
.webp&w=3840&q=75)
GLM-5.1 représente un tournant majeur dans le paysage de l’IA. À mesure que les entreprises chinoises d’IA accélèrent la commercialisation tout en mettant en open source des capacités de pointe, ce modèle réduit l’écart avec les leaders propriétaires comme GPT-5.4 d’OpenAI, Claude Opus 4.6 d’Anthropic et Gemini 3.1 Pro de Google — en particulier dans l’ingénierie logicielle réelle. Entraîné sur la même architecture MoE à 744B paramètres que GLM-5 mais fortement optimisé pour des workflows agentiques, il excelle là où la plupart des LLM faiblissent : des tâches longues, ambiguës et itératives qui nécessitent planification, expérimentation, débogage et auto-correction sur des milliers d’appels d’outils.
À présent, CometAPI intègre GLM-5.1 et GLM-5, et les développeurs peuvent également consulter d’autres modèles occidentaux de premier plan et y accéder à un prix d’API très bas (ce qui est aussi un avantage de CometAPI par rapport à d’autres concurrents).
Qu’est-ce que GLM-5.1 ?
GLM-5.1 est le tout dernier modèle linguistique phare de Z.ai et la nouvelle avancée de l’entreprise vers un travail logiciel de style agent sur long horizon. Selon Z.ai, il est conçu pour des tâches qui nécessitent une exécution continue plutôt que des réponses « one-shot », et il est positionné comme un modèle capable de planifier, exécuter, affiner et livrer au cours d’une seule exécution prolongée. Les notes de publication de Z.ai indiquent que GLM-5.1 repose sur un affinage supervisé multi-tours, l’apprentissage par renforcement et un cadre d’évaluation de la qualité des processus, et qu’il améliore la stabilité, la cohérence et l’usage des outils sur des tâches étendues.
Ce positionnement est important car GLM-5.1 n’est pas vendu comme « un autre modèle de chat ». Il vise des workflows d’ingénierie où les modèles doivent garder un objectif en tête, gérer des étapes intermédiaires et se remettre d’erreurs sans perdre le fil ; il est présenté comme un modèle de planification autonome, d’exécution soutenue, de correction de bogues et d’itération de stratégie, ce qui est très différent d’un assistant occasionnel ou d’un copilote de code à contexte court.
Un détail pratique utile : GLM-5.1 est uniquement texte, il est pris en charge dans le GLM Coding Plan et peut être utilisé dans des agents de codage populaires tels que Claude Code et OpenClaw, ce qui le rend particulièrement pertinent pour les équipes qui souhaitent qu’un modèle s’intègre dans un workflow développeur existant plutôt que le remplacer.
Spécifications techniques essentielles (héritées et raffinées à partir de GLM-5) :
- Architecture : Mixture-of-Experts (MoE) avec 744B paramètres au total et environ 40B paramètres actifs par inférence.
- Fenêtre de contexte : 203K–204.8K tokens (avec prise en charge jusqu’à 131K tokens de sortie).
- Améliorations clés : DeepSeek Sparse Attention (DSA) pour une gestion efficace des longs contextes et des coûts de déploiement réduits ; infrastructure avancée d’apprentissage par renforcement asynchrone (via le framework « slime » de Z.ai) pour un post-entraînement plus efficace.
- Disponibilité : Poids ouverts (licence MIT sur Hugging Face via zai-org/GLM-5.1), accès API via la plateforme Z.ai et des agrégateurs comme CometAPI, et intégration dans les outils du GLM Coding Plan (compatibles Claude Code / OpenClaw).
Contrairement aux modèles GLM plus anciens axés sur l’intelligence générale ou le « vibe coding » court, GLM-5.1 cible des agents autonomes de niveau production. Il peut planifier, exécuter, benchmarker, déboguer et itérer de manière indépendante sur des projets d’ingénierie complexes pendant des heures sans intervention humaine — des capacités qui le positionnent comme un concurrent direct des agents de codage spécialisés d’Anthropic et d’OpenAI.
La sortie a coïncidé avec une augmentation d’environ ~10 % du prix de l’API (tokens d’entrée ~$0.54/M, tokens de sortie ~$4.40/M), tout en restant nettement moins cher que des équivalents comme Opus 4.6 d’Anthropic (250–470 % plus coûteux).
Performances de GLM-5.1 sur les benchmarks
Z.ai positionne GLM-5.1 comme le modèle open source le plus puissant au monde et un top 3 global en codage agentique. Les performances proviennent d’évaluations officielles sur SWE-Bench Pro, NL2Repo, Terminal-Bench 2.0 et des scénarios personnalisés à long horizon.
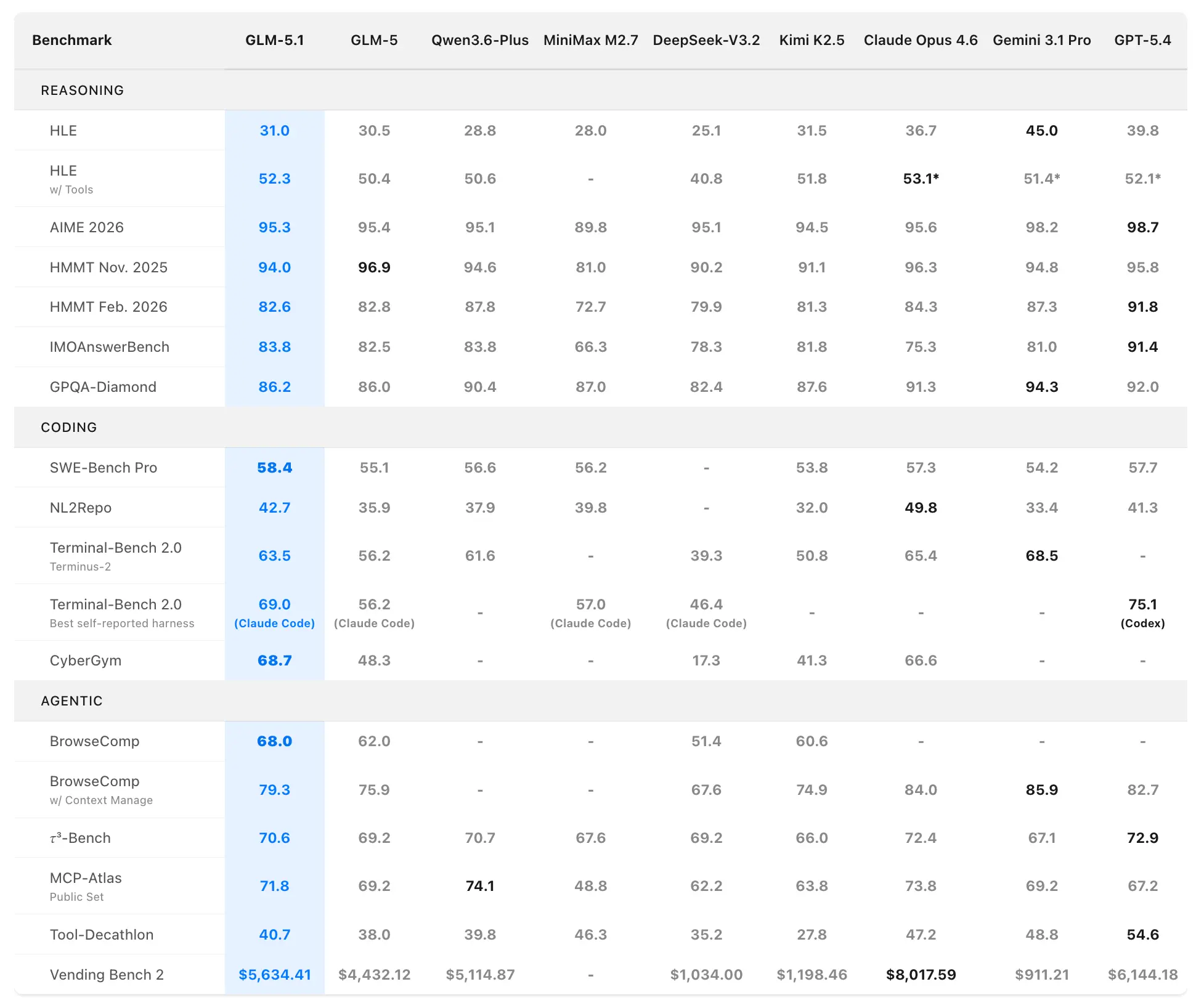
Benchmarks de codage et agentiques
SWE-Bench Pro (tâches d’ingénierie logicielle réalistes nécessitant navigation dans les dépôts, édition de code et vérification fonctionnelle) :
- GLM-5.1 : 58.4 (nouvel état de l’art)
- GLM-5 : 55.1
- GPT-5.4 : 57.7
- Claude Opus 4.6 : 57.3
- Gemini 3.1 Pro : 54.2
GLM-5.1 est le premier modèle domestique (chinois) et open source à revendiquer la première place sur ce benchmark rigoureux, qui reflète étroitement les workflows des développeurs professionnels.
NL2Repo (passage du langage naturel à la génération de dépôt complet) :
- GLM-5.1 : 42.7 (large avance sur les 35.9 de GLM-5)
- Les modèles concurrents se situent entre 32.0–49.8 (les leaders spécifiques varient selon le harnais).
Terminal-Bench 2.0 (tâches réelles sur terminal et systèmes) :
- Harnais Terminus-2 : GLM-5.1 63.5 (contre GLM-5 56.2)
- Meilleur score auto-déclaré (Claude Code) : jusqu’à 69.0.
Dans une évaluation distincte de harnais de codage (style Claude Code), GLM-5.1 a obtenu 45.3 — atteignant 94.6 % des 47.9 de Claude Opus 4.6 et une amélioration de 28 % par rapport aux 35.4 de GLM-5.
Classement composite : n°1 open source, n°1 modèle chinois, n°3 mondial sur SWE-Bench Pro + NL2Repo + Terminal-Bench.
Performances sur tâches à long horizon : le véritable différenciateur
Les benchmarks standards mesurent des performances « one-shot » ou sur sessions courtes. GLM-5.1 excelle dans les exécutions autonomes prolongées :
- VectorDBBench Optimization (600+ itérations, 6 000+ appels d’outils) : À partir d’un squelette Rust, GLM-5.1 a repensé itérativement l’indexation, la compression, le routage et l’élagage, atteignant 21.5k QPS (6× le meilleur précédent sur 50 tours de 3,547 QPS par Claude Opus 4.6) tout en maintenant un rappel ≥95 % sur SIFT-1M. Il a montré des progrès « en escalier » avec des percées structurelles toutes les 100–200 itérations.
- KernelBench Level 3 (optimisation complète de modèle ML, 1 000+ tours) : Accélération moyenne géométrique de 3.6× sur 50 problèmes complexes (surperformant le « max-autotune » de torch.compile à 1.49×). GLM-5.1 a continué à s’améliorer bien après que GLM-5 a plafonné ; seul Claude Opus 4.6 l’a dépassé à 4.2×.
- Linux Desktop Web App Build (8+ heures, ouvert) : À partir d’un simple prompt en langage naturel et sans code de départ, GLM-5.1 a construit de manière autonome un environnement de bureau style Linux — avec barre des tâches, fenêtres, interactions et finitions — là où les modèles précédents ne produisaient qu’un squelette basique.
Ces résultats démontrent la capacité de GLM-5.1 à maintenir la cohérence, s’autoévaluer, réviser des stratégies et sortir des optima locaux sur des horizons extrêmement longs — des capacités que Z.ai a explicitement conçues pour des systèmes agentiques réels.
En quoi GLM-5.1 diffère-t-il de GLM-5 ?
GLM-5 et GLM-5.1 sont étroitement liés, mais ils ne sont pas positionnés de la même manière. GLM-5 est le modèle de fondation antérieur de Z.AI pour l’Agentic Engineering. Il est conçu pour l’ingénierie de systèmes complexes et des tâches d’agent à long terme, avec des poids ouverts SOTA en codage et des capacités d’agent, et des performances en codage qui se rapprochent de Claude Opus 4.5 dans des scénarios de programmation réels. Il obtient 77.8 sur SWE-bench Verified et 56.2 sur Terminal Bench 2.0.
GLM-5.1, en revanche, est présenté comme l’étape suivante vers des tâches à long horizon et une exécution soutenue plus fiable ; il améliore la stabilité, la cohérence et l’usage des outils sur des tâches prolongées, et il est mieux aligné sur l’ensemble avec Claude Opus 4.6. En d’autres termes, GLM-5 est le modèle de fondation antérieur centré sur l’ingénierie, tandis que GLM-5.1 est le fleuron davantage orienté endurance des tâches.
Il existe également des différences architecturales et d’entraînement dans la génération GLM-5 qui aident à expliquer le saut. GLM-5 est passé de 355B paramètres (32B activés) à 744B paramètres (40B activés), a augmenté les données de pré-entraînement de 23T à 28.5T, ajouté un cadre d’apprentissage par renforcement asynchrone, et intégré DeepSeek Sparse Attention pour préserver la qualité sur textes longs tout en améliorant l’efficacité. Ces détails sont liés à GLM-5, mais ils constituent la base sur laquelle GLM-5.1 semble s’appuyer.
GLM-5.1 face aux autres modèles de pointe
GLM-5.1 se distingue comme le meilleur prétendant open source, tout en offrant un ratio prix/performance convaincant.
Tableau comparatif : principaux benchmarks de codage et agentiques (avril 2026)
| Modèle | SWE-Bench Pro | NL2Repo | Terminal-Bench 2.0 (Terminus-2) | Score de harnais de codage | Tâches longues soutenues ? | Open source ? | Prix API approximatif (Entrée/Sortie par M tokens) |
|---|---|---|---|---|---|---|---|
| GLM-5.1 | 58.4 (SOTA) | 42.7 | 63.5 | 45.3 (94.6 % d’Opus) | Oui (600+ itérations, 8 h) | Oui | $0.54 / $4.40 |
| GLM-5 | 55.1 | 35.9 | 56.2 | 35.4 | Limité | Oui | Plus bas (avant hausse) |
| GPT-5.4 | 57.7 | — | — | — | Fort | Non | Plus élevé |
| Claude Opus 4.6 | 57.3 | — | — | 47.9 | Le plus fort | Non | ~250–470 % plus cher |
| Gemini 3.1 Pro | 54.2 | — | — | — | Bon | Non | Plus élevé |
Verdict : GLM-5.1 l’emporte sur l’accessibilité open source, le coût et des métriques spécifiques de codage à long horizon. Il rivalise avec les leaders propriétaires dans des scénarios agentiques tout en démocratisant des capacités de pointe.
Scénarios d’application de GLM-5.1
1) Ingénierie logicielle autonome
GLM-5.1 est le plus convaincant lorsque la tâche ressemble à un vrai sprint d’ingénierie : lire la base de code, planifier le changement, l’implémenter, le tester, corriger les régressions et continuer à itérer jusqu’à ce que le résultat soit stable. Les notes de Z.ai soulignent explicitement la planification autonome, l’exécution soutenue, la correction de bogues et l’itération de stratégie, ce qui donne l’impression que ce modèle est taillé pour les agents de codage et les pipelines de livraison logicielle.
2) Workflows d’agent de longue durée
Si votre cas d’usage implique de nombreux appels d’outils, des workflows multi-étapes longs ou des auto-corrections répétées, la conception de GLM-5.1 correspond très bien. La documentation met en avant l’invocation d’outils, les sorties structurées, l’intégration MCP et la prise en charge du streaming d’outils, autant d’atouts lorsque le modèle n’apporte pas seulement des réponses, mais fonctionne au sein d’un système plus large.
3) Travail de connaissance en entreprise et reporting
GLM-5.1 est également positionné pour des tâches de productivité bureautique telles que des workflows PowerPoint, Word, PDF et Excel. Z.ai indique qu’il améliore l’organisation de contenus complexes, la conception de mise en page, les sorties structurées et le soin visuel, ce qui en fait un choix plausible pour la génération de rapports, supports pédagogiques, synthèses de recherche et autres travaux documentaires.
4) Prototypage front-end et artefacts
Z.ai affirme que GLM-5.1 convient bien à la génération de sites web, de pages interactives et au prototypage front-end, avec une structure moins template et une meilleure qualité d’achèvement des tâches. Cela suggère une bonne adéquation pour les équipes produit qui ont besoin d’un pont rapide du brief au prototype, surtout lorsque le prototype doit être utilisable plutôt que simplement esthétique.
5) Conversation complexe et suivi des instructions
Bien que l’histoire principale soit le codage, GLM-5.1 est également décrit comme plus performant en Q&R ouvertes, instructions complexes et interactions multi-tours. Cela le rend utile pour des workflows d’assistant où le modèle doit garder la trace des contraintes, réviser les sorties et préserver le contexte sur des conversations plus longues.
Conclusion : pourquoi GLM-5.1 compte en 2026
GLM-5.1 n’est pas une simple version incrémentale — il annonce l’arrivée d’une IA agentique open source véritablement capable. En excellant sur les benchmarks d’ingénierie les plus difficiles du monde réel tout en restant abordable et ouvert, Z.ai fixe une nouvelle barre pour l’industrie tout entière. Que vous soyez développeur solo, équipe d’entreprise ou chercheur, GLM-5.1 offre une autonomie inégalée pour des tâches de codage à long horizon à une fraction des coûts propriétaires.
Prêt à l’essayer ? Consultez le modèle GLM-5.1 sur CometAPI, le dépôt Hugging Face, ou le GLM Coding Plan pour un accès immédiat.