

Le 17 juin, MiniMax, la licorne de l'IA de Shanghai, a officiellement ouvert le code source MiniMax‑M1, le premier modèle d'inférence d'attention hybride à grande échelle et à pondération ouverte au monde. En combinant une architecture Mixture-of-Experts (MoE) avec le nouveau mécanisme Lightning Attention, MiniMax-M1 offre des gains majeurs en termes de vitesse d'inférence, de gestion de contexte ultra-long et de performance des tâches complexes.
Contexte et évolution
S'appuyant sur les fondations de MiniMax-Texte-01, qui a porté une attention particulière à un framework Mixture-of-Experts (MoE) pour atteindre des contextes d'un million de jetons pendant l'entraînement et jusqu'à 1 millions de jetons lors de l'inférence, MiniMax-M4 représente la nouvelle génération de la série MiniMax-1. Le modèle précédent, MiniMax-Text-01, contenait 01 milliards de paramètres au total, dont 456 milliards activés par jeton, affichant des performances comparables à celles des LLM de premier plan tout en étendant considérablement les capacités contextuelles.
Principales caractéristiques du MiniMax-M1
- MoE hybride + Attention foudre:MiniMax‑M1 fusionne une conception Mixture‑of‑Experts clairsemée (456 milliards de paramètres au total, mais seulement 45.9 milliards activés par jeton) avec Lightning Attention, une attention de complexité linéaire optimisée pour les séquences très longues.
- Contexte ultra-long: Prend en charge jusqu'à 1 millions jetons d'entrée (environ huit fois la limite de 128 Ko de DeepSeek-R1) permettant une compréhension approfondie de documents volumineux.
- Efficacité supérieure:Lors de la génération de 100 1 jetons, Lightning Attention de MiniMax‑M25 ne nécessite qu'environ 30 à 1 % du calcul utilisé par DeepSeek‑RXNUMX.
Variantes de modèle
- MiniMax‑M1‑40K: 1 M de contexte de jeton, 40 K de budget d'inférence de jeton
- MiniMax‑M1‑80K: 1 M de contexte de jeton, 80 K de budget d'inférence de jeton
Dans les scénarios d'utilisation des outils TAU-bench, la variante 40K a surpassé tous les modèles à poids ouvert, y compris Gemini 2.5 Pro, démontrant ainsi ses capacités d'agent.
Coût de la formation et mise en place
MiniMax-M1 a été entraîné de bout en bout grâce à l'apprentissage par renforcement (RL) à grande échelle, sur un ensemble varié de tâches, allant du raisonnement mathématique avancé aux environnements d'ingénierie logicielle en bac à sable. Un nouvel algorithme, CISPO (Échantillonnage d'importance découpé pour l'optimisation des politiques) améliore encore l'efficacité de la formation en tronquant les pondérations d'échantillonnage d'importance plutôt que les mises à jour au niveau des jetons. Cette approche, combinée à la précision extrême du modèle, a permis de réaliser une formation RL complète sur 512 GPU H800 en seulement trois semaines, pour un coût de location total de 534,700 XNUMX $.
Disponibilité et prix
MiniMax-M1 est commercialisé sous le nom Apache 2.0 licence open source et est immédiatement accessible via :
- GitHub référentiel, y compris les pondérations des modèles, les scripts de formation et les repères d'évaluation.
- SiliconCloud hébergement, proposant deux variantes : 40 K-token (« M1-40K ») et 80 K-token (« M1-80K »), avec des plans pour activer l'entonnoir complet de 1 M de jetons.
- Les prix sont actuellement fixés à 4 ¥ par million jetons pour l'entrée et 16 ¥ par million jetons de sortie, avec des remises sur volume disponibles pour les clients d'entreprise.
Les développeurs et les organisations peuvent intégrer MiniMax-M1 via des API standard, affiner les données spécifiques au domaine ou déployer sur site pour les charges de travail sensibles.
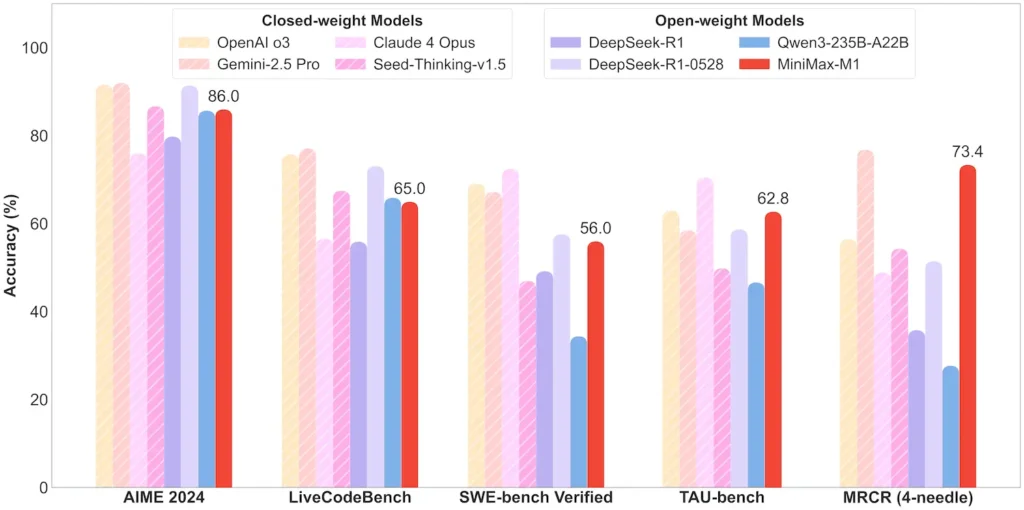
Performance au niveau des tâches
| Catégorie de tâche | Mettre | Performance relative |
|---|---|---|
| Mathématiques et logique | AIME 2024 : 86.0 % | > Qwen 3, DeepSeek‑R1 ; code source quasi fermé |
| Compréhension du contexte long | Souverain (4 K–1 M jetons) : Stable de niveau supérieur | Surpasse GPT‑4 au-delà de 128 K de longueur de jeton |
| Génie logiciel | SWE-bench (bugs GitHub réels) : 56 % | Meilleur parmi les modèles ouverts ; 2e parmi les modèles fermés |
| Utilisation des agents et des outils | TAU-bench (simulation d'API) | 62-63.5 % contre Gémeaux 2.5, Claude 4 |
| Dialogue et assistant | MultiChallenge : 44.7 % | Correspondances Claude 4, DeepSeek‑R1 |
| Assurance qualité des faits | SimpleQA : 18.5 % | Domaine d'amélioration future |
Remarque : pourcentages et repères issus de la divulgation officielle de MiniMax et de rapports de presse indépendants
Innovations techniques
- Pile d'attention hybride: Attention éclair couches (coût linéaire) entrelacées avec Softmax Attention périodique (quadratique mais plus expressif) pour équilibrer efficacité et puissance de modélisation.
- Routage MoE clairsemé: 32 modules experts ; chaque jeton n'active qu'environ 10 % du total des paramètres, réduisant ainsi le coût d'inférence tout en préservant la capacité.
- Apprentissage par renforcement CISPO:Un nouvel algorithme « Clipped IS-weight Policy Optimization » qui conserve des jetons rares mais cruciaux dans le signal d'apprentissage, accélérant ainsi la stabilité et la vitesse du RL.
La version à poids ouvert du MiniMax-M1 libère l'inférence à contexte ultra-long et à haute efficacité pour tous, comblant ainsi le fossé entre la recherche et l'IA déployable à grande échelle.
Pour commencer
CometAPI fournit une interface REST unifiée qui regroupe des centaines de modèles d'IA, dont la famille ChatGPT, sous un point de terminaison cohérent, avec gestion intégrée des clés API, des quotas d'utilisation et des tableaux de bord de facturation. Plus besoin de jongler avec plusieurs URL et identifiants de fournisseurs.
Pour commencer, explorez les capacités des modèles dans le cour de récréation et consultez le Guide de l'API Pour des instructions détaillées, veuillez vous connecter à CometAPI et obtenir la clé API avant d'y accéder.
La dernière intégration de l'API MiniMax‑M1 apparaîtra bientôt sur CometAPI, alors restez à l'écoute ! Pendant que nous finalisons le téléchargement du modèle MiniMax‑M1, explorez nos autres modèles sur le Page des modèles ou essayez-les dans le Aire de jeux IA. Le dernier modèle de MiniMax dans CometAPI est API Minimax ABAB7-Preview et API MiniMax Vidéo-01 ,se référer à :
