Gemini 2.5 Flash est conçu pour fournir des réponses rapides sans compromettre la qualité des résultats. Il prend en charge des entrées multimodales, notamment le texte, les images, l’audio et la vidéo, ce qui le rend adapté à des applications variées. Le modèle est accessible via des plateformes comme Google AI Studio et Vertex AI, offrant aux développeurs les outils nécessaires pour une intégration fluide dans divers systèmes.
Informations de base (Fonctionnalités)
Gemini 2.5 Flash introduit plusieurs fonctionnalités phares qui le distinguent au sein de la famille Gemini 2.5 :
- Raisonnement hybride : Les développeurs peuvent définir un paramètre thinking_budget pour contrôler finement le nombre de tokens que le modèle consacre au raisonnement interne avant la sortie.
- Frontière de Pareto : Positionné au point optimal coût-performances, Flash offre le meilleur ratio prix-intelligence parmi les modèles 2.5.
- Prise en charge multimodale : Traite nativement le texte, les images, la vidéo et l’audio, permettant des capacités conversationnelles et analytiques plus riches.
- Contexte de 1 million de tokens : Une longueur de contexte inégalée permet une analyse approfondie et la compréhension de longs documents en une seule requête.
Gestion des versions du modèle
Gemini 2.5 Flash a évolué à travers les versions clés suivantes :
- gemini-2.5-flash-lite-preview-09-2025: Amélioration de l’utilisabilité des outils : performances accrues sur des tâches complexes et multi-étapes, avec une hausse de 5% des scores SWE-Bench Verified (de 48.9% à 54%). Efficacité améliorée : en activant le raisonnement, une sortie de meilleure qualité est obtenue avec moins de tokens, réduisant la latence et les coûts.
- Preview 04-17 : Version d’accès anticipé avec capacité de « thinking », disponible via gemini-2.5-flash-preview-04-17.
- Disponibilité générale (GA) stable : Au 17 juin 2025, l’endpoint stable gemini-2.5-flash remplace la préversion, garantissant une fiabilité de niveau production sans changement d’API par rapport à la préversion du 20 mai.
- Mise hors service de la préversion : Les endpoints de préversion étaient programmés pour être arrêtés le 15 juillet 2025 ; les utilisateurs doivent migrer vers l’endpoint GA avant cette date.
Depuis juillet 2025, Gemini 2.5 Flash est désormais disponible publiquement et stable (aucun changement par rapport à gemini-2.5-flash-preview-05-20). Si vous utilisez gemini-2.5-flash-preview-04-17, la tarification de préversion existante se poursuivra jusqu’à la mise hors service programmée de l’endpoint du modèle le 15 juillet 2025, date à laquelle il sera arrêté. Vous pouvez migrer vers le modèle en disponibilité générale "gemini-2.5-flash".
Plus rapide, moins cher, plus intelligent :
- Objectifs de conception : faible latence + haut débit + faible coût ;
- Accélération globale du raisonnement, du traitement multimodal et des tâches sur textes longs ;
- L’utilisation de tokens est réduite de 20–30%, ce qui diminue significativement les coûts de raisonnement.
Spécifications techniques
Fenêtre de contexte en entrée : jusqu’à 1 million de tokens, permettant une rétention de contexte étendue.
Tokens en sortie : capable de générer jusqu’à 8,192 tokens par réponse.
Modalités prises en charge : texte, images, audio et vidéo.
Plateformes d’intégration : disponible via Google AI Studio et Vertex AI.
Tarification : modèle tarifaire compétitif basé sur les tokens, facilitant des déploiements économiques.
Détails techniques
Sous le capot, Gemini 2.5 Flash est un grand modèle de langage basé sur des transformeurs, entraîné sur un mélange de données web, de code, d’images et de vidéos. Les principales spécifications techniques incluent :
Entraînement multimodal : Conçu pour aligner plusieurs modalités, Flash peut mêler de façon fluide du texte avec des images, de la vidéo ou de l’audio, utile pour des tâches comme le résumé vidéo ou le sous-titrage audio.
Processus de réflexion dynamique : Met en œuvre une boucle de raisonnement interne où le modèle planifie et décompose des invites complexes avant la sortie finale.
Budgets de réflexion configurables : Le thinking_budget peut être défini de 0 (aucun raisonnement) jusqu’à 24,576 tokens, permettant des arbitrages entre latence et qualité de réponse.
Intégration d’outils : Prend en charge Grounding with Google Search, Code Execution, URL Context et Function Calling, permettant des actions réelles directement à partir d’invites en langage naturel.
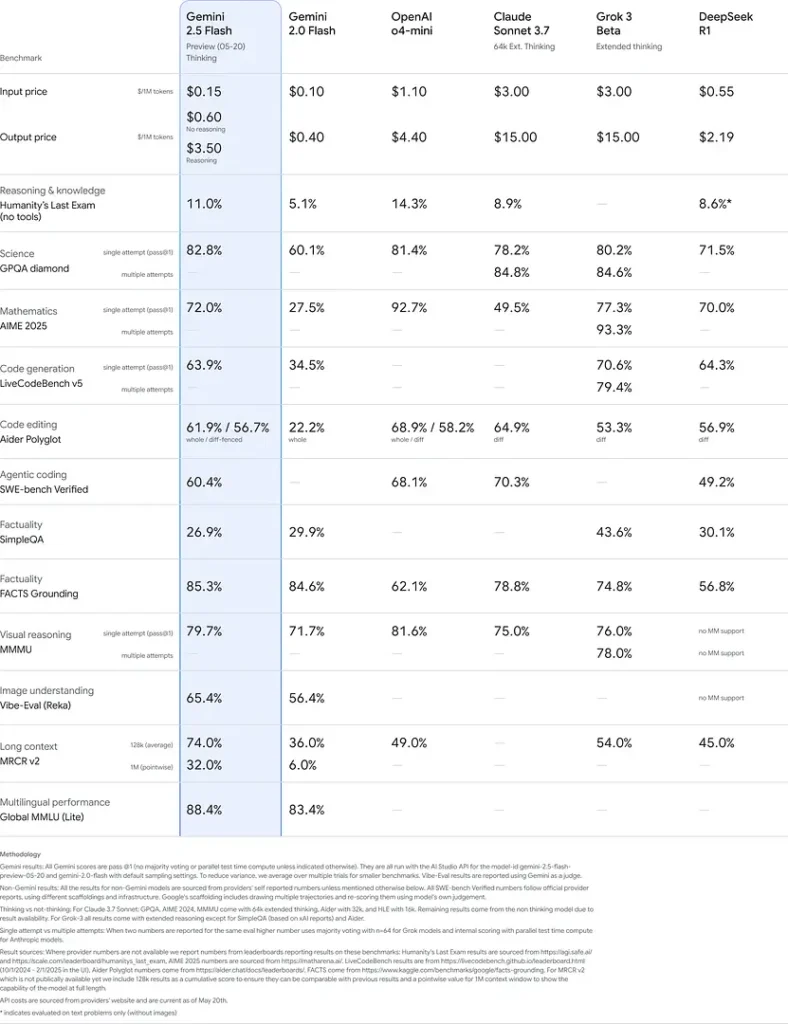
Performances de référence
Dans des évaluations rigoureuses, Gemini 2.5 Flash démontre des performances de premier plan dans l’industrie :
- LMArena Hard Prompts : Classé juste derrière 2.5 Pro sur le difficile benchmark Hard Prompts, démontrant de solides capacités de raisonnement multi‑étapes.
- Score MMLU de 0.809 : Dépasse la performance moyenne des modèles avec une précision MMLU de 0.809, reflétant une vaste connaissance des domaines et de fortes aptitudes de raisonnement.
- Latence et débit : Atteint une vitesse de décodage de 271.4 tokens/sec avec un 0.29 s Time-to-First-Token, ce qui le rend idéal pour des charges sensibles à la latence.
- Leader prix‑performances : À \$0.26/1 M tokens, Flash dépasse de nombreux concurrents tout en égalant ou surpassant leurs résultats sur des benchmarks clés.
Ces résultats indiquent l’avantage concurrentiel de Gemini 2.5 Flash en matière de raisonnement, de compréhension scientifique, de résolution de problèmes mathématiques, de programmation, d’interprétation visuelle et de capacités multilingues :
Limitations
Bien que puissant, Gemini 2.5 Flash présente certaines limitations :
- Risques de sécurité : Le modèle peut adopter un ton « moralisateur » et produire des sorties plausibles mais incorrectes ou biaisées (hallucinations), en particulier sur des cas limites. Une supervision humaine rigoureuse reste essentielle.
- Limitations de débit : L’utilisation de l’API est contrainte par des limites de taux (10 RPM, 250,000 TPM, 250 RPD sur les niveaux par défaut), ce qui peut affecter les traitements par lots ou les applications à fort volume.
- Plancher d’intelligence : Bien qu’exceptionnel pour un modèle « flash », il reste moins précis que 2.5 Pro sur les tâches agentiques les plus exigeantes comme le codage avancé ou la coordination multi‑agents.
- Compromis de coût : Bien qu’offrant le meilleur rapport prix‑performances, l’utilisation intensive du mode thinking augmente la consommation totale de tokens, ce qui accroît les coûts pour les invites nécessitant un raisonnement approfondi.