils indépendants peuvent désormais être réalisés au sein d'un seul moteur. Ceci réduit considérablement les coûts de création et de calcul et jette les bases du développement d'un modèle unifié de compréhension et de génération vidéo.
3) La cohérence de la génération vidéo
Cohérence de l'identité : Le modèle O1 améliore les capacités de modélisation de la cohérence intermodale, en maintenant la stabilité de la structure, du matériau, de l'éclairage et du style du sujet de référence pendant le processus de génération :
- Il prend en charge les images de référence multivues pour la modélisation des sujets ;
- il assure la cohérence du sujet entre les plans (les caractéristiques du personnage, de l'objet et de la scène restent continues d'un plan à l'autre) ;
- Il prend en charge les références hybrides multi-sujets, permettant la génération de portraits de groupe et la construction de scènes interactives.
Ce mécanisme améliore considérablement la cohérence et la « cohérence d'identité » de la génération vidéo, la rendant adaptée aux scénarios présentant des exigences de cohérence extrêmement élevées, comme la publicité et la génération de plans de qualité cinématographique.
Mémoire améliorée : Le modèle O1 possède également une « mémoire », ce qui empêche son style de sortie de devenir instable en raison de contextes longs ou d'instructions changeantes. Il peut même :
- mémoriser plusieurs caractères simultanément ;
- permettre à différents personnages d'interagir dans la vidéo ;
- Veillez à conserver une cohérence dans votre style, vos vêtements et votre posture.
4) Composition précise avec la syntaxe « @ » et le contrôle des images de début/fin
Kling a introduit un système de notation abrégée pour la composition (signalé comme un système de mention « @ ») permettant de faire référence à des images spécifiques dans l'invite (par exemple, @image1, @image2) pour attribuer des rôles aux ressources de manière fiable. Combiné à la spécification explicite des images de début et de fin, cela permet au réalisateur de contrôler la transition, le déplacement ou la transformation des éléments dans le clip généré — un ensemble de fonctionnalités axé sur la production qui distingue O1 de nombreux générateurs destinés au grand public.
5) Sorties haute fidélité et relativement longues, et empilement multitâche
Kling O1 est capable de produire des vidéos 1080p de qualité cinématographique (30 images/seconde) et, s'appuyant sur les versions précédentes de Kling, la société met en avant la génération de clips plus longs (jusqu'à 2 minutes selon les dernières présentations du produit). Il permet également de combiner plusieurs tâches créatives en une seule requête (génération, ajout d'un sujet, modification de l'éclairage et édition de la composition). Ces caractéristiques le rendent compétitif face aux moteurs texte-vidéo haut de gamme.
Pourquoi c'est important: Des clips plus longs et de haute fidélité, ainsi que la possibilité de combiner les montages, réduisent le besoin d'assembler de nombreux clips courts et simplifient la production de bout en bout.
Comment Kling O1 est-il conçu et quels sont les mécanismes sous-jacents ?
O1 autour d'un Langage visuel multimodal (MVL) Le modèle principal apprend des représentations conjointes du langage, des images et des signaux de mouvement (images vidéo et caractéristiques de flux optique), puis applique des décodeurs basés sur la diffusion ou des transformateurs pour synthétiser des images temporellement cohérentes. Ce modèle est décrit comme effectuant conditionnement sur de multiples références (texte ; images de type une à plusieurs ; courts clips vidéo) pour produire une représentation vidéo latente qui est ensuite décodée en images par image tout en préservant la cohérence temporelle via une attention inter-images ou des modules temporels spécialisés.
1. Transformateur multimodal + Architecture à contexte long
Le modèle O1 utilise l'architecture Transformer multimodale développée par Keling, intégrant des signaux de texte, d'image et de vidéo, et prenant en charge une mémoire de contexte temporel longue (Multimodal Long Context).
Cela permet au modèle de comprendre la continuité temporelle et la cohérence spatiale lors de la génération vidéo.
2. MVL : Langage visuel multimodal
MVL constitue l'innovation fondamentale de cette architecture.
Elle aligne en profondeur les signaux linguistiques et visuels au sein du Transformer grâce à une couche intermédiaire sémantique unifiée, ce qui permet :
- Permettre à une seule zone de saisie de combiner des instructions multimodales ;
- Améliorer la compréhension précise des descriptions en langage naturel par le modèle ;
- Prise en charge de la génération de vidéos interactives hautement flexibles.
L'introduction du MVL marque un tournant dans la génération vidéo, passant d'une approche « axée sur le texte » à une approche « co-axée sémantiquement et visuellement ».
3. Mécanisme d'inférence par chaîne de pensée
Le modèle O1 introduit un chemin d'inférence « Chaîne de pensée » lors de l'étape de génération vidéo.
Ce mécanisme permet au modèle d'effectuer la logique événementielle et la déduction temporelle avant la génération, maintenant ainsi un lien naturel entre les actions et les événements au sein de la vidéo.
Pipelines d'inférence et d'édition
- Génération: flux : (texte + références d'images facultatives + références vidéo facultatives + paramètres de génération) → le modèle produit des images vidéo latentes → décodage en images → post-traitement couleur/temporel facultatif.
- Édition basée sur des instructions : Flux : (vidéo originale + instructions textuelles + images de référence facultatives) → Le modèle applique en interne la modification demandée à un ensemble de transformations dans l’espace des pixels, puis synthétise les images modifiées tout en préservant le contenu inchangé. Comme tout est intégré dans un seul modèle, les mêmes modules de conditionnement et de gestion temporelle sont utilisés pour la création et la modification.
Kling Viedo o1 contre Veo 3.1 contre Runway Aleph
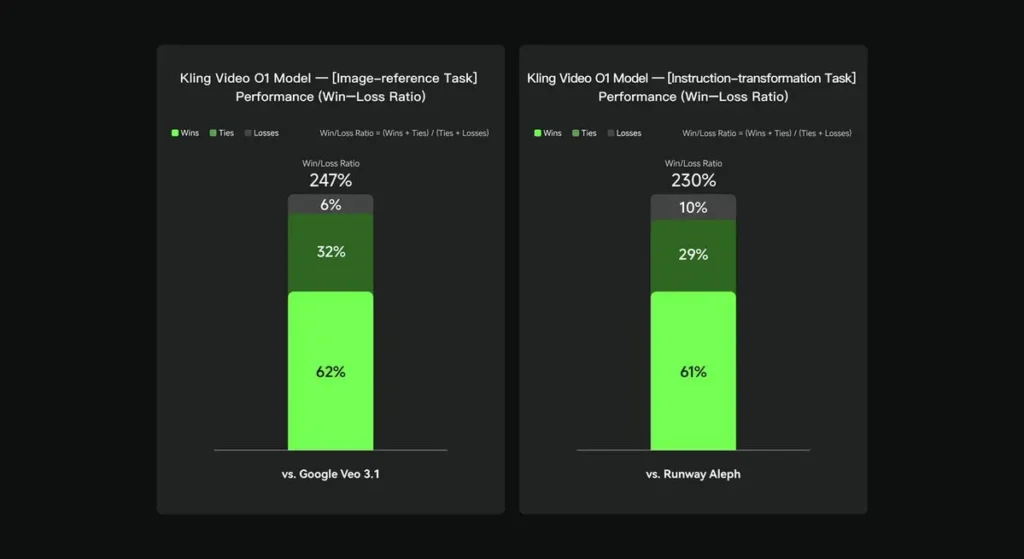
Lors d'évaluations internes, Keling Video O1 a surpassé de manière significative ses concurrents internationaux existants sur plusieurs points clés. Résultats de performance (basés sur l'ensemble d'évaluation interne de Keling AI) :
- Tâche « Image Reference » : O1 surpasse globalement Google Veo 3.1, avec un taux de victoire de 247 % ;
- Tâche « Transformation des instructions » : O1 surpasse Runway Aleph, avec un taux de victoire de 230 %.
Aperçu de la concurrence (comparaison au niveau des fonctionnalités)
| Capacité / Modèle | Kling O1 | Google Veo 3.1 | Piste (Aleph / Gen-4.5) |
|---|---|---|---|
| Invite multimodale unifiée (texte + images + vidéo) | Oui (argument de vente principal). flux multimodaux à requête unique. | Partiel — texte→vidéo + références existent ; moins d'importance accordée à un MVL unique et unifié. | Runway se concentre sur la génération et l'édition, mais souvent comme des modes distincts ; la dernière version Gen-4.5 réduit cet écart. |
| Modifications de pixels conversationnelles/textuelles | Oui — « Monter comme une conversation » (sans masques). | Le montage partiel existe, mais les flux de travail par masque/images clés restent courants. | Runway dispose d'outils d'édition performants ; Runway revendique des transformations d'instructions performantes (variables selon la version). |
| Contrôle du cadre de début/fin et référence de la caméra | Oui — Description explicite des images de début et de fin ainsi que des mouvements de caméra de référence. | Limité / en évolution | Piste d'atterrissage : améliorations des commandes ; expérience utilisateur légèrement différente. |
| Génération de clips longs (haute fidélité) | jusqu'à environ 2 minutes (1080p, 30 images/seconde) dans les supports produits et les publications de la communauté ; | Veo 3.1 : forte cohérence, mais les versions précédentes avaient des valeurs par défaut plus courtes ; varie selon le modèle/paramètre. | Runway Gen-4.5 : vise une qualité élevée ; la longueur/fidélité varie. |
Conclusion:
La principale raison de la notoriété publique de Kling O1 est unification des flux de travailL'objectif est de confier à un modèle unique la capacité de comprendre le texte, les images et la vidéo, et d'effectuer à la fois la génération et l'édition avancée basée sur des instructions, au sein d'un même système sémantique. Pour les créateurs et les équipes qui alternent fréquemment entre les étapes de création, d'édition et d'extension, cette consolidation simplifie considérablement le rythme d'itération et la complexité des outils. Elle offre également une meilleure cohérence temporelle, un contrôle précis des images de début et de fin, ainsi que des intégrations pragmatiques avec les plateformes, la rendant ainsi accessible aux créateurs.
L'API Kling Video o1 sera bientôt disponible sur CometAPI.
Les développeurs peuvent accéder Kling 2.5 Turb et API Veo 3.1 à travers API CometLes derniers modèles listés sont ceux en vigueur à la date de publication de l'article. Pour commencer, explorez les fonctionnalités du modèle dans la section cour de récréation et consultez le Guide de l'API Pour des instructions détaillées, veuillez vous connecter à CometAPI et obtenir la clé API avant d'y accéder. API Comet proposer un prix bien inférieur au prix officiel pour vous aider à vous intégrer.
Prêt à partir ?→ Inscrivez-vous à CometAPI dès aujourd'hui !
Si vous souhaitez connaître plus de conseils, de guides et d'actualités sur l'IA, suivez-nous sur VK, X et Discord!