

Dans le paysage en constante évolution de l'intelligence artificielle, 2025 a été marquée par des avancées significatives dans le domaine des grands modèles de langage (LLM). Parmi les modèles phares figurent Qwen2.5 d'Alibaba, les modèles V3 et R1 de DeepSeek et ChatGPT d'OpenAI. Chacun de ces modèles apporte des fonctionnalités et des innovations uniques. Cet article examine les derniers développements de Qwen2.5, en comparant ses fonctionnalités et ses performances à celles de DeepSeek et de ChatGPT afin de déterminer lequel des modèles domine actuellement la course à l'IA.
Qu’est-ce que Qwen2.5 ?
Vue d'ensemble
Qwen 2.5 est le dernier modèle de langage dense et volumineux d'Alibaba Cloud, disponible en plusieurs tailles, de 0.5 à 72 milliards de paramètres. Il est optimisé pour le suivi d'instructions, les sorties structurées (par exemple, JSON, tableaux), le codage et la résolution de problèmes mathématiques. Avec une prise en charge de plus de 29 langues et une longueur de contexte allant jusqu'à 128 2.5 jetons, Qwen XNUMX est conçu pour les applications multilingues et spécifiques à un domaine.
Fonctionnalités clés
- Soutien multilingue: Prend en charge plus de 29 langues, s'adressant à une base d'utilisateurs mondiale.
- Longueur de contexte étendue:Gère jusqu'à 128 XNUMX jetons, permettant le traitement de longs documents et conversations.
- Variantes spécialisées:Comprend des modèles comme Qwen2.5-Coder pour les tâches de programmation et Qwen2.5-Math pour la résolution de problèmes mathématiques.
- Accessibilité:Disponible via des plateformes comme Hugging Face, GitHub et une interface Web récemment lancée à chat.qwenlm.ai.
Comment utiliser Qwen 2.5 localement ?
Vous trouverez ci-dessous un guide étape par étape pour 7 B Chat point de contrôle ; les tailles plus grandes ne diffèrent que par les exigences du GPU.
1. Prérequis matériels
| Modèle | vRAM pour 8 bits | vRAM pour 4 bits (QLoRA) | Taille du disque |
|---|---|---|---|
| Qwen 2.5‑7B | 14 Go | 10 Go | 13 Go |
| Qwen 2.5‑14B | 26 Go | 18 Go | 25 Go |
Une seule RTX 4090 (24 Go) suffit pour une inférence de 7 B avec une précision de 16 bits ; deux de ces cartes ou le déchargement du processeur plus la quantification peuvent gérer 14 B.
2. Installation
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. Script d'inférence rapide
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
La trust_remote_code=True le drapeau est requis car Qwen expédie une commande personnalisée Incorporation de position rotative emballage.
4. Réglage fin avec LoRA
Grâce aux adaptateurs LoRA à paramètres efficaces, vous pouvez former Qwen de manière spécialisée sur environ 50 24 paires de domaines (par exemple, médicaux) en moins de quatre heures sur un seul GPU de XNUMX Go :
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
Le fichier adaptateur résultant (~120 Mo) peut être fusionné ou chargé à la demande.
Facultatif : exécuter Qwen 2.5 en tant qu’API
CometAPI agit comme un hub centralisé pour les API de plusieurs modèles d'IA de premier plan, éliminant ainsi le besoin d'interagir séparément avec plusieurs fournisseurs d'API. API Comet Nous proposons un prix bien inférieur au prix officiel pour vous aider à intégrer l'API Qwen. Vous recevrez 1 $ sur votre compte après votre inscription et votre connexion ! Bienvenue pour découvrir CometAPI. Pour les développeurs souhaitant intégrer Qwen 2.5 à leurs applications :
Étape 1 : installer les bibliothèques nécessaires:
bash
pip install requests
Étape 2 : obtenir la clé API
- Accédez à API Comet.
- Connectez-vous avec votre compte CometAPI.
- Sélectionnez le Tableau de bord.
- Cliquez sur « Obtenir la clé API » et suivez les instructions pour générer votre clé.
Étape 3 : Implémenter les appels API
Utilisez les informations d'identification de l'API pour effectuer des requêtes vers Qwen 2.5.Remplacer avec votre clé CometAPI actuelle de votre compte.
Par exemple, en Python :
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
Cette intégration permet une incorporation transparente des capacités de Qwen 2.5 dans diverses applications, améliorant ainsi les fonctionnalités et l'expérience utilisateur.Sélectionnez le “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” Point de terminaison pour envoyer la requête API et définir le corps de la requête. La méthode et le corps de la requête sont disponibles dans la documentation API de notre site web. Notre site web propose également le test Apifox pour plus de commodité.
S'il vous plaît se référer à API Qwen 2.5 Max pour plus de détails sur l'intégration. CometAPI a mis à jour la dernière API QwQ-32BPour plus d'informations sur le modèle dans l'API Comet, veuillez consulter API doc.
Bonnes pratiques et conseils
| Scénario | Recommandation |
|---|---|
| Document long Q&R | Décomposez les passages en ≤ 16 100 jetons et utilisez des invites augmentées par récupération au lieu de contextes naïfs de XNUMX XNUMX pour réduire la latence. |
| Résultats structurés | Préfixez le message système avec : You are an AI that strictly outputs JSON. L'entraînement à l'alignement de Qwen 2.5 excelle dans la génération contrainte. |
| Compléter le code | complet » temperature=0.0 et top_p=1.0 pour maximiser le déterminisme, puis échantillonner plusieurs faisceaux (num_return_sequences=4) pour le classement. |
| Filtrage de sécurité | Utilisez le bundle d'expressions régulières open source « Qwen-Guardrails » d'Alibaba ou text-moderation-004 d'OpenAI comme premier passage. |
Limitations connues de Qwen 2.5
- Sensibilité à l'injection rapide. Les audits externes montrent des taux de réussite de jailbreak de 18 % sur Qwen 2.5-VL, ce qui rappelle que la taille même du modèle n'immunise pas contre les instructions adverses.
- Bruit OCR non latin. Lorsqu'il est affiné pour les tâches de vision-langage, le pipeline de bout en bout du modèle confond parfois les glyphes chinois traditionnels et simplifiés, nécessitant des couches de correction spécifiques au domaine.
- Falaise de mémoire GPU à 128 Ko. FlashAttention‑2 compense la RAM, mais un passage en avant dense de 72 B sur 128 K jetons nécessite toujours > 120 Go de vRAM ; les praticiens doivent utiliser la fonction Window-Attend ou KV-Cache.
Feuille de route et écosystème communautaire
L'équipe Qwen a laissé entendre que Qwen 3.0, ciblant un routage hybride (Dense + MoE) et un pré-apprentissage unifié parole-vision-texte. L'écosystème héberge déjà :
- Q-Agent – un agent de chaîne de pensée de style ReAct utilisant Qwen 2.5-14B comme politique.
- Alpaga financier chinois – un LoRA sur Qwen2.5‑7B formé avec 1 M de dépôts réglementaires.
- Plug-in Open Interpreter – échange GPT‑4 contre un point de contrôle Qwen local dans VS Code.
Consultez la page « Collection Qwen2.5 » de Hugging Face pour une liste continuellement mise à jour des points de contrôle, des adaptateurs et des harnais d’évaluation.
Analyse comparative : Qwen2.5 vs. DeepSeek et ChatGPT
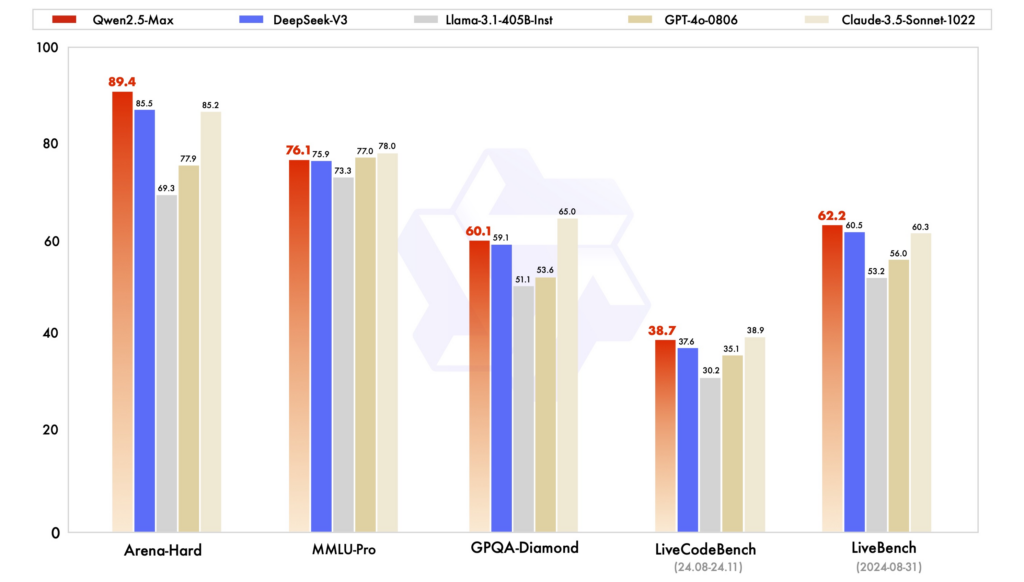
Repères de performances : Lors de diverses évaluations, Qwen2.5 a démontré d'excellentes performances dans les tâches exigeant raisonnement, codage et compréhension multilingue. DeepSeek-V3, avec son architecture MoE, excelle en efficacité et en évolutivité, offrant des performances élevées avec des ressources de calcul réduites. ChatGPT reste un modèle robuste, notamment pour les tâches linguistiques générales.
Efficacité et coût : Les modèles de DeepSeek se distinguent par leur apprentissage et leur inférence rentables, exploitant les architectures MoE pour activer uniquement les paramètres nécessaires par jeton. Qwen2.5, bien que dense, propose des variantes spécialisées pour optimiser les performances de tâches spécifiques. L'apprentissage de ChatGPT a nécessité des ressources de calcul importantes, ce qui a eu un impact sur ses coûts opérationnels.
Accessibilité et disponibilité open source : Qwen2.5 et DeepSeek ont adopté les principes open source à des degrés divers, avec des modèles disponibles sur des plateformes comme GitHub et Hugging Face. Le lancement récent d'une interface web pour Qwen2.5 améliore son accessibilité. ChatGPT, bien que non open source, est largement accessible via la plateforme et les intégrations d'OpenAI.
Conclusion
Qwen 2.5 se situe à un endroit idéal entre services premium à poids fermé et modèles de loisirs entièrement ouvertsSon mélange de licences permissives, de force multilingue, de compétence contextuelle à long terme et d’une large gamme d’échelles de paramètres en fait une base convaincante pour la recherche et la production.
Alors que le paysage des LLM open source progresse à toute vitesse, le projet Qwen démontre que transparence et performance peuvent coexisterPour les développeurs, les scientifiques des données et les décideurs politiques, maîtriser Qwen 2.5 aujourd’hui est un investissement dans un avenir de l’IA plus pluraliste et plus propice à l’innovation.