

Les 19 et 20 novembre 2025, OpenAI a publié deux mises à jour liées mais distinctes : GPT-5.1-Codex-Max, un nouveau modèle de codage agentique pour Codex qui met l'accent sur le codage à long terme, l'efficacité des jetons et la « compaction » pour supporter les sessions multi-fenêtres ; et GPT-5.1 Pro, un modèle ChatGPT de niveau Pro mis à jour, optimisé pour des réponses plus claires et plus pertinentes dans un contexte professionnel complexe.
Qu'est-ce que GPT-5.1-Codex-Max et quel problème tente-t-il de résoudre ?
GPT-5.1-Codex-Max est un modèle Codex spécialisé d'OpenAI, optimisé pour les flux de travail de codage qui nécessitent raisonnement et exécution soutenus à long termeLà où les modèles ordinaires peuvent être mis à mal par des contextes extrêmement longs (par exemple, des refactorisations multi-fichiers, des boucles d'agents complexes ou des tâches CI/CD persistantes), Codex-Max est conçu pour compacter et gérer automatiquement l'état de la session sur plusieurs fenêtres de contexteCela lui permet de continuer à fonctionner de manière cohérente même lorsqu'un seul projet couvre plusieurs milliers (voire plus) de jetons. OpenAI présente Codex-Max comme la prochaine étape pour rendre les agents capables de coder véritablement utiles pour des travaux d'ingénierie de grande envergure.
Qu'est-ce que GPT-5.1-Codex-Max et quel problème tente-t-il de résoudre ?
GPT-5.1-Codex-Max est un modèle Codex spécialisé d'OpenAI, optimisé pour les flux de travail de codage qui nécessitent raisonnement et exécution soutenus à long termeLà où les modèles ordinaires peuvent être mis à mal par des contextes extrêmement longs (par exemple, des refactorisations multi-fichiers, des boucles d'agents complexes ou des tâches CI/CD persistantes), Codex-Max est conçu pour compacter et gérer automatiquement l'état de la session sur plusieurs fenêtres de contexte, lui permettant de continuer à fonctionner de manière cohérente en tant que projet unique couvrant plusieurs milliers (ou plus) de jetons.
OpenAI le décrit comme « plus rapide, plus intelligent et plus économe en jetons à chaque étape du cycle de développement », et il est explicitement destiné à remplacer GPT-5.1-Codex comme modèle par défaut dans les surfaces Codex.
Aperçu des fonctionnalités
- Compaction pour une continuité multi-fenêtres : élague et préserve le contexte critique pour un fonctionnement cohérent sur des millions de jetons et pendant des heures. 0
- Amélioration de l'efficacité des jetons par rapport à GPT-5.1-Codex : jusqu'à ~30% de jetons de réflexion en moins pour un effort de raisonnement similaire sur certains benchmarks de code.
- Durabilité des agents à long terme : Des observations internes ont montré qu'il pouvait supporter des boucles d'agents de plusieurs heures/plusieurs jours (OpenAI a documenté des exécutions internes de plus de 24 heures).
- Intégrations de plateforme : Disponible dès aujourd'hui dans Codex CLI, les extensions IDE, le cloud et les outils de revue de code ; accès API à venir.
- Prise en charge de l'environnement Windows : OpenAI souligne en particulier que Windows est pris en charge pour la première fois dans les flux de travail Codex, élargissant ainsi la portée des développeurs dans le monde réel.
Comment se compare-t-il aux produits concurrents (par exemple, GitHub Copilot, d'autres IA de codage) ?
GPT-5.1-Codex-Max se présente comme un collaborateur plus autonome et capable d'une vision à long terme, contrairement aux outils de complétion à la demande. Si Copilot et les assistants similaires excellent dans la complétion rapide au sein de l'éditeur, Codex-Max se distingue par sa capacité à orchestrer des tâches complexes, à maintenir la cohérence de l'état entre les sessions et à gérer les flux de travail nécessitant planification, tests et itérations. Cela dit, la meilleure approche pour la plupart des équipes sera hybride : utiliser Codex-Max pour l'automatisation complexe et les tâches d'agent soutenues, et des assistants plus légers pour les complétions au niveau du texte.
Comment fonctionne GPT-5.1-Codex-Max ?
Qu’est-ce que la « compaction » et comment permet-elle un travail de longue durée ?
Une avancée technique centrale est compactage— un mécanisme interne qui élague l'historique des sessions tout en préservant les éléments de contexte essentiels afin que le modèle puisse continuer à fonctionner de manière cohérente. plusieurs Fenêtres de contexte. Concrètement, cela signifie que les sessions Codex approchant leur limite de contexte seront compactées (les jetons les plus anciens ou de moindre valeur seront résumés/conservés) afin que l'agent dispose d'une fenêtre vierge et puisse poursuivre les itérations jusqu'à la fin de la tâche. OpenAI rapporte des exécutions internes où le modèle a travaillé sans interruption sur des tâches pendant plus de 24 heures.
Raisonnement adaptatif et efficacité des jetons
GPT-5.1-Codex-Max applique des stratégies de raisonnement améliorées qui optimisent l'utilisation des jetons : selon les tests internes publiés par OpenAI, le modèle Max atteint des performances similaires, voire supérieures, à celles de GPT-5.1-Codex tout en utilisant nettement moins de jetons de « réflexion » (OpenAI cite environ…). 30% de moins Le modèle a validé les jetons de réflexion sur le banc d'essai SWE en utilisant un effort de raisonnement équivalent. Il propose également un mode d'effort de raisonnement « Très élevé (xhigh) » pour les tâches peu sensibles à la latence, permettant ainsi de consacrer davantage de ressources de raisonnement interne à l'obtention de résultats de meilleure qualité.
Intégrations de systèmes et outils d'agents
Codex-Max est distribué au sein des flux de travail Codex (interface de ligne de commande, extensions IDE, cloud et plateformes de revue de code) afin de pouvoir interagir avec les chaînes d'outils de développement. Les premières intégrations concernent l'interface de ligne de commande Codex et les agents IDE (VS Code, JetBrains, etc.), l'accès à l'API étant prévu ultérieurement. L'objectif est de concevoir une IA capable d'exécuter des flux de travail en plusieurs étapes : ouvrir des fichiers, exécuter des tests, corriger les erreurs, refactoriser et réexécuter le processus.
Quelles sont les performances de GPT-5.1-Codex-Max sur les benchmarks et dans des cas concrets ?
Raisonnement soutenu et tâches à long terme
Les évaluations font état d'améliorations mesurables dans le raisonnement soutenu et les tâches à long terme :
- évaluations internes d'OpenAICodex-Max peut exécuter des tâches pendant plus de 24 heures lors d'expérimentations internes. De plus, l'intégration de Codex aux outils de développement a permis d'accroître les indicateurs de productivité internes (par exemple, l'utilisation et le débit des demandes de fusion). Ces affirmations internes d'OpenAI témoignent d'améliorations concrètes de la productivité au niveau des tâches.
- **Évaluations indépendantes (METR)**Le rapport indépendant du METR a mesuré horizon temporel observé à 50 % (une statistique représentant le temps médian pendant lequel le modèle peut maintenir de manière cohérente une tâche longue) pour GPT-5.1-Codex-Max à environ 2 Heures 40 minutes (Avec un large intervalle de confiance), contre 2 heures et 17 minutes pour GPT-5 lors de mesures comparables — une amélioration significative et conforme à la tendance en matière de cohérence soutenue. La méthodologie et l’intervalle de confiance de METR mettent l’accent sur la variabilité, mais le résultat confirme que Codex-Max améliore les performances pratiques à long terme.
Références de code
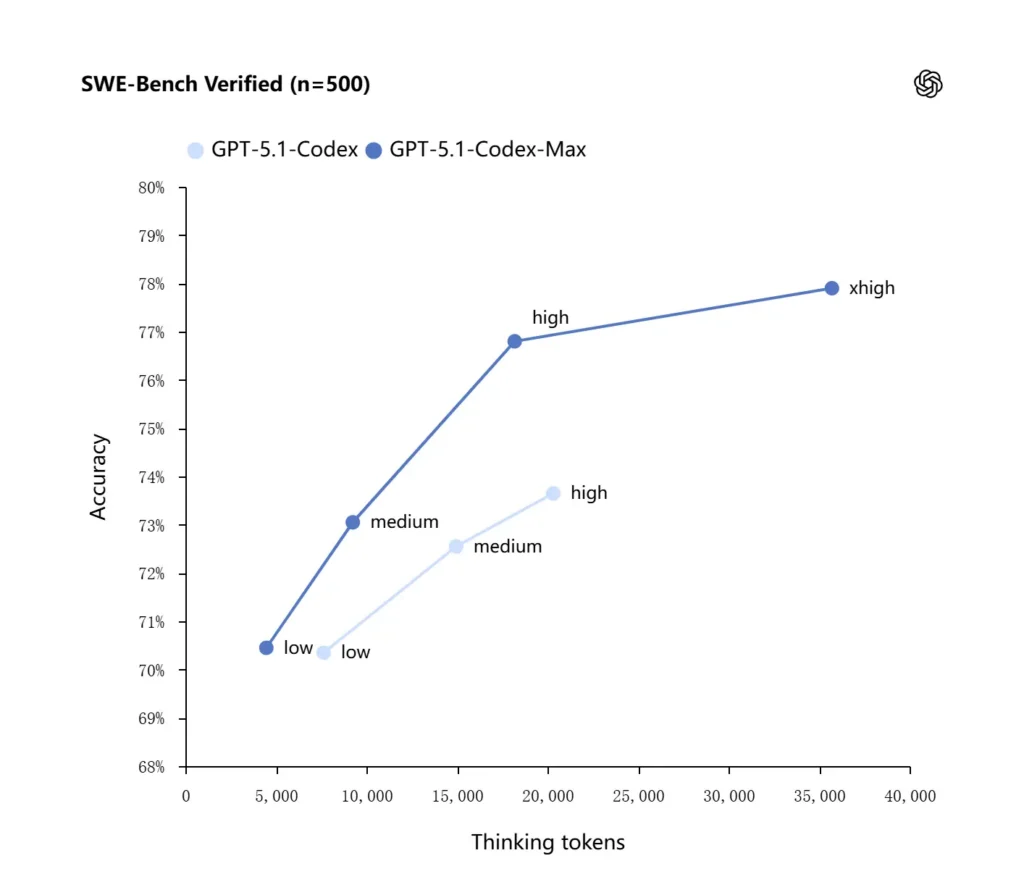
OpenAI annonce des résultats améliorés sur les évaluations de codage de pointe, notamment sur SWE-bench Verified où GPT-5.1-Codex-Max surpasse GPT-5.1-Codex grâce à une meilleure efficacité d'utilisation des jetons. L'entreprise souligne que, pour un effort de raisonnement « moyen » identique, le modèle Max produit de meilleurs résultats en utilisant environ 30 % de jetons de réflexion en moins. Pour les utilisateurs autorisant un raisonnement interne plus long, le mode xhigh permet d'améliorer encore les réponses, au prix d'une latence accrue.
| GPT‑5.1-Codex (élevé) | GPT‑5.1-Codex-Max (xhigh) | |
| Vérifié par banc d'essai SWE (n=500) | 73.7% | 77.9% |
| SWE-Lancer IC SWE | 66.3% | 79.9% |
| Terminal-Bench 2.0 | 52.8% | 58.1% |
En quoi GPT-5.1-Codex-Max se compare-t-il à GPT-5.1-Codex ?
Différences de performance et d'objectif
- Portée: GPT-5.1-Codex était une variante de codage haute performance de la famille GPT-5.1 ; Codex Max est explicitement un successeur actif à long terme, conçu pour être la solution par défaut recommandée pour Codex et les environnements similaires à Codex.
- Efficacité du jeton : Codex-Max affiche des gains d'efficacité en matière de jetons matériels (l'affirmation d'OpenAI concernant une réduction d'environ 30 % des jetons de réflexion) sur le banc d'essai SWE et lors d'une utilisation interne.
- Gestion du contexte : Codex-Max introduit la compaction et la gestion native de plusieurs fenêtres pour prendre en charge les tâches qui dépassent la capacité d'une seule fenêtre de contexte ; Codex ne fournissait pas nativement cette fonctionnalité à la même échelle.
- Préparation de l'outillage : Codex-Max est installé par défaut comme modèle Codex sur l'interface de ligne de commande, l'IDE et les plateformes de revue de code, ce qui marque une migration pour les flux de travail des développeurs en production.
Quand utiliser quel modèle ?
- Utilisez GPT-5.1-Codex pour une assistance au codage interactif, des modifications rapides, des refactorisations mineures et des cas d'utilisation à faible latence où tout le contexte pertinent tient facilement dans une seule fenêtre.
- Utiliser GPT-5.1-Codex-Max pour les refactorisations multi-fichiers, les tâches automatisées nécessitant de nombreux cycles d'itération, les flux de travail de type CI/CD, ou lorsque vous avez besoin que le modèle conserve une perspective au niveau du projet à travers de nombreuses interactions.
Des modèles de consignes pratiques et des exemples pour obtenir les meilleurs résultats ?
Des modèles d'incitation qui fonctionnent bien
- Soyez explicite quant aux objectifs et aux contraintes : « Refactoriser X, préserver l'API publique, conserver les noms des fonctions et s'assurer que les tests A, B et C réussissent. »
- Fournir un contexte minimal reproductible : Veuillez inclure le lien vers le test ayant échoué, les traces de pile et les extraits de fichiers pertinents plutôt que de soumettre l'intégralité des dépôts. Codex-Max se chargera de la compression de l'historique si nécessaire.
- Utilisez des instructions étape par étape pour les tâches complexes : divisez les tâches importantes en une séquence de sous-tâches et laissez Codex-Max les parcourir (par exemple, « 1) exécuter les tests 2) corriger les 3 tests les plus défaillants 3) exécuter le linter 4) résumer les modifications »).
- Demandez des explications et des différences : Veuillez demander à la fois le correctif et une brève explication afin que les examinateurs humains puissent rapidement évaluer la sécurité et l'intention.
Exemples de modèles d'invites
tâche de refactorisation
« Refactoriser le
payment/module pour extraire le traitement des paiements danspayment/processor.pyMaintenir la stabilité des signatures des fonctions publiques pour les appelants existants. Créer des tests unitaires pourprocess_payment()qui couvrent les cas de succès, les défaillances réseau et les cartes invalides. Exécutez la suite de tests et renvoyez les tests ayant échoué ainsi qu'un correctif au format de différence unifié.
Correction de bugs + test
« Un test
tests/test_user_auth.py::test_token_refreshL'exécution échoue avec la trace d'erreur . Recherchez la cause racine, proposez une solution avec un minimum de modifications et ajoutez un test unitaire pour éviter toute régression. Appliquez le correctif et exécutez les tests.
génération itérative de relations publiques
« Implémenter la fonctionnalité X : ajouter un point de terminaison
POST /api/exportqui diffuse les résultats d'exportation et est authentifié. Créez le point de terminaison, ajoutez la documentation, créez des tests et ouvrez une PR avec un résumé et une liste de vérification des éléments manuels.
Pour la plupart d'entre eux, commencez par moyenne effort; passer à xhigh lorsque vous avez besoin que le modèle effectue un raisonnement approfondi sur de nombreux fichiers et plusieurs itérations de test.
Comment accéder à GPT-5.1-Codex-Max
Où il est disponible aujourd'hui
OpenAI a intégré GPT-5.1-Codex-Max dans Outillage Codex Aujourd'hui : l'interface de ligne de commande Codex, les extensions IDE, le cloud et les flux de revue de code utilisent Codex-Max par défaut (Codex-Mini est disponible en option). L'API sera bientôt disponible ; GitHub Copilot propose des versions préliminaires publiques incluant GPT-5.1 et les modèles de la série Codex.
Les développeurs peuvent accéder à GPT-5.1-Codex-Max et API GPT-5.1-Codex via CometAPI. Pour commencer, explorez les capacités du modèle deAPI Comet dans le cour de récréation Consultez le guide de l'API pour des instructions détaillées. Avant d'accéder à CometAPI, assurez-vous d'être connecté à CometAPI et d'avoir obtenu la clé API. AvecetAPI proposer un prix bien inférieur au prix officiel pour vous aider à vous intégrer.
Prêt à partir ?→ Inscrivez-vous à CometAPI dès aujourd'hui !
Si vous souhaitez connaître plus de conseils, de guides et d'actualités sur l'IA, suivez-nous sur VK, X et Discord!
Démarrage rapide (guide pratique étape par étape)
- Assurez-vous d'avoir accès : Veuillez vérifier que votre plan produit ChatGPT/Codex (Plus, Pro, Business, Edu, Enterprise) ou votre plan API développeur prend en charge les modèles de la famille GPT-5.1/Codex.
- Installez l'extension Codex CLI ou IDE : Pour exécuter des tâches de code en local, installez l'interface de ligne de commande Codex ou l'extension Codex pour VS Code, JetBrains ou Xcode, selon votre configuration. Par défaut, l'outil utilisera GPT-5.1-Codex-Max dans les configurations compatibles.
- Choisir l'effort de raisonnement : commencer avec moyenne L'effort est suffisant pour la plupart des tâches. Pour un débogage approfondi, des refactorisations complexes ou lorsque vous souhaitez que le modèle effectue des calculs plus poussés et que la latence de réponse n'est pas un problème, passez à Élevée or xhigh modes. Pour des petites réparations rapides, faible est raisonnable.
- Fournir le contexte du dépôt : Indiquez au modèle un point de départ clair : une URL de dépôt ou un ensemble de fichiers, ainsi qu’une brève instruction (par exemple : « Refactoriser le module de paiement pour utiliser les E/S asynchrones et ajouter des tests unitaires, en conservant les contrats au niveau des fonctions »). Codex-Max compactera l’historique à mesure qu’il approchera des limites du contexte et poursuivra le travail.
- Itérer avec des tests : Une fois le modèle généré, exécutez les suites de tests et intégrez les échecs dans la session en cours. La compaction et la continuité multi-fenêtres permettent à Codex-Max de conserver le contexte des tests ayant échoué et de poursuivre l'exécution.
Conclusion:
GPT-5.1-Codex-Max représente une avancée majeure vers des assistants de programmation autonomes capables de gérer des tâches d'ingénierie complexes et de longue durée avec une efficacité et un raisonnement améliorés. Ses avancées techniques (compactage, modes d'effort de raisonnement, entraînement à l'environnement Windows) le rendent particulièrement adapté aux organisations d'ingénierie modernes, à condition que les équipes l'associent à des contrôles opérationnels rigoureux, à des politiques claires de supervision humaine et à une surveillance robuste. Pour les équipes qui l'adoptent avec précaution, Codex-Max a le potentiel de transformer la conception, les tests et la maintenance des logiciels, en métamorphosant les tâches répétitives d'ingénierie en une collaboration à plus forte valeur ajoutée entre humains et modèles.