

Dans le monde en constante évolution de l'intelligence artificielle, la publication de chaque nouveau grand modèle de langage (LLM) représente bien plus qu'une simple amélioration numérique : elle témoigne d'un progrès en matière de raisonnement, de capacité de codage et de collaboration homme-machine. Fin septembre 2025, Zhipu AI (Z.ai) dévoilé GLM-4.6, le dernier-né de la famille GLM-4.5. S'appuyant sur l'architecture robuste et les bases de raisonnement solides de GLM-4.5, cette mise à jour affine les capacités du modèle. raisonnement agentique, intelligence de codage et compréhension à long terme, tout en restant ouvert et accessible aux développeurs et aux entreprises.
Qu'est-ce que GLM-4.6 ?
GLM-4.6 est une version majeure de la série GLM (General Language Model), conçue pour concilier raisonnement haute performance et workflows de développement pratiques. Elle cible trois cas d'usage étroitement liés : (1) la génération de code et le raisonnement sur le code avancés ; (2) les tâches à contexte étendu nécessitant la compréhension du modèle sur des entrées très longues ; et (3) les workflows agentiques où le modèle doit planifier, appeler des outils et orchestrer des processus en plusieurs étapes. Le modèle est proposé en variantes destinées aux API cloud et aux plateformes de modèles communautaires, permettant des déploiements hébergés et auto-hébergés.
Concrètement, GLM-4.6 se positionne comme un produit phare, axé sur les développeurs : ses améliorations ne se limitent pas aux résultats bruts des benchmarks, mais intègrent des fonctionnalités qui transforment concrètement la façon dont les développeurs créent des assistants, des copilotes de code et des agents basés sur les documents ou les connaissances. Attendez-vous à une version mettant l'accent sur l'optimisation des instructions pour l'utilisation des outils, des améliorations fines de la qualité du code et du débogage, et des choix d'infrastructure permettant des contextes très longs sans dégradation linéaire des performances.
Quel est l’objectif de GLM-4.6 ?
- Réduisez les frictions liées au travail avec de longues bases de code et des documents volumineux en prenant en charge des fenêtres de contexte efficaces plus longues.
- Améliorez la fiabilité de la génération et du débogage de code, en produisant des sorties plus idiomatiques et testables.
- Augmentez la robustesse des comportements agentiques (planification, utilisation d’outils et exécution de tâches en plusieurs étapes) grâce à des instructions ciblées et à un réglage de type renforcement.
De GLM-4.5 à GLM-4.6, qu’est-ce qui a changé dans la pratique ?
- Échelle de contexte: 128K saut à 200 XNUMX jetons Il s'agit du changement d'expérience utilisateur et d'architecture le plus important pour les utilisateurs : les documents longs, les bases de code complètes ou les transcriptions étendues d'agents peuvent désormais être traités comme une seule fenêtre contextuelle. Cela réduit le recours à des découpages ad hoc ou à des boucles de récupération coûteuses pour de nombreux workflows.
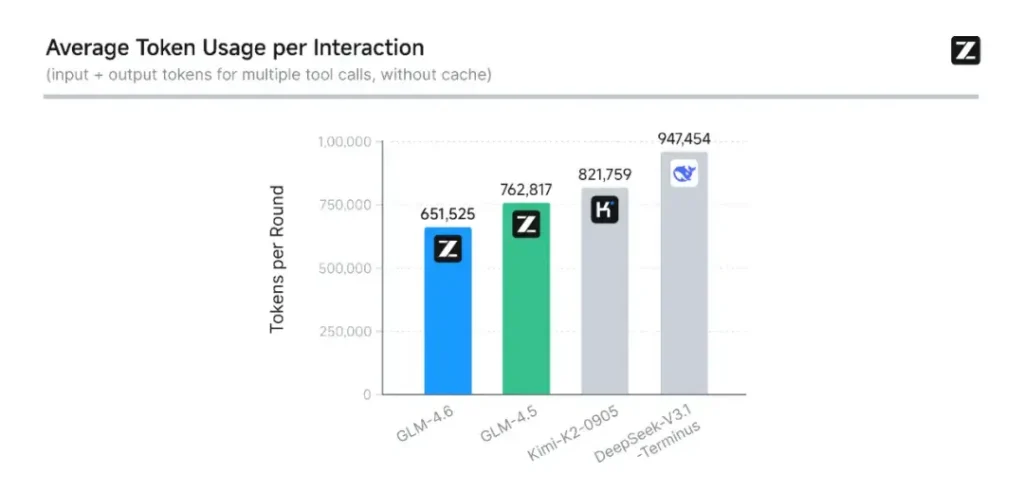
- Codage et évaluation en conditions réelles : Z.ai a étendu CC-Bench (leur benchmark de codage et d'achèvement) avec des trajectoires de tâches réelles plus difficiles et rapporte que GLM-4.6 termine les tâches avec ~15 % de jetons en moins que GLM-4.5, tout en améliorant les taux de réussite dans les tâches d'ingénierie multi-tours complexes. Cela témoigne d'une meilleure efficacité des jetons et d'améliorations des capacités brutes dans les scénarios de codage appliqués. Z.ai
- Intégration d'agents et d'outils : GLM-4.6 inclut de meilleurs modèles de support pour l'appel d'outils et les agents de recherche, ce qui est important pour les produits qui s'appuient sur le modèle pour orchestrer la recherche Web, l'exécution de code ou d'autres microservices.
Quelles sont les principales fonctionnalités de GLM-4.6 ?
1. Fenêtre contextuelle étendue à 200 000 jetons
L’une des fonctionnalités les plus marquantes de GLM-4.6 est son fenêtre de contexte massivement étendue. Passant de 128 K dans la génération précédente à 200 XNUMX jetonsGLM-4.6 peut traiter des livres entiers, des ensembles de données multi-documents complexes ou des heures de dialogue en une seule session. Cette extension améliore non seulement la compréhension, mais permet également raisonnement cohérent sur de longues entrées — un progrès majeur pour la synthèse de documents, l’analyse juridique et les flux de travail d’ingénierie logicielle.
2. Amélioration de l'intelligence de codage
Interne de Zhipu AI CC-Bench benchmark, une suite de tâches de programmation du monde réel, montre que GLM-4.6 atteint améliorations notables de la précision et de l'efficacité du codage. Le modèle peut produire un code syntaxiquement correct et logiquement solide tout en utilisant environ 15 % de jetons en moins que GLM-4.5 pour des tâches équivalentes. Cette efficacité des jetons permet des finalisations plus rapides et moins coûteuses, sans sacrifier la qualité, un facteur essentiel pour le déploiement en entreprise.
3. Raisonnement avancé et intégration d'outils
Au-delà de la génération de texte brut, GLM-4.6 brille dans raisonnement augmenté par des outilsIl a été formé et aligné pour une planification en plusieurs étapes et pour orchestrer des systèmes externes, des bases de données aux outils de recherche en passant par les environnements d'exécution. En pratique, cela signifie que GLM-4.6 peut servir de « cerveau » à un projet. agent IA autonome, décider quand appeler des API externes, comment interpréter les résultats et comment maintenir la continuité des tâches entre les sessions.
4. Alignement amélioré du langage naturel
Grâce à un apprentissage par renforcement continu et à l'optimisation des préférences, GLM-4.6 offre un flux de conversation plus fluide, une meilleure correspondance de style et un alignement de sécurité plus fortLe modèle adapte son ton et sa structure au contexte — qu'il s'agisse de documentation formelle, de tutorat pédagogique ou d'écriture créative — améliorant ainsi la confiance et la lisibilité des utilisateurs.
Quelle architecture alimente GLM-4.6 ?
GLM-4.6 est-il un modèle mixte d’experts ?
Continuité de la méthode d'inférence : L'équipe GLM indique que GLM-4.5 et GLM-4.6 partagent le même pipeline d'inférence fondamental, ce qui permet de mettre à niveau les configurations de déploiement existantes avec un minimum de friction. Cela réduit les risques opérationnels pour les équipes utilisant déjà GLM-4.x : les paramètres de mise à l'échelle et les choix de conception de modèles privilégient la spécialisation pour le raisonnement agentique, le codage et l'inférence efficace. Le rapport GLM-4.5 fournit la description publique la plus claire de la stratégie MoE et du programme d'entraînement de la famille (pré-entraînement en plusieurs étapes, itération du modèle expert, apprentissage par renforcement pour l'alignement) ; GLM-4.6 applique ces enseignements tout en ajustant la longueur du contexte et les capacités spécifiques aux tâches.
Notes d'architecture pratiques pour les ingénieurs
- Empreinte des paramètres par rapport au calcul activé : Les totaux de paramètres importants (des centaines de milliards) ne se traduisent pas directement par un coût d'activation équivalent sur chaque demande : MoE signifie que seul un sous-ensemble d'experts s'active par séquence de jetons, offrant un compromis coût/débit plus favorable pour de nombreuses charges de travail.
- Précision et formats des jetons : Les poids publics sont distribués aux formats BF16 et F32, et les quantifications communautaires (GGUF, 4-/8-/bits) apparaissent rapidement ; elles permettent aux équipes d'exécuter GLM-4.6 sur des profils matériels variés.
- Compatibilité de la pile d'inférence : Z.ai documente vLLM et d'autres environnements d'exécution LLM modernes en tant que backends d'inférence compatibles, ce qui rend GLM-4.6 réalisable pour les déploiements cloud et sur site.
Performances de référence : quelles sont les performances de GLM-4.6 ?
Quels repères ont été signalés ?
Z.ai a évalué GLM-4.6 sur une suite de huit repères publics couvrant les tâches d'agent, le raisonnement et le codage. Ils ont également étendu CC-Bench (un benchmark de codage en tâches réelles, évalué par des humains et exécuté dans des environnements Docker isolés) afin de mieux simuler les tâches d'ingénierie de production (développement front-end, tests, résolution de problèmes algorithmiques). Sur ces tâches, GLM-4.6 a montré des améliorations constantes par rapport à GLM-4.5.
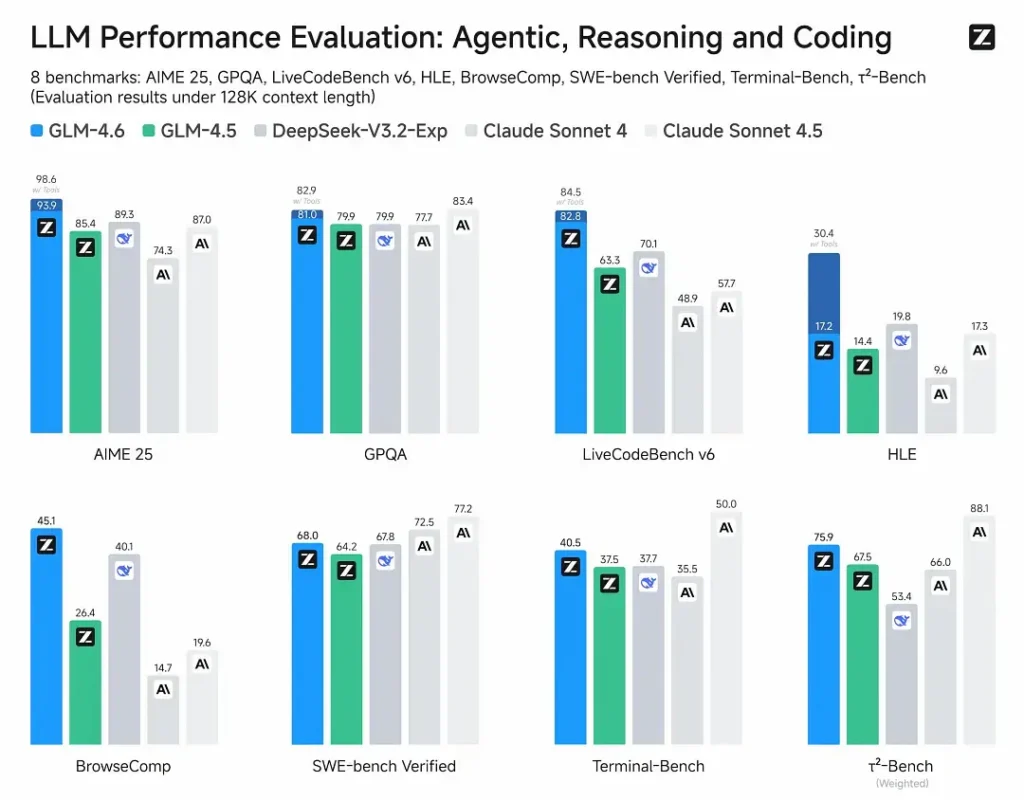
Performances de codage
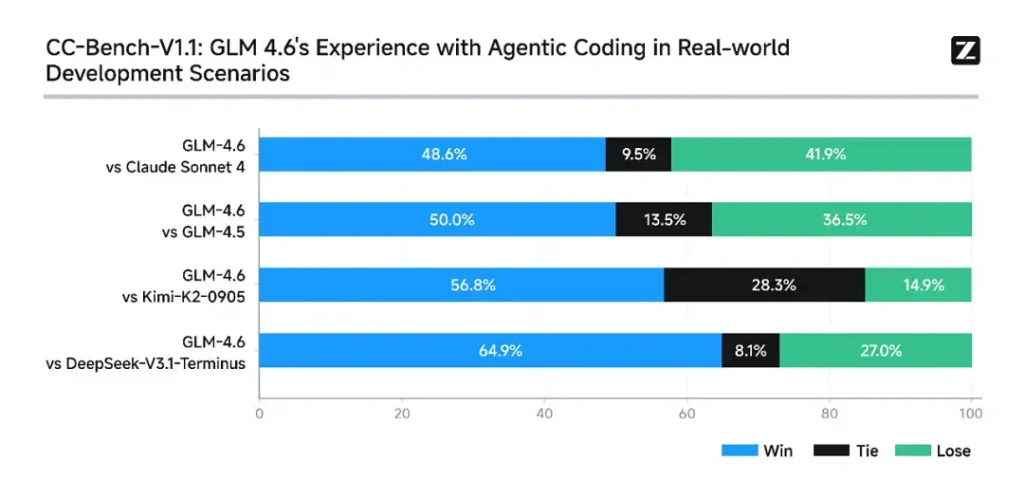
- Les vraies tâches gagnent : Dans les évaluations humaines CC-Bench, GLM-4.6 a atteint quasi-parité avec Claude Sonnet 4 d'Anthropic dans des tâches en tête-à-tête à plusieurs tours — Z.ai rapporte un 48.6 taux de victoire de% Dans leurs évaluations isolées de Docker et évaluées par des humains (interprétation : presque 50/50 avec Claude Sonnet 4 dans leur ensemble organisé). Parallèlement, GLM-4.6 a surpassé plusieurs modèles ouverts nationaux (par exemple, les variantes de DeepSeek) dans leurs tâches.
- Efficacité du jeton : Z.ai rapporte ~15 % de jetons en moins utilisé pour terminer les tâches par rapport à GLM-4.5 dans les trajectoires CC-Bench - cela est important à la fois pour la latence et le coût.
Raisonnement et mathématiques
GLM-4.6 revendique une capacité de raisonnement améliorée et une meilleure performance d'utilisation des outils par rapport à GLM-4.5. Alors que GLM-4.5 mettait l'accent sur les modes hybrides de « réflexion » et de réponse directe, GLM-4.6 renforce la robustesse du raisonnement multi-étapes, notamment lorsqu'il est intégré à des outils de recherche ou d'exécution.
Les messages publics de Z.ai positionnent GLM-4.6 comme compétitif avec les principaux modèles internationaux et nationaux Sur les benchmarks choisis, GLM-4.6 est compétitif face à Claude Sonnet 4 et surpasse certaines alternatives locales comme les variantes de DeepSeek pour les tâches de code et d'agent. Cependant, dans certains sous-benchmarks spécifiques au codage**, GLM-4.6 reste à la traîne par rapport à Claude Sonnet 4.5 (une version plus récente d'Anthropic), ce qui place le paysage de la concurrence acharnée plutôt que de la domination absolue.
Comment accéder à GLM-4.6
- 1. Via la plateforme Z.ai : Les développeurs peuvent accéder directement à GLM-4.6 via API de Z.ai or **interface de discussion (chat.z.ai)**Ces services hébergés permettent une expérimentation et une intégration rapides sans déploiement local. L'API prend en charge la saisie semi-automatique standard et les modes d'appel d'outils structurés, essentiels aux workflows agentiques.
- 2. Ouvrir les poids sur Hugging Face et ModelScope : Pour ceux qui préfèrent le contrôle local, Zhipu AI a publié des fichiers de modèle GLM-4.6 sur Étreindre le visage et ModèlePortée, y compris les versions Safetensors en BF16 et F32 précision. Les développeurs communautaires ont déjà produit des versions GGUF quantifiées, permettant l'inférence sur les GPU grand public.
- 3. Cadres d’intégration : GLM-4.6 s'intègre parfaitement aux principaux moteurs d'inférence tels que vLLM, SG Langet Déploiement LMD, ce qui le rend adaptable aux plateaux de service modernes. Cette polyvalence permet aux entreprises de choisir entre nuage, bordet déploiement sur site en fonction des exigences de conformité ou de latence.
CometAPI est une plateforme d'API unifiée qui regroupe plus de 500 modèles d'IA provenant de fournisseurs leaders, tels que la série GPT d'OpenAI, Gemini de Google, Claude d'Anthropic, Midjourney, Suno, etc., au sein d'une interface unique et conviviale pour les développeurs. En offrant une authentification, un formatage des requêtes et une gestion des réponses cohérents, CometAPI simplifie considérablement l'intégration des fonctionnalités d'IA dans vos applications. Que vous développiez des chatbots, des générateurs d'images, des compositeurs de musique ou des pipelines d'analyse pilotés par les données, CometAPI vous permet d'itérer plus rapidement, de maîtriser les coûts et de rester indépendant des fournisseurs, tout en exploitant les dernières avancées de l'écosystème de l'IA.
La dernière intégration GLM-4.6 apparaîtra bientôt sur CometAPI, alors restez à l'écoute ! Pendant que nous finalisons le téléchargement du modèle GLM 4.6, explorez nos autres modèles sur la page Modèles ou essayez-les dans l'IA Playground.
Les développeurs peuvent accéder API GLM-4.5 via CometAPI, la dernière version du modèle est constamment mis à jour avec le site officiel. Pour commencer, explorez les capacités du modèle dans la section cour de récréation et consultez le Guide de l'API Pour des instructions détaillées, veuillez vous connecter à CometAPI et obtenir la clé API avant d'y accéder. API Comet proposer un prix bien inférieur au prix officiel pour vous aider à vous intégrer.
Prêt à partir ?→ Inscrivez-vous à CometAPI dès aujourd'hui !
Conclusion — Pourquoi GLM-4.6 est important aujourd'hui
GLM-4.6 constitue une étape importante dans la gamme GLM, car il allie des améliorations pratiques pour les développeurs (fenêtres contextuelles plus longues, optimisations ciblées du codage et des agents, et gains tangibles en termes de benchmarks) à l'ouverture et à la flexibilité de l'écosystème recherchées par de nombreuses organisations. Pour les équipes développant des assistants de code, des agents de documents longs ou des automatisations assistées par outils, GLM 4.6 mérite d'être évalué comme un candidat de choix.