

DeepSeek a publié Recherche profonde V3.2 successeur de sa gamme V3.x et d'un accompagnement DeepSeek-V3.2-Spécial Cette variante, que l'entreprise présente comme une version haute performance axée sur le raisonnement pour une utilisation avec des agents et des outils, s'appuie sur des travaux expérimentaux (V3.2-Exp) et introduit des capacités de raisonnement supérieures, une édition spéciale optimisée pour des performances de haut niveau en mathématiques et en programmation compétitive, ainsi qu'un système « réflexion + outil » à double mode, une première en son genre selon DeepSeek. Ce système intègre étroitement le raisonnement pas à pas interne avec l'invocation d'outils externes et les flux de travail des agents.
Qu’est-ce que DeepSeek V3.2 — et en quoi la version V3.2-Speciale diffère-t-elle ?
DeepSeek-V3.2 est le successeur officiel de la branche expérimentale V3.2-Exp de DeepSeek. Il est décrit par DeepSeek comme un Modèle familial « axé sur le raisonnement » conçu pour les agents, c'est-à-dire des modèles optimisés non seulement pour une qualité conversationnelle naturelle, mais aussi spécifiquement pour l'inférence en plusieurs étapes, l'invocation d'outils et un raisonnement fiable de type chaîne de pensée lors de l'utilisation dans des environnements comprenant des outils externes (API, exécution de code, connecteurs de données).
Qu'est-ce que DeepSeek-V3.2 (base) ?
- Conçue comme la version de production grand public succédant à la gamme expérimentale V3.2-Exp ; destinée à une large diffusion via l'application/le site web/l'API de DeepSeek.
- Maintient un équilibre entre efficacité de calcul et raisonnement robuste pour les tâches automatisées.
Qu'est-ce que DeepSeek-V3.2-Speciale ?
DeepSeek-V3.2-Spécial Il s'agit d'une variante que DeepSeek commercialise comme une « Édition Spéciale » aux capacités accrues, optimisée pour le raisonnement de haut niveau, les mathématiques avancées et les performances des agents. Présentée comme une variante plus performante qui « repousse les limites des capacités de raisonnement », DeepSeek propose actuellement Speciale comme un modèle accessible uniquement via une API avec un routage d'accès temporaire. Les premiers tests de performance suggèrent qu'elle est en mesure de rivaliser avec les modèles propriétaires haut de gamme dans les tests de raisonnement et de programmation.
Quelles sont les origines et les choix techniques qui ont mené à la version 3.2 ?
La version 3.2 s'inscrit dans la continuité du processus d'ingénierie itératif déployé par DeepSeek tout au long de l'année 2025 : V3 → V3.1 (Terminus) → V3.2-Exp (étape expérimentale) → V3.2 → V3.2-Speciale. L'étape expérimentale V3.2-Exp a introduit DeepSeek Sparse Attention (DSA) — un mécanisme d'attention parcimonieuse à grain fin, conçu pour réduire les coûts de mémoire et de calcul pour les contextes très longs, tout en préservant la qualité du résultat. Ces recherches sur les algorithmes de diffusion et d'analyse (DSA) et les travaux de réduction des coûts ont constitué une étape technique essentielle pour la famille V3.2 officielle.
Quelles sont les nouveautés de la version officielle DeepSeek 3.2 ?
1) Amélioration des capacités de raisonnement — comment le raisonnement est-il amélioré ?
DeepSeek commercialise la version 3.2 sous le nom de « Le raisonnement d'abord. » Cela signifie que l'architecture et le réglage fin se concentrent sur la réalisation fiable d'inférences en plusieurs étapes, le maintien des chaînes de pensée internes et la prise en charge des types de délibération structurée dont les agents ont besoin pour utiliser correctement les outils externes.
Concrètement, les améliorations comprennent :
- L'entraînement et le RLHF (ou des procédures d'alignement similaires) sont ajustés pour encourager la résolution explicite de problèmes par étapes et des états intermédiaires stables (utiles pour le raisonnement mathématique, la génération de code en plusieurs étapes et les tâches logiques).
- Des choix architecturaux et de fonctions de perte qui préservent des fenêtres de contexte plus longues et permettent au modèle de faire référence fidèlement aux étapes de raisonnement antérieures.
- Modes pratiques (voir « mode double » ci-dessous) qui permettent au même modèle de fonctionner soit en mode « conversation » plus rapide, soit en mode « réflexion » délibératif où il passe intentionnellement par des étapes intermédiaires avant d’agir.
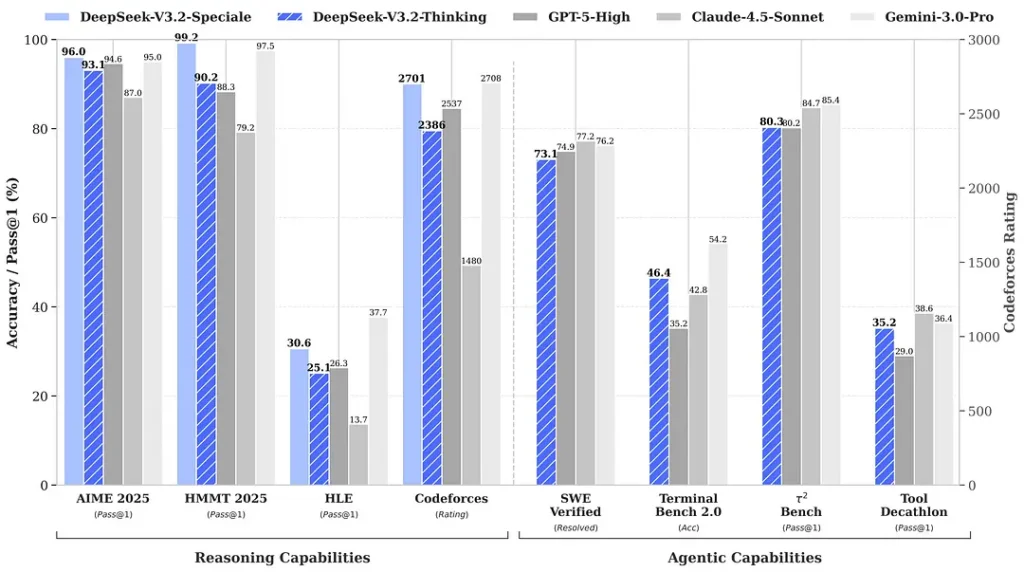
Les tests de performance cités lors de la sortie font état de gains notables dans les suites de calcul et de raisonnement ; les premiers tests de performance indépendants de la communauté font également état de scores impressionnants sur des ensembles d’évaluation concurrentiels :
2) Des performances révolutionnaires dans l'édition spéciale — à quel point sont-elles meilleures ?
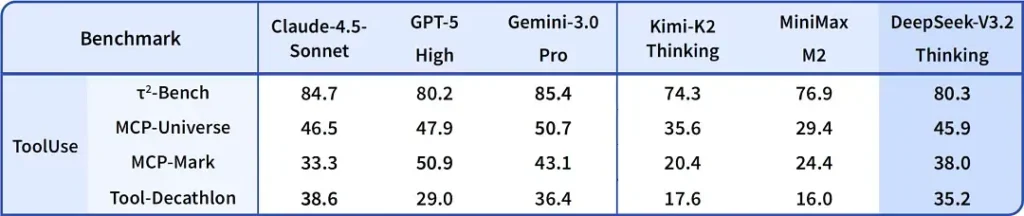
DeepSeek-V3.2-Spécial Speciale promet une précision de raisonnement et une orchestration des agents nettement supérieures à la version standard V3.2. Le fournisseur la présente comme une couche de performance conçue pour les charges de travail de raisonnement intensives et les tâches complexes des agents. Actuellement disponible uniquement via une API, Speciale est proposée temporairement comme un point d'accès plus performant (DeepSeek a indiqué que sa disponibilité serait initialement limitée). La version Speciale intègre le modèle mathématique précédent, DeepSeek-Math-V2. Elle est capable de démontrer des théorèmes mathématiques et de vérifier le raisonnement logique de manière autonome. Elle a obtenu des résultats remarquables dans de nombreuses compétitions internationales.
- 🥇 Médaille d'or aux Olympiades internationales de mathématiques (OIM)
- 🥇 Médaille d'or des Olympiades mathématiques chinoises (CMO)
- 🥈 Deuxième place au concours international de programmation informatique (ICPC) (concours humain)
- 🥉 IOI (Olympiades internationales d'informatique) Dixième place (Concours humain)
| référence | GPT-5 High | Gemini-3.0 Pro | Kimi-K2 Réflexion | DeepSeek-V3.2 Réflexion | DeepSeek-V3.2 Spécial |
|---|---|---|---|---|---|
| AIME 2025 | 94.6 (13k) | 95.0 (15k) | 94.5 (24k) | 93.1 (16k) | 96.0 (23k) |
| HMMT 2025 février | 88.3 (16k) | 97.5 (16k) | 89.4 (31k) | 92.5 (19k) | 99.2 (27k) |
| HMMT Nov 2025 | 89.2 (20k) | 93.3 (15k) | 89.2 (29k) | 90.2 (18k) | 94.4 (25k) |
| IMOAnswerBench | 76.0 (31k) | 83.3 (18k) | 78.6 (37k) | 78.3 (27k) | 84.5 (45k) |
| LiveCodeBench | 84.5 (13k) | 90.7 (13k) | 82.6 (29k) | 83.3 (16k) | 88.7 (27k) |
| CodeForces | 2537 (29k) | 2708 (22k) | - | 2386 (42k) | 2701 (77k) |
| GPQA Diamant | 85.7 (8k) | 91.9 (8k) | 84.5 (12k) | 82.4 (7k) | 85.7 (16k) |
| ENFER | 26.3 (15k) | 37.7 (15k) | 23.9 (24k) | 25.1 (21k) | 30.6 (35k) |
3) Première mise en œuvre d'un système à double mode « réflexion + outil »
L'une des affirmations les plus intéressantes sur le plan pratique dans la version 3.2 est une flux de travail à double mode qui sépare (et vous permet de choisir entre) un fonctionnement conversationnel rapide et un mode de « réflexion » plus lent et délibéré qui s'intègre étroitement à l'utilisation de l'outil.
- Mode « Chat / rapide » : Conçu pour des conversations à faible latence avec les utilisateurs, des réponses concises et moins de traces de raisonnement interne — idéal pour une assistance informelle, des questions-réponses courtes et les applications sensibles à la vitesse.
- Mode « réflexion / raisonnement » : Optimisé pour une logique rigoureuse, une planification par étapes et l'orchestration d'outils externes (API, requêtes de base de données, exécution de code). En mode réflexion, le modèle génère des étapes intermédiaires plus explicites, qui peuvent être analysées ou utilisées pour garantir des appels d'outils sûrs et corrects dans les systèmes multi-agents.
Ce modèle (une conception à deux modes) était présent dans les versions expérimentales précédentes, et DeepSeek l'a intégré plus profondément dans la version 3.2 et Speciale. Actuellement, Speciale prend exclusivement en charge le mode de réflexion (d'où la restriction d'accès à son API). La possibilité d'alterner entre rapidité et réflexion est précieuse pour l'ingénierie, car elle permet aux développeurs de trouver le juste compromis entre latence et fiabilité lors de la création d'agents devant interagir avec des systèmes réels.
Pourquoi c'est remarquable : De nombreux systèmes modernes proposent soit un modèle de raisonnement structuré (pour expliquer le raisonnement), soit une couche d'orchestration distincte pour les agents et les outils. L'approche de DeepSeek suggère un couplage plus étroit : le modèle peut « réfléchir » puis appeler les outils de manière déterministe, en utilisant leurs réponses pour orienter la réflexion ultérieure. Cette approche est plus fluide pour les développeurs qui créent des agents autonomes.
Où obtenir DeepSeek v3.2
En bref, vous pouvez obtenir DeepSeek v3.2 de plusieurs manières selon vos besoins :
- Site web/application officiel(le) (utilisation en ligne) — Essayez l'interface web ou l'application mobile DeepSeek pour utiliser la version 3.2 de manière interactive.
- Accès API DeepSeek propose la version 3.2 via son API (la documentation inclut les noms des modèles, l'URL de base et les tarifs). Inscrivez-vous pour obtenir une clé API et appelez le point de terminaison v3.2.
- Poids téléchargeables/ouverts (Hugging Face) — Le modèle (variantes V3.2 / V3.2-Exp) est publié sur Hugging Face et peut être téléchargé (poids libre).
huggingface-hubortransformerspour extraire les fichiers. - API Comet — Une plateforme d'agrégation d'API d'IA propose des points de terminaison hébergés V3.2-Exp. Son prix est inférieur au prix officiel.
Quelques remarques pratiques :
- Si vous voulez poids à exécuter localement, rendez-vous sur la page du modèle Hugging Face (acceptez les conditions de licence/d'accès qui s'y trouvent) et utilisez
huggingface-cliortransformersPour télécharger, le dépôt GitHub indique généralement les commandes exactes. - Si vous voulez Utilisation en production via APISuivez les instructions de la plateforme de votre choix, comme la documentation de l'API Cometapi, pour connaître les noms des points de terminaison et les informations correctes.
base_urlpour la variante V3.2.
DeepSeek-V3.2-Spécial :
- Ouvert uniquement à des fins de recherche, prend en charge le dialogue « Mode de réflexion », mais ne prend pas en charge les appels d'outils.
- La production maximale peut atteindre 128 000 jetons (chaîne de pensée ultra-longue).
- Essai gratuit jusqu'au 15 décembre 2025.
Réflexions finales
DeepSeek-V3.2 représente une avancée significative dans la maturation des modèles axés sur le raisonnement. Son association d'un raisonnement multi-étapes amélioré, d'éditions spécialisées hautes performances (Speciale) et d'une intégration « réflexion + outil » optimisée pour la production est remarquable pour quiconque développe des agents avancés, des assistants de programmation ou des flux de travail de recherche nécessitant l'entrelacement de la réflexion et d'actions externes.
Les développeurs peuvent accéder à DeepSeek V3.2 via CometAPI. Pour commencer, explorez les fonctionnalités de modélisation de CometAPI dans le cour de récréation et consultez le Guide de l'API Pour des instructions détaillées, veuillez vous connecter à CometAPI et obtenir la clé API avant d'y accéder. AvecetAPI proposer un prix bien inférieur au prix officiel pour vous aider à vous intégrer.
Prêt à partir ?→ Inscrivez-vous à CometAPI dès aujourd'hui !
Si vous souhaitez connaître plus de conseils, de guides et d'actualités sur l'IA, suivez-nous sur VK, X et Discord!