Spécifications techniques de GPT-5.4 Mini
| Élément | GPT-5.4 Mini (estimation basée sur les informations officielles + validation croisée) |
|---|---|
| Famille de modèle | Série GPT-5.4 (variante « mini » économique) |
| Fournisseur | OpenAI |
| Types d’entrée | Texte, Image |
| Types de sortie | Texte |
| Fenêtre de contexte | 400 000 tokens |
| Nombre max de tokens en sortie | 128 000 tokens |
| Date limite des connaissances | ~31 mai 2024 (hérite de la lignée mini) |
| Prise en charge du raisonnement | Oui (allégée par rapport à GPT-5.4 complet) |
| Prise en charge des outils | Appel de fonctions, recherche web, recherche de fichiers, agents (déduit de la famille GPT-5) |
| Positionnement | Modèle quasi de pointe, rapide et économique |
Qu’est-ce que GPT-5.4 Mini ?
GPT-5.4 Mini est une variante rapide et économique de GPT-5.4 conçue pour des charges de travail à fort volume sensibles à la latence. Il intègre une part importante des capacités de raisonnement, de programmation et multimodales de GPT-5.4 dans un modèle plus petit et plus rapide, optimisé pour des systèmes à l’échelle de la production.
Par rapport aux précédents modèles « mini », GPT-5.4 Mini est positionné comme un petit modèle quasi de pointe, ce qui signifie qu’il s’approche des performances d’un modèle phare tout en réduisant fortement les coûts et le temps de réponse.
Principales caractéristiques de GPT-5.4 Mini
- Inférence à haute vitesse : optimisé pour les applications à faible latence telles que les chatbots, les copilotes et les systèmes en temps réel
- Grande fenêtre de contexte (400K) : prend en charge les documents longs, les workflows en plusieurs étapes et la mémoire des agents
- Solide prise en charge du code et des agents : conçu pour l’utilisation d’outils, le raisonnement en plusieurs étapes et les tâches déléguées à des sous-agents
- Entrée multimodale : accepte à la fois des entrées textuelles et des images pour des workflows plus riches
- Montée en charge économique : nettement moins cher que GPT-5.4 tout en conservant de solides capacités de raisonnement
- Optimisation des pipelines d’agents : idéal pour les architectures multi-modèles où les grands modèles planifient et les mini modèles exécutent
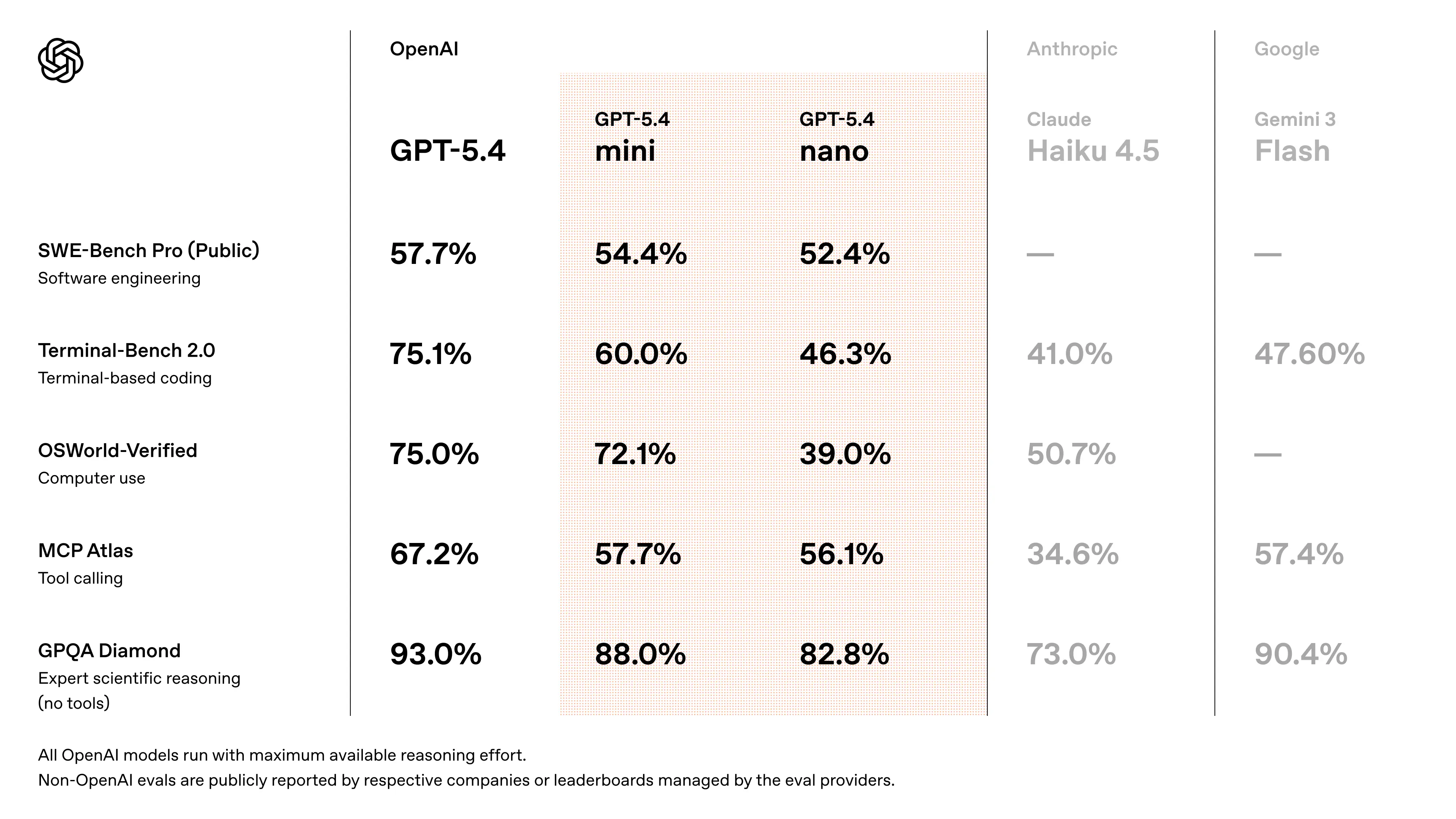
Performances de benchmark de GPT-5.4 Mini
- S’approche des performances de GPT-5.4 sur les tâches de programmation de type SWE-Bench (~94–95 % des performances du modèle phare) (estimation validée par recoupement à partir de discussions de lancement)
- Améliorations significatives par rapport à GPT-5 Mini sur :
- la précision du raisonnement
- la fiabilité de l’utilisation des outils
- la compréhension multimodale
- Conçu pour surpasser les précédentes générations de modèles « mini » dans les workflows d’agents et les benchmarks de programmation
- Mesures de vitesse : les premiers testeurs API rapportent ~180–190 tokens/s sur GPT-5.4 Mini (contre ~55–120 t/s pour les anciennes variantes GPT-5 mini selon les modes de priorité).
👉 À retenir : GPT-5.4 Mini offre des performances quasi de pointe pour une fraction du coût et de la latence, ce qui en fait un excellent choix pour les systèmes évolutifs.
Cas d’usage représentatifs
- Assistants de programmation et éditeurs (plugins IDE, Copilot) : l’analyse rapide du contexte, l’exploration du codebase et les complétions rapides font de GPT-5.4 Mini un choix idéal pour les suggestions dans l’éditeur lorsque le délai avant le premier token est important. GitHub Copilot constitue une intégration précoce.
- Sous-agents / workers délégués : lorsqu’un agent maître délègue des tâches courtes et rapides (mise en forme, petites étapes de raisonnement, recherches de type grep) à un worker rapide et peu coûteux. OpenAI positionne mini/nano pour ces rôles.
- Automatisation API à grand volume : génération massive de code, tri automatisé de tickets, résumé de logs à grande échelle lorsque le coût par appel et la latence sont les contraintes principales. Les chiffres de débit partagés par la communauté indiquent des avantages opérationnels concrets pour mini.
- Encapsulation d’outils et chaînes d’outils : appels d’outils rapides où le modèle orchestre des appels à des outils externes (search, grep, run tests) et renvoie des sorties compactes et exploitables. La famille GPT-5.4 inclut des capacités améliorées de « computer use ».
Comment accéder à l’API GPT-5.4 Mini
Étape 1 : S’inscrire pour obtenir une clé API
Connectez-vous à cometapi.com. Si vous n’êtes pas encore utilisateur, veuillez d’abord vous inscrire. Connectez-vous à votre console CometAPI. Obtenez la clé API d’accès à l’interface. Cliquez sur « Add Token » dans la section API token du centre personnel, obtenez la clé de token : sk-xxxxx, puis validez.

Étape 2 : Envoyer des requêtes à l’API GPT-5.4 Mini
Sélectionnez le point de terminaison « gpt-5.4-mini » pour envoyer la requête API et définissez le corps de la requête. La méthode de requête et le corps de la requête sont disponibles dans la documentation API de notre site web. Notre site web fournit également des tests Apifox pour votre commodité. Remplacez <YOUR_API_KEY> par votre véritable clé CometAPI issue de votre compte. L’URL de base est Chat Completions et Responses.
Insérez votre question ou votre demande dans le champ content — c’est à cela que le modèle répondra. Traitez la réponse API pour obtenir la réponse générée.
Étape 3 : Récupérer et vérifier les résultats
Traitez la réponse API pour obtenir la réponse générée. Après traitement, l’API renvoie l’état de la tâche et les données de sortie.