

DeepSeek a publié DeepSeek V3.2 comme successeur de sa gamme V3.x, ainsi qu’une variante complémentaire DeepSeek-V3.2-Speciale que l’entreprise présente comme une édition haute performance, axée en priorité sur le raisonnement pour l’usage agent/outils. V3.2 s’appuie sur des travaux expérimentaux (V3.2-Exp) et introduit une capacité de raisonnement accrue, une édition Speciale optimisée pour des performances « niveau or » en mathématiques/programmation compétitive, ainsi que ce que DeepSeek décrit comme un système bimode inédit de type « thinking + tool » qui intègre étroitement le raisonnement interne étape par étape avec l’invocation d’outils externes et les workflows d’agents.
Qu’est-ce que DeepSeek V3.2 — et en quoi V3.2-Speciale diffère-t-il ?
DeepSeek-V3.2 est le successeur officiel de la branche expérimentale V3.2-Exp de DeepSeek. Il est décrit par DeepSeek comme une famille de modèles « reasoning-first » conçue pour les agents, c’est-à-dire des modèles optimisés non seulement pour la qualité conversationnelle naturelle, mais plus spécifiquement pour l’inférence en plusieurs étapes, l’invocation d’outils et un raisonnement fiable de type chaîne de pensée lorsqu’ils opèrent dans des environnements incluant des outils externes (API, exécution de code, connecteurs de données).
Qu’est-ce que DeepSeek-V3.2 (base)
- Positionné comme le successeur de production grand public de la gamme expérimentale V3.2-Exp ; destiné à une large disponibilité via l’application/le web/l’API de DeepSeek.
- Conserve un équilibre entre efficacité de calcul et robustesse du raisonnement pour les tâches agentiques.
Qu’est-ce que DeepSeek-V3.2-Speciale
DeepSeek-V3.2-Speciale est une variante que DeepSeek commercialise comme une « édition spéciale » à capacité supérieure, optimisée pour le raisonnement de niveau concours, les mathématiques avancées et les performances agentiques. Elle est présentée comme une variante à capacité supérieure qui « repousse les limites des capacités de raisonnement ». DeepSeek expose actuellement Speciale comme un modèle accessible uniquement par API avec un routage d’accès temporaire ; les premiers benchmarks suggèrent qu’elle est positionnée pour rivaliser avec des modèles fermés haut de gamme sur les benchmarks de raisonnement et de code.
Quelle lignée et quels choix d’ingénierie ont mené à V3.2 ?
V3.2 hérite d’une lignée d’ingénierie itérative que DeepSeek a rendue publique tout au long de 2025 : V3 → V3.1 (Terminus) → V3.2-Exp (une étape expérimentale) → V3.2 → V3.2-Speciale. La version expérimentale V3.2-Exp a introduit DeepSeek Sparse Attention (DSA) — un mécanisme d’attention creuse fine visant à réduire les coûts mémoire et de calcul pour des longueurs de contexte très importantes tout en préservant la qualité de sortie. Ces recherches sur DSA et le travail de réduction des coûts ont servi de tremplin technique à la famille officielle V3.2.
Quelles sont les nouveautés de la version officielle de DeepSeek 3.2 ?
1) Capacité de raisonnement améliorée — comment le raisonnement est-il renforcé ?
DeepSeek présente V3.2 comme « reasoning-first ». Cela signifie que l’architecture et le fine-tuning se concentrent sur l’exécution fiable d’inférences en plusieurs étapes, le maintien de chaînes de pensée internes et la prise en charge des formes de délibération structurée dont les agents ont besoin pour utiliser correctement des outils externes.
Concrètement, les améliorations incluent :
- Un entraînement et un RLHF (ou des procédures d’alignement similaires) réglés pour encourager une résolution de problèmes explicite, étape par étape, ainsi que des états intermédiaires stables (utiles pour le raisonnement mathématique, la génération de code en plusieurs étapes et les tâches logiques).
- Des choix architecturaux et de fonction de perte qui préservent des fenêtres de contexte plus longues et permettent au modèle de se référer avec fidélité aux étapes de raisonnement antérieures.
- Des modes pratiques (voir « bimode » ci-dessous) qui permettent au même modèle de fonctionner soit dans un mode plus rapide de type « chat », soit dans un mode délibératif « thinking » où il traite intentionnellement des étapes intermédiaires avant d’agir.
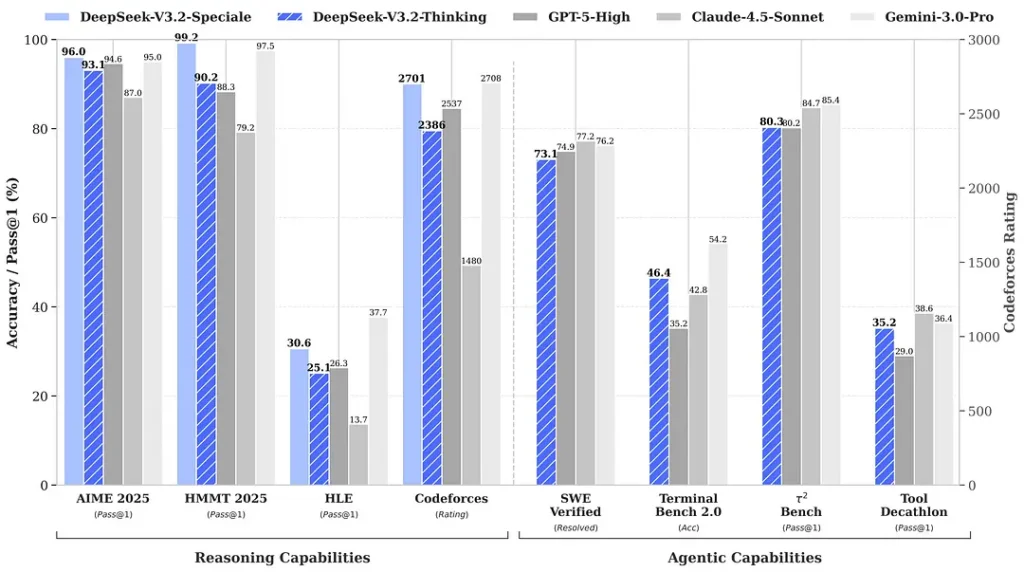
Les benchmarks cités autour de la sortie revendiquent des gains notables sur les suites de mathématiques et de raisonnement ; les premiers benchmarks indépendants de la communauté rapportent également des scores impressionnants sur des ensembles d’évaluation compétitifs:
2) Performances révolutionnaires dans l’édition spéciale — à quel point est-elle meilleure ?
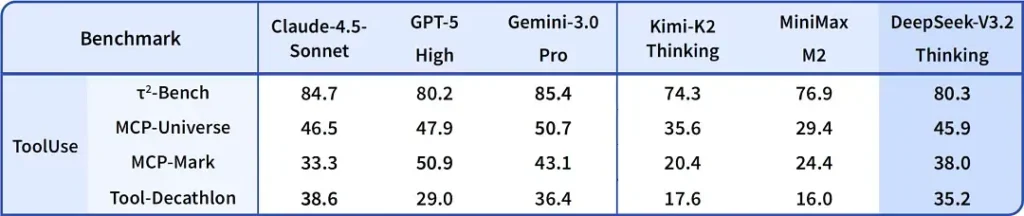
DeepSeek-V3.2-Speciale est présenté comme offrant un gain en précision de raisonnement et en orchestration agentique par rapport au V3.2 standard. Le fournisseur positionne Speciale comme un palier de performance destiné aux charges de travail lourdes en raisonnement et aux tâches agentiques exigeantes ; elle est actuellement accessible uniquement via API et proposée comme un endpoint temporaire de capacité supérieure (DeepSeek a indiqué que la disponibilité de Speciale serait initialement limitée). La version Speciale intègre le modèle mathématique précédent DeepSeek-Math-V2 ; elle peut démontrer des théorèmes mathématiques et vérifier par elle-même des raisonnements logiques ; elle a obtenu des résultats remarquables dans plusieurs compétitions de classe mondiale :
- 🥇 Médaille d’or à l’IMO (International Mathematical Olympiad)
- 🥇 Médaille d’or à la CMO (Chinese Mathematical Olympiad)
- 🥈 Deuxième place à l’ICPC (International Computer Programming Contest) (concours humain)
- 🥉 Dixième place à l’IOI (International Olympiad in Informatics) (concours humain)
| Benchmark | GPT-5 High | Gemini-3.0 Pro | Kimi-K2 Thinking | DeepSeek-V3.2 Thinking | DeepSeek-V3.2 Speciale |
|---|---|---|---|---|---|
| AIME 2025 | 94.6 (13k) | 95.0 (15k) | 94.5 (24k) | 93.1 (16k) | 96.0 (23k) |
| HMMT Feb 2025 | 88.3 (16k) | 97.5 (16k) | 89.4 (31k) | 92.5 (19k) | 99.2 (27k) |
| HMMT Nov 2025 | 89.2 (20k) | 93.3 (15k) | 89.2 (29k) | 90.2 (18k) | 94.4 (25k) |
| IMOAnswerBench | 76.0 (31k) | 83.3 (18k) | 78.6 (37k) | 78.3 (27k) | 84.5 (45k) |
| LiveCodeBench | 84.5 (13k) | 90.7 (13k) | 82.6 (29k) | 83.3 (16k) | 88.7 (27k) |
| CodeForces | 2537 (29k) | 2708 (22k) | — | 2386 (42k) | 2701 (77k) |
| GPQA Diamond | 85.7 (8k) | 91.9 (8k) | 84.5 (12k) | 82.4 (7k) | 85.7 (16k) |
| HLE | 26.3 (15k) | 37.7 (15k) | 23.9 (24k) | 25.1 (21k) | 30.6 (35k) |
3) Première implémentation d’un système bimode « thinking + tool »
L’une des affirmations les plus intéressantes sur le plan pratique dans V3.2 est un workflow bimode qui sépare (et permet de choisir entre) un fonctionnement conversationnel rapide et un mode « thinking » plus lent et délibératif, étroitement intégré à l’usage d’outils.
- Mode « Chat / rapide » : conçu pour un chat orienté utilisateur à faible latence, avec des réponses concises et moins de traces de raisonnement internes — adapté à l’aide occasionnelle, aux courtes questions-réponses et aux applications sensibles à la vitesse.
- Mode « Thinking / raisonneur » : optimisé pour une chaîne de pensée rigoureuse, une planification étape par étape et l’orchestration d’outils externes (API, requêtes base de données, exécution de code). Lorsqu’il fonctionne en mode thinking, le modèle produit davantage d’étapes intermédiaires explicites, qui peuvent être inspectées ou utilisées pour piloter des appels d’outils sûrs et corrects dans des systèmes agentiques.
Ce schéma (une conception à deux modes) était présent dans des branches expérimentales antérieures, et DeepSeek l’a intégré plus profondément dans V3.2 et Speciale — Speciale prend actuellement exclusivement en charge le mode thinking (d’où son accès restreint via API). La possibilité de basculer entre vitesse et délibération est précieuse sur le plan de l’ingénierie, car elle permet aux développeurs de choisir le bon compromis entre latence et fiabilité lorsqu’ils construisent des agents devant interagir avec des systèmes du monde réel.
Pourquoi c’est notable : de nombreux systèmes modernes proposent soit un modèle fort en chaîne de pensée (pour expliquer le raisonnement), soit une couche distincte d’orchestration agent/outils. La présentation qu’en fait DeepSeek suggère un couplage plus étroit — le modèle peut « penser », puis appeler des outils de manière déterministe, en utilisant les réponses des outils pour informer la réflexion suivante — ce qui est plus fluide pour les développeurs qui construisent des agents autonomes.
Où obtenir DeepSeek v3.2
Réponse courte — vous pouvez obtenir DeepSeek v3.2 de plusieurs façons selon vos besoins :
- Web/app officielle (utilisation en ligne) — essayez l’interface web de DeepSeek ou l’application mobile pour utiliser V3.2 de façon interactive.
- Accès API — DeepSeek expose V3.2 via son API (la documentation inclut les noms de modèles /
base_urlet les tarifs). Inscrivez-vous pour obtenir une clé API et appelez l’endpoint v3.2. - Poids téléchargeables/open-weight (Hugging Face) — le modèle (variantes V3.2 / V3.2-Exp) est publié sur Hugging Face et peut être téléchargé (open-weight). Utilisez
huggingface-huboutransformerspour récupérer les fichiers. - CometAPI — une plateforme d’agrégation d’API d’IA fournit des endpoints hébergés V3.2-Exp. Le prix est inférieur au prix officiel.
Quelques remarques pratiques :
- Si vous voulez des poids pour une exécution locale, rendez-vous sur la page du modèle Hugging Face (acceptez toute licence / condition d’accès le cas échéant) et utilisez
huggingface-clioutransformerspour télécharger ; le dépôt GitHub indique généralement les commandes exactes. - Si vous voulez une utilisation en production via API, suivez la documentation API de la plateforme souhaitée, comme cometapi, pour les noms d’endpoint et la
base_urlcorrecte pour la variante V3.2.
DeepSeek-V3.2-Speciale :* Ouvert uniquement à un usage de recherche, prend en charge le dialogue en « Thinking Mode », mais ne prend pas en charge les appels d’outils.
- La sortie maximale peut atteindre 128K tokens (chaîne de pensée ultra-longue).
- Actuellement gratuit à tester jusqu’au 15 décembre 2025.
Réflexions finales
DeepSeek-V3.2 représente une étape importante dans la maturation des modèles centrés sur le raisonnement. Sa combinaison d’un raisonnement multi-étapes amélioré, d’éditions spécialisées à haute performance (Speciale) et d’une intégration « thinking + tool » industrialisée est remarquable pour tous ceux qui construisent des agents avancés, des assistants de code ou des workflows de recherche devant entremêler délibération et actions externes.
Les développeurs peuvent accéder à DeepSeek V3.2 via CometAPI. Pour commencer, explorez les capacités du modèle de CometAPI dans le Playground et consultez le guide API pour des instructions détaillées. Avant d’y accéder, veuillez vous assurer que vous êtes connecté à CometAPI et que vous avez obtenu la clé API. CometAPI propose un prix bien inférieur au prix officiel pour vous aider à l’intégrer.
Prêt à démarrer ?→ Inscrivez-vous à CometAPI dès aujourd’hui !
Si vous voulez connaître davantage d’astuces, de guides et d’actualités sur l’IA, suivez-nous sur VK, X et Discord !