

L'API Llama 4 est une interface puissante qui permet aux développeurs d'intégrer MetaLes derniers modèles de langage multimodaux de grande taille, permettant des capacités avancées de traitement de texte, d'image et de vidéo dans diverses applications.

Présentation de la série Llama 4
La série Llama 4 de Meta propose des modèles d'IA de pointe conçus pour traiter et traduire divers formats de données, notamment du texte, de la vidéo, des images et de l'audio, améliorant ainsi la polyvalence des applications. La série comprend :
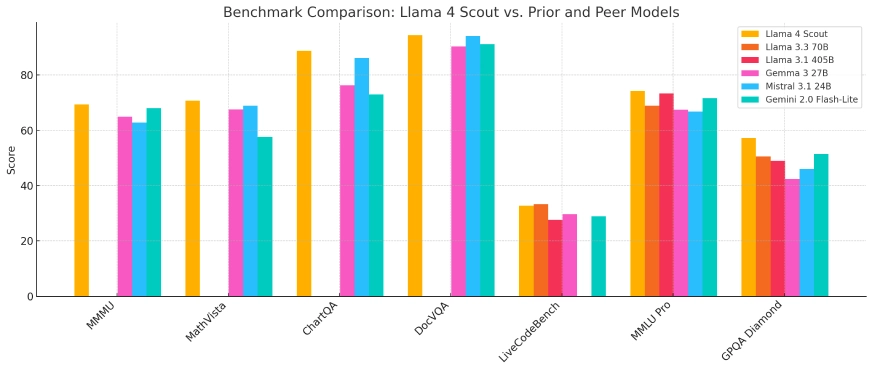
- Llama 4 Scout:Un modèle compact optimisé pour un déploiement sur un seul GPU Nvidia H100, doté d'une fenêtre contextuelle de 10 millions de jetons. Il surpasse ses concurrents tels que Gemma 3 et Mistral 3.1 de Google dans divers benchmarks.
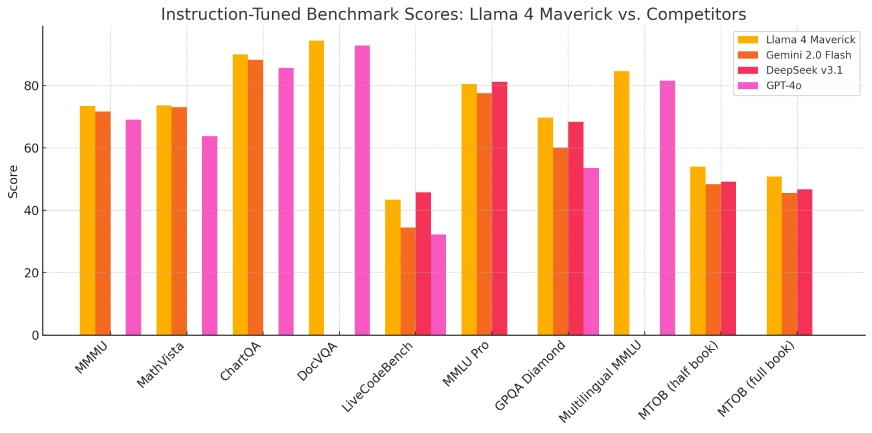
- Llama 4 Maverick:Un modèle plus grand comparable en termes de performances à GPT-4o et DeepSeek-V3 d'OpenAI dans les tâches de codage et de raisonnement, tout en utilisant moins de paramètres actifs.
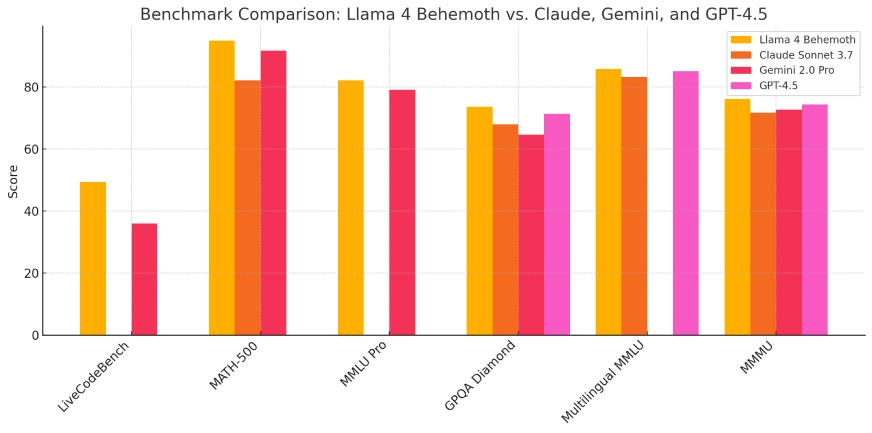
- Llama 4 Behemoth:Actuellement en développement, ce modèle compte 288 milliards de paramètres actifs et un total de 2 4.5 milliards, visant à surpasser des modèles comme GPT-3.7 et Claude Sonnet XNUMX sur les benchmarks STEM.
Ces modèles sont intégrés à l'assistant IA de Meta sur des plateformes telles que WhatsApp, Messenger, Instagram et le Web, améliorant les interactions des utilisateurs avec des capacités d'IA avancées.
| Modèle | Paramètres totaux | Paramètres actifs | Experts | Longueur du contexte | Fonctionne sur | Accès publique | Idéal pour |
|---|---|---|---|---|---|---|---|
| Scout | 109B | 17B | 16 | 10 millions de jetons | Une seule carte Nvidia H100 | ✅ Oui | Tâches d'IA légères, applications à contexte long |
| Maverick | 400B | 17B | 128 | Non spécifié | GPU simple ou multi-GPU | ✅ Oui | Recherche, applications d'entreprise, codage |
| monstre | ~ 2T | 288B | 16 | Non spécifié | Méta-infrastructure interne | ❌ Non | Formation et analyse comparative des modèles internes |
Architecture technique et innovations
La série Llama 4 utilise une architecture « mélange d'experts » (MoE), une approche innovante qui optimise l'utilisation des ressources en activant uniquement les sous-ensembles pertinents des paramètres du modèle lors de tâches spécifiques. Cette conception améliore l'efficacité et les performances de calcul, permettant aux modèles de gérer plus efficacement les tâches complexes.
L'entraînement de ces modèles a nécessité d'importantes ressources de calcul. Meta a utilisé un cluster de GPU comprenant plus de 100,000 100 puces Nvidia HXNUMX, constituant l'une des plus grandes infrastructures d'entraînement en IA à ce jour. Cette puissance de calcul considérable a facilité le développement de modèles aux capacités et aux indicateurs de performance améliorés.
Évolution par rapport aux modèles précédents
S'appuyant sur les bases posées par les versions précédentes, la série Llama 4 représente une évolution significative dans le développement des modèles d'IA de Meta. L'intégration de capacités de traitement multimodal et l'adoption de l'architecture MoE répondent aux limitations observées dans les modèles précédents, notamment en matière de raisonnement et de tâches mathématiques. Ces avancées positionnent Llama 4 comme un concurrent redoutable dans le paysage de l'IA.
Indicateurs de performance et indicateurs techniques de référence
Lors des évaluations comparatives, Llama 4 Scout a démontré des performances supérieures à celles de modèles comme Gemma 3 et Mistral 3.1 de Google, notamment pour les tâches nécessitant un traitement contextuel approfondi. Llama 4 Maverick a quant à lui affiché des capacités comparables à celles de modèles leaders comme GPT-4o d'OpenAI, notamment pour les tâches de codage et de raisonnement, tout en conservant une utilisation plus efficace des paramètres. Ces résultats soulignent l'efficacité de l'architecture MoE et du programme d'entraînement intensif mis en œuvre.
Llama 4 Scout
Llama 4 Maverick
Lama 4 Behemoth :
Scénarios d'application
La polyvalence de la série Llama 4 permet son application dans différents domaines :
- Intégration des réseaux sociaux (mosaique): Améliorer les interactions des utilisateurs sur des plateformes telles que WhatsApp, Messenger et Instagram grâce à des fonctionnalités avancées basées sur l'IA, notamment des recommandations de contenu améliorées et des agents conversationnels.
- Création de contenu:Aider les créateurs à générer du contenu multimodal de haute qualité en traitant et en synthétisant du texte, des images et des vidéos, simplifiant ainsi le processus créatif.
- Outils pédagogiques: Faciliter le développement de systèmes de tutorat intelligents capables d’interpréter et de répondre à divers formats de données, offrant une expérience d’apprentissage plus immersive.
- Business Analytics:Permettre aux entreprises d’analyser et d’interpréter des ensembles de données complexes, y compris des informations textuelles et visuelles, pour en tirer des informations exploitables et éclairer les processus de prise de décision.
L'intégration des modèles Llama 4 dans les plateformes de Meta illustre leur utilité pratique et leur potentiel à améliorer l'expérience utilisateur dans diverses applications.
Considérations éthiques et stratégie open source
Bien que Meta présente la série Llama 4 comme open source, les conditions de licence incluent des restrictions pour les entités commerciales comptant plus de 700 millions d'utilisateurs. Cette approche a suscité des critiques de la part de l'Open Source Initiative, soulignant le débat actuel sur l'équilibre entre libre accès et intérêts commerciaux dans le développement de l'IA.
L'investissement substantiel de Meta, qui pourrait atteindre 65 milliards de dollars dans l'infrastructure de l'IA, souligne l'engagement de l'entreprise à faire progresser les capacités de l'IA et à maintenir un avantage concurrentiel dans le paysage de l'IA en évolution rapide.
Conclusion
Le lancement de la série Llama 4 de Meta marque une avancée majeure en intelligence artificielle, avec des améliorations significatives en termes de traitement multimodal, d'efficacité et de performances. Grâce à des conceptions architecturales innovantes et à des investissements informatiques conséquents, ces modèles établissent de nouvelles références en matière de capacités d'IA. Alors que Meta poursuit l'intégration de ces modèles sur ses plateformes et explore de nouveaux développements, la série Llama 4 est appelée à jouer un rôle crucial dans l'évolution future des applications et services d'IA.
Comment appeler l'API Llama 4 depuis CometAPI
1.Se connecter à cometapi.comSi vous n'êtes pas encore notre utilisateur, veuillez d'abord vous inscrire
2.Obtenir la clé API d'identification d'accès de l'interface. Cliquez sur « Ajouter un jeton » au niveau du jeton API dans l'espace personnel, récupérez la clé du jeton : sk-xxxxx et soumettez.
-
Obtenez l'URL de ce site : https://api.cometapi.com/
-
Sélectionnez le Llama 4 (Nom du modèle : lama-4-maverick; lama-4-scout) Point de terminaison pour envoyer la requête API et définir le corps de la requête. La méthode et le corps de la requête sont obtenus à partir de notre documentation API de site WebNotre site Web propose également le test Apifox pour votre commodité.
- Pour les informations sur le modèle lancé dans l'API Comet, veuillez consulter https://api.cometapi.com/new-model.
- Pour obtenir des informations sur le prix des modèles dans l'API Comet, veuillez consulter https://api.cometapi.com/pricing
| Catégorie | lama-4-maverick | lama-4-scout |
| Tarification des API | Jetons d'entrée : 0.48 $/M jetons | Jetons d'entrée : 0.216 $/M jetons |
| Jetons de sortie : 1.44 $/M jetons | Jetons de sortie : 1.152 $/M jetons |
- Traitez la réponse de l'API pour obtenir la réponse générée. Après l'envoi de la requête API, vous recevrez un objet JSON contenant la complétion générée.