

Gemini Embedding 2 est le premier modèle d'embedding nativement multimodal de Google qui projette le texte, les images, l'audio, la vidéo et les PDF dans un seul espace vectoriel sémantique de 3,072 dimensions (avec tailles de sortie configurables). Il introduit Matryoshka Representation Learning pour fournir des embeddings imbriqués / tronqués, des performances multilingues améliorées (100+ langues) et des contrôles optimisés pour des embeddings spécifiques aux tâches (par ex. task:search, task:code).
Qu'est-ce que Gemini Embedding 2 ?
Gemini Embedding 2 est un modèle d'embedding unifié de Google qui projette plusieurs modalités d'entrée — texte, images, audio, vidéo et documents — dans un seul espace vectoriel sémantique. Chaque embedding est (par défaut) un vecteur flottant de 3,072 dimensions qui représente la signification sémantique de l’entrée, afin que des éléments sémantiquement similaires (quelle que soit la modalité) soient proches dans l’espace vectoriel. Les capacités principales sont :
- Large couverture des langues et des formats : un modèle unique qui accepte le texte, les images, l’audio, la vidéo et les documents et les place dans un même espace vectoriel sémantique. Gemini Embedding 2 est documenté comme capturant l’intention sémantique dans 100+ langues et acceptant les formats de fichiers courants (PNGs/JPEGs, MP4/MOV, MP3/WAV, PDF), avec des limites concrètes par requête (par ex., jusqu’à quelques images ou des dizaines de secondes d’audio/vidéo par requête — voir « Comment utiliser » ci-dessous).
- Véritable multimodalité : un modèle unique qui accepte le texte, les images, l’audio, la vidéo et les documents et les place dans un même espace vectoriel sémantique, afin que vous puissiez comparer ou retrouver à travers les modalités (par ex., texte → image, audio → texte).
- Grande dimensionalité par défaut avec troncature flexible : le modèle produit des vecteurs de 3072 dimensions par défaut, mais utilise le Matryoshka Representation Learning (MRL) pour concentrer le contenu sémantique le plus important dans les premières dimensions, afin que vous puissiez tronquer à 1536, 768 (ou moins) avec seulement des baisses modestes de qualité de recherche. Cela réduit les compromis entre stockage et calcul.
Pourquoi cela compte. Historiquement, les embeddings étaient principalement réservés au texte ou nécessitaient des encodeurs séparés par modalité avec des couches d’alignement inter-modalité complexes. Gemini Embedding 2 supprime cette barrière en prenant en charge nativement plusieurs formats — ainsi, une requête texte peut retrouver une image ou un court clip par similarité sémantique sans transcription intermédiaire ni mappage manuel. Cela simplifie les pipelines de RAG (Retrieval-Augmented Generation), de recherche sémantique et de recherche multimodale.
Fonctionnalités et capacités clés (nouveautés)
1. Multimodalité native véritable (un seul espace d'embedding)
Un modèle unique qui accepte le texte, les images, l’audio, la vidéo et les documents et les place dans un seul espace vectoriel sémantique. Gemini Embedding 2 projette le texte, les images, l’audio, la vidéo et les documents dans le même espace d’embedding, de sorte que la recherche inter-modale (texte→image, audio→texte) fonctionne directement sans alignement inter-modèles. Cela réduit la complexité des pipelines et simplifie les stacks de RAG (Retrieval-Augmented Generation).
2. Vecteurs par défaut de 3,072 dimensions avec sortie ajustable
Gemini Embedding 2 produit des vecteurs de 3072 dimensions par défaut, mais utilise le Matryoshka Representation Learning (MRL) pour concentrer le contenu sémantique le plus important dans les premières dimensions, afin que vous puissiez tronquer à 1536, 768 (ou moins) avec seulement des baisses modestes de qualité de recherche. Cela réduit les compromis entre stockage et calcul.
3. Matryoshka Representation Learning (MRL)
MRL produit des embeddings « imbriqués » — comme des poupées russes — de sorte que des tranches de plus faible dimension préservent des sémantiques de niveau supérieur. Cela permet aux systèmes de choisir un point de fonctionnement (compromis stockage/précision) sans maintenir plusieurs modèles d’embedding distincts. Les premières analyses de blogs et la documentation décrivent cette technique comme une innovation clé pour la flexibilité.
4. Indices de tâche / objectifs d'embedding personnalisés
L’API accepte des indices de task (par ex., task:search, task:code retrieval, task:semantic-similarity) afin que le modèle puisse optimiser la géométrie de l’embedding pour des relations spécifiques en aval — similaire au conditionnement par tâche utilisé dans des systèmes d’embedding antérieurs, mais étendu aux entrées multimodales.
5. Ampleur des langues et des modalités
Gemini Embedding 2 est documenté comme capturant l’intention sémantique dans 100+ langues et acceptant les formats de fichiers courants (PNGs/JPEGs, MP4/MOV, MP3/WAV, PDF), avec des limites concrètes par requête (par ex., jusqu’à quelques images ou des dizaines de secondes d’audio/vidéo par requête — voir « Comment utiliser » ci-dessous).
Benchmarks de performance
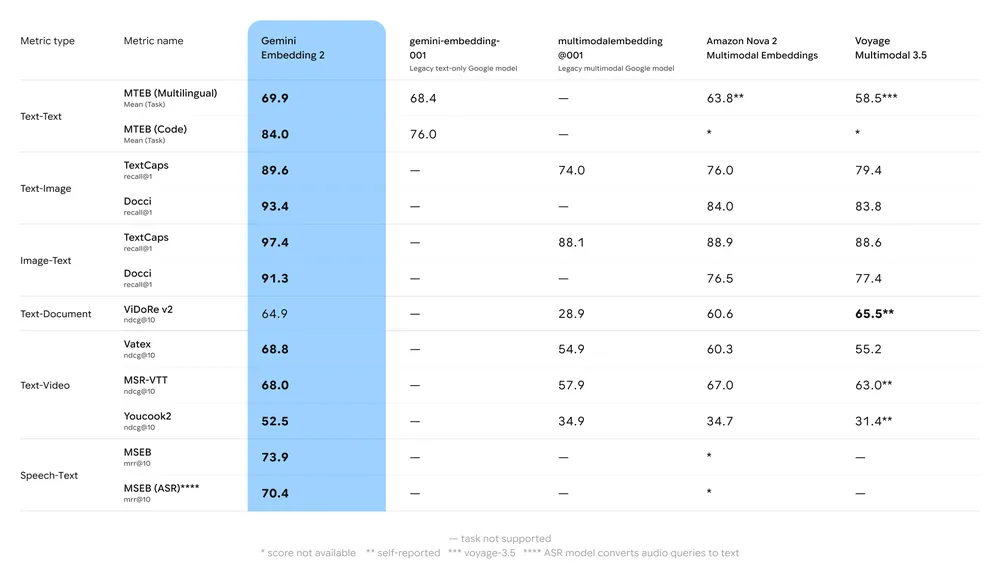
Résumé des principaux benchmarks :
- MTEB (Massive Text Embedding Benchmark) : Forte position rapportée sur les classements MTEB multilingues pour l’anglais et les tâches multilingues ; des analyses montrent une amélioration significative par rapport aux précédents modèles d’embedding de Gemini et à de nombreuses alternatives propriétaires.
- Recherche multimodale : Surpasse ou égalise les meilleurs embeddings mono-modaux lorsqu’il est utilisé pour la similarité inter-modale (par ex., recherche texte→image), grâce à l’entraînement nativement multimodal.
- Latence et débit : Génération d’embeddings hébergée dans le cloud, mais les cas sensibles à la latence peuvent préférer des vecteurs tronqués ou des modèles d’embedding légers alternatifs pour des besoins en périphérie.
Gemini Embedding 2 vs gemini-embedding-001 et text-embedding-3-large
| Attribut | Gemini Embedding 2 (embedding-2) | Gemini Embedding (gemini-embedding-001) | OpenAI text-embedding-3-large |
|---|---|---|---|
| Sortie / disponibilité | 10 Mar, 2026 — aperçu public (Gemini API / Vertex AI). | Ancienne version d’embedding Gemini (variantes uniquement texte) — GA antérieure. | Annoncé en janvier 2024 (GA texte uniquement). |
| Modalités prises en charge | Texte, images, audio, vidéo, documents (PDF) — espace vectoriel unifié. | Texte (principalement). | Texte uniquement (multilingue de haute qualité). |
| Dim. d'embedding par défaut | 3072 (MRL / troncature recommandée : 1536, 768). | 3072 (pour large) — texte uniquement. | 3072 (text-embedding-3-large). |
| MTEB rapporté (exemple) | Fin des années 60 sur MTEB ; affiche 68.17 à 1536 dans le tableau du fournisseur (voir la documentation). | gemini-embedding-001 a rapporté ~68.32 de moyenne dans certains classements. | ~64.6 (moyenne MTEB rapportée par OpenAI pour text-embedding-3-large). |
| Prise en charge audio/vidéo native | Oui (embedding audio/vidéo direct). | Non (texte uniquement). | Non (texte uniquement). |
| Cas d'utilisation typiques | Recherche multimodale, RAG, recherche sémantique sur différents types de fichiers, recherche vocale, recherche vidéo. | Recherche textuelle, RAG multilingue. | Recherche textuelle, recherche sémantique, RAG — solides performances textuelles multilingues. |
Spécifications techniques et limites
Taille d'embedding par défaut et ajustable
- Par défaut : 3,072 dimensions.
- Ajustable : le paramètre
output_dimensionalitypermet de demander des sorties de moindre dimension pour économiser le stockage / CPU. Les cas d’usage avec des bases vectorielles massives réduisent souvent les dimensions à 512–1,024 pour des raisons de coût, en acceptant une certaine baisse de précision.
Modalités prises en charge et limites par requête
- Images : PNG, JPEG — jusqu’à 6 images par requête (limites indiquées par le fournisseur).
- Vidéo : MP4, MOV — le fournisseur indique jusqu’à ~128 secondes par vidéo pour l’embedding en requête unique.
- Audio : MP3, WAV — le fournisseur indique jusqu’à ~80 secondes par entrée audio.
- Documents : PDFs — jusqu’à 6 pages par requête (indication du fournisseur).
- Limite de tokens pour le contenu textuel : le modèle prend en charge de grandes entrées de tokens ; des plafonds pratiques par requête existent (voir la documentation de l’API et les quotas Vertex AI).
Disponibilité et accès
- Aperçu public : Gemini Embedding 2 a été publié en aperçu public et est disponible via l’API Gemini et Vertex AI pour une utilisation expérimentale immédiate
Foire aux questions (FAQ)
Q1 : Quelles modalités Gemini Embedding 2 prend-il en charge ?
R : Texte, images (PNG/JPEG), vidéo (MP4/MOV), audio (MP3/WAV) et documents PDF — tous projetés dans le même espace vectoriel sémantique.
Q2 : Quelle est la taille vectorielle par défaut pour Gemini Embedding 2 ?
R : Par défaut 3,072 dimensions. Vous pouvez demander une dimensionalité de sortie plus petite via l’API.
Q3 : Gemini Embedding 2 est-il disponible maintenant ?
R : Oui — il a été annoncé en aperçu public et est disponible via l’API Gemini et Vertex AI (consultez l’identifiant de modèle gemini-embedding-2-preview et le changelog actuel).
Q4 : Comment se compare-t-il aux embeddings d’autres fournisseurs ?
R : Des tests de fournisseurs indépendants rapportent que Gemini Embedding 2 se classe parmi les meilleurs modèles propriétaires pour le texte multilingue et montre des performances à l’état de l’art pour plusieurs tâches multimodales. Les classements exacts varient selon la tâche et le jeu de données ; testez sur vos propres données.
Q5 : Devrai-je transcrire l’audio pour utiliser Gemini Embedding 2 ?
R : Non — Gemini Embedding 2 peut accepter directement l’audio et produire des embeddings sans transcrire d’abord en texte, permettant une recherche sémantique de bout en bout sur l’audio.
Q6 : Comment réduire les coûts de stockage des vecteurs de 3,072 dimensions ?
R : Les options incluent la demande d’une output_dimensionality plus faible, l’utilisation de float16/quantization/PQ et le stockage de représentations compressées dans votre base vectorielle. Les publications du fournisseur proposent des workflows et des bonnes pratiques.
Et ensuite — devrais-je l’adopter maintenant ?
Gemini Embedding 2 est une étape majeure vers l’unification de la recherche multimodale et simplifie des architectures qui nécessitaient auparavant des récupérateurs séparés pour le texte, la vision et la parole. Les points clés de décision pour l’adoption :
- Adoptez rapidement si votre produit nécessite une recherche inter-modale robuste (texte↔image/vidéo/audio), ou si la maintenance de plusieurs récupérateurs mono-modalité est coûteuse et complexe.
- Pilotez maintenant si vous voulez évaluer la troncature MRL et mesurer le coût vs la qualité (gardez un déploiement hybride : 1536 en primaire, 3072 pour le re-ranking).
- Attendez si votre charge est extrêmement sensible aux coûts et que seule la recherche textuelle est requise — les meilleurs modèles uniquement texte (par ex., OpenAI text-embedding-3-large) restent compétitifs et parfois moins chers selon votre pipeline et votre contrat.
Les développeurs peuvent accéder à Gemini Embedding 2 et à l’API OpenAI text-embedding-3 via CometAPI dès maintenant. Pour commencer, explorez les capacités du modèle dans le Playground et consultez le Guide de l’API pour des instructions détaillées. Avant d’y accéder, veuillez vous assurer que vous êtes connecté à CometAPI et que vous avez obtenu la clé d’API. CometAPI propose un prix bien inférieur au prix officiel pour vous aider à intégrer.
Prêt à commencer ? → Inscrivez-vous à cometapi aujourd’hui !
Si vous souhaitez connaître plus de conseils, de guides et d’actualités sur l’IA, suivez-nous sur VK, X et Discord !