

GPT-5.2 est la version ponctuelle de décembre 2025 d’OpenAI dans la famille GPT-5 : une famille de modèles multimodaux phares (texte + vision + outils) optimisée pour le travail de connaissance professionnel, le raisonnement en contexte long, l’utilisation agentique d’outils et l’ingénierie logicielle. OpenAI présente GPT-5.2 comme le modèle le plus performant de la série GPT-5 à ce jour et indique qu’il a été développé avec un accent sur un raisonnement multi-étapes fiable, la gestion de très grands documents et une sécurité/une conformité aux politiques améliorées ; la sortie comprend trois variantes orientées utilisateur — Instant, Thinking et Pro — et est d’abord déployée auprès des abonnés payants de ChatGPT et des clients de l’API.
Qu’est-ce que GPT-5.2 et pourquoi est-ce important ?
GPT-5.2 est le dernier membre de la famille GPT-5 — une nouvelle série de modèles « frontier » conçue spécifiquement pour combler l’écart entre les assistants conversationnels en un seul tour et les systèmes qui doivent raisonner sur de longs documents, appeler des outils, interpréter des images et exécuter de manière fiable des workflows multi-étapes. OpenAI positionne 5.2 comme sa version la plus capable pour le travail de connaissance professionnel : il établit de nouveaux résultats à l’état de l’art sur des benchmarks internes (notamment un nouveau benchmark GDPval pour le travail de connaissance), démontre des performances de codage plus solides sur des benchmarks d’ingénierie logicielle, et offre des capacités de contexte long et de vision significativement améliorées.
Concrètement, GPT-5.2 est plus qu’un « modèle de chat plus grand ». C’est une famille de trois variantes optimisées (Instant, Thinking, Pro) qui arbitrent la latence, la profondeur de raisonnement et le coût — et qui, avec l’API d’OpenAI et le routage ChatGPT, peuvent être utilisées pour exécuter de longs travaux de recherche, créer des agents qui appellent des outils externes, interpréter des images et des graphiques complexes, et générer du code de production avec une fidélité supérieure aux versions antérieures. Le modèle prend en charge de très grandes fenêtres de contexte (la documentation d’OpenAI indique une fenêtre de contexte de 400,000 tokens et une limite de sortie maximale de 128,000 pour les modèles phares), de nouvelles fonctionnalités d’API pour des niveaux explicites d’effort de raisonnement, et un comportement d’invocation d’outils « agentique ».
5 capacités clés améliorées dans GPT-5.2
1) GPT-5.2 est-il meilleur en logique multi-étapes et en mathématiques ?
GPT-5.2 apporte un raisonnement multi-étapes plus affûté et des performances nettement plus fortes en mathématiques et en résolution de problèmes structurés. OpenAI indique avoir ajouté un contrôle plus granulaire de l’effort de raisonnement (de nouveaux niveaux tels que xhigh), conçu une prise en charge des tokens de raisonnement et ajusté le modèle pour maintenir une chaîne de raisonnement sur des traces internes plus longues. Des benchmarks comme FrontierMath et des tests de type ARC-AGI montrent des gains substantiels par rapport à GPT-5.1 ; Il affiche des marges plus importantes sur des benchmarks spécifiques à des domaines utilisés dans les workflows scientifiques et financiers. En bref : GPT-5.2 « réfléchit plus longtemps » quand on le lui demande, et peut effectuer un travail symbolique/mathématique plus compliqué avec une meilleure constance.

| RC-AGI-1 (Vérifié) Raisonnement abstrait | 86.2% | 72.8% |
|---|---|---|
| ARC-AGI-2 (Vérifié) Raisonnement abstrait | 52.9% | 17.6% |
GPT-5.2 Thinking établit des records dans plusieurs tests avancés de science et de raisonnement mathématique :
- GPQA Diamond Science Quiz : 92.4% (version Pro 93.2%)
- ARC-AGI-1 Raisonnement abstrait : 86.2% (premier modèle à franchir le seuil de 90%)
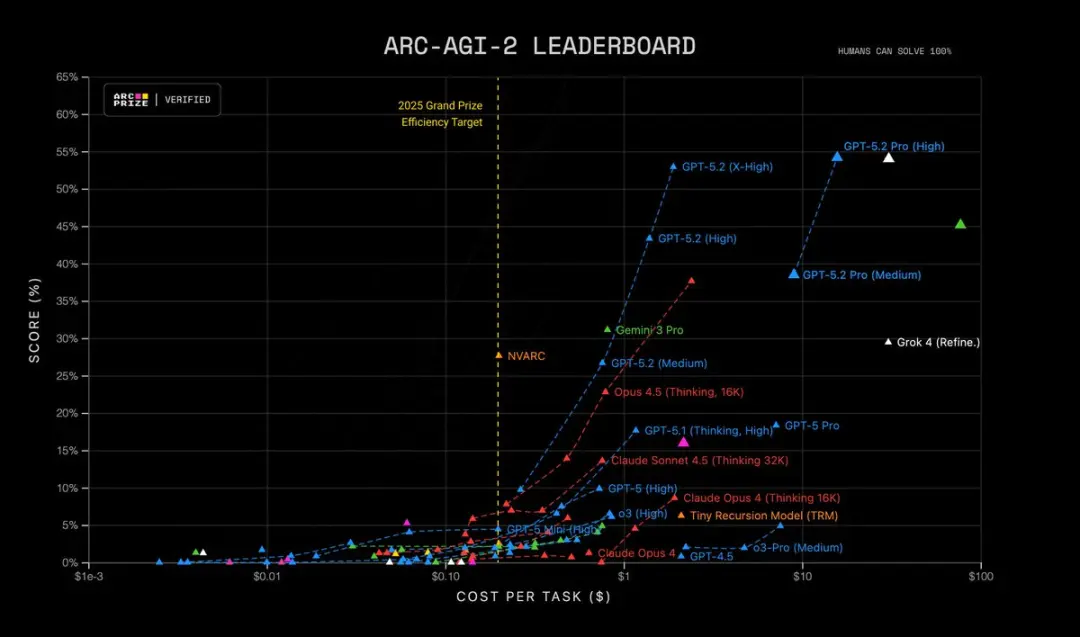
- ARC-AGI-2 Raisonnement d’ordre supérieur : 52.9%, établissant un nouveau record pour le modèle Thinking Chain
- FrontierMath Test de mathématiques avancées : 40.3%, dépassant largement son prédécesseur ;
- HMMT Problèmes de concours de mathématiques : 99.4%
- AIME Test de mathématiques : solution complète à 100%
De plus, GPT-5.2 Pro (High) est à l’état de l’art sur ARC-AGI-2, atteignant un score de 54.2% au coût de $15.72 par tâche ! Surpassant tous les autres modèles.
Pourquoi c’est important : de nombreuses tâches réelles — modélisation financière, conception d’expériences, synthèse de programmes nécessitant un raisonnement formel — sont limitées par la capacité d’un modèle à chaîner de nombreuses étapes correctes. GPT-5.2 réduit les « étapes hallucinées » et produit des traces de raisonnement intermédiaires plus stables lorsque vous lui demandez de montrer son travail.
2) Comment la compréhension des textes longs et le raisonnement interdocuments se sont-ils améliorés ?
La compréhension en contexte long est l’une des améliorations phares. Le modèle sous-jacent de GPT-5.2 prend en charge une fenêtre de contexte de 400k tokens et — plus important — maintient une précision plus élevée à mesure que le contenu pertinent se situe profondément dans ce contexte. GDPval, un ensemble de tâches pour le « travail de connaissance bien spécifié » dans 44 professions, où GPT-5.2 Thinking atteint la parité voire mieux que des juges humains experts sur une large part des tâches. Des rapports indépendants confirment que le modèle retient et synthétise l’information à travers de nombreux documents bien mieux que les modèles précédents. C’est une avancée réellement pratique pour des tâches comme la due diligence, la synthèse juridique, les revues de littérature et la compréhension de bases de code.
GPT-5.2 peut gérer des contextes jusqu’à 256,000 tokens (environ plus de 200 pages de documents). En outre, dans le test de compréhension de texte long « OpenAI MRCRv2 », GPT-5.2 Thinking a atteint un taux de précision proche de 100%.
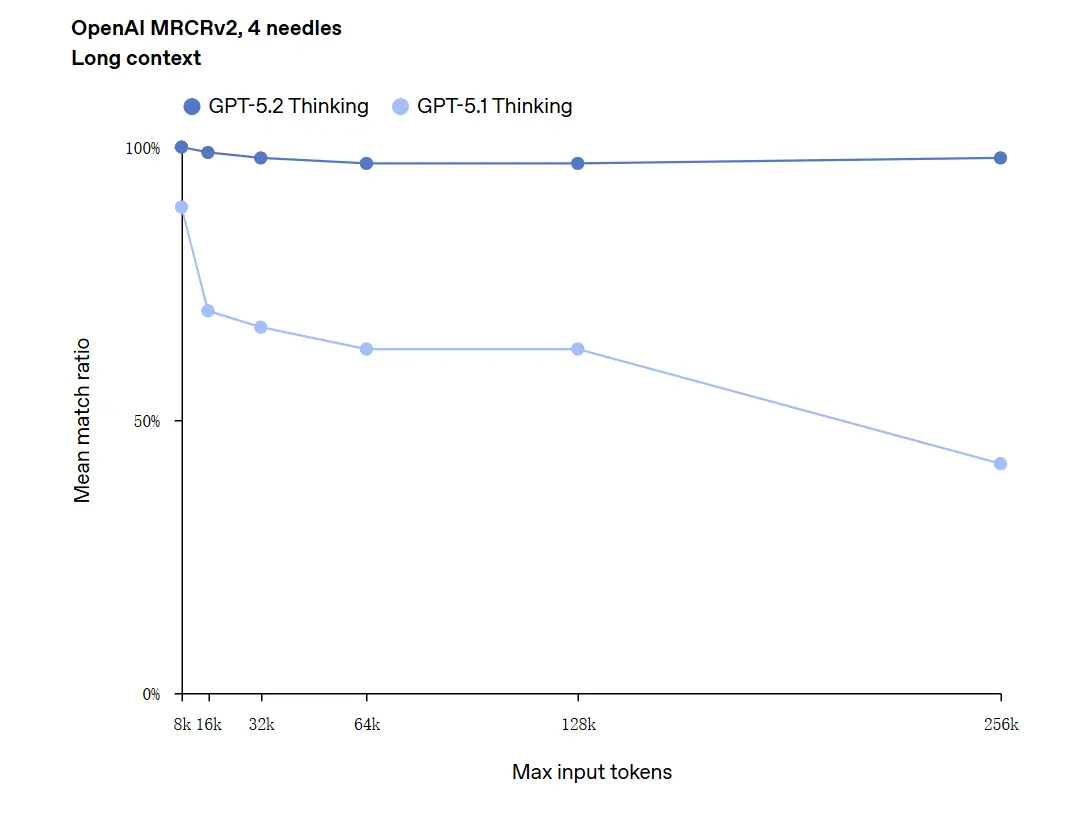
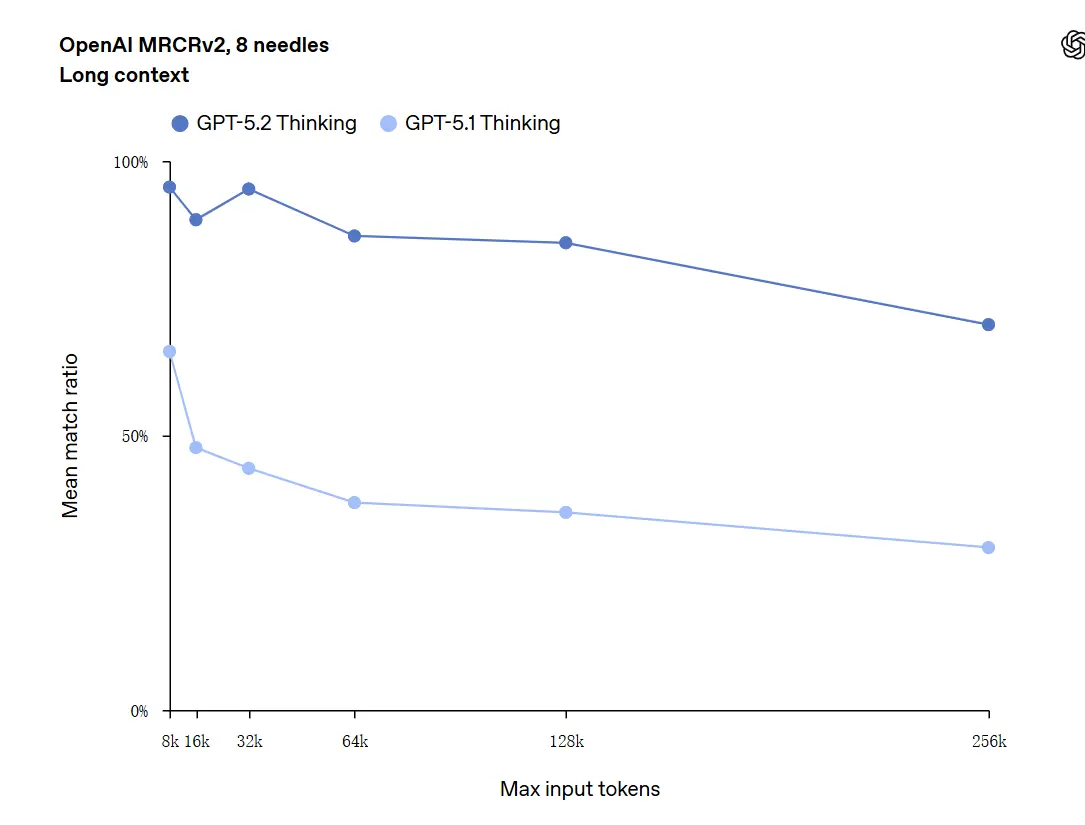
Mise en garde sur « 100% de précision » : Les améliorations ont été décrites comme « approchant 100% » pour des micro-tâches étroites ; les données d’OpenAI sont mieux décrites comme « à l’état de l’art et dans de nombreux cas au niveau ou au-dessus de celui d’experts humains sur les tâches évaluées », pas littéralement parfaites pour tous les usages. Les benchmarks montrent de grands gains mais pas une perfection universelle.
3) Quelles sont les nouveautés en compréhension visuelle et en raisonnement multimodal ?
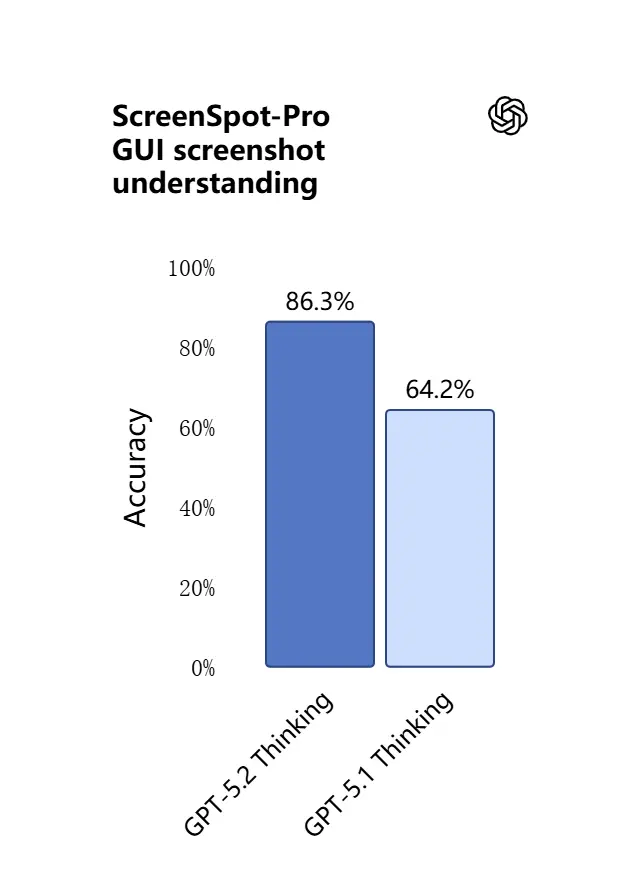
Les capacités de vision dans GPT-5.2 sont plus nettes et plus pratiques. Le modèle est meilleur pour interpréter des captures d’écran, lire des graphiques et des tableaux, reconnaître des éléments d’interface, et combiner des entrées visuelles avec un long contexte textuel. Il ne s’agit pas seulement de légendage : GPT-5.2 peut extraire des données structurées à partir d’images (par ex., des tableaux dans un PDF), expliquer des graphiques, et raisonner sur des diagrammes d’une manière qui soutient des actions d’outils en aval (par ex., générer une feuille de calcul à partir d’un rapport photographié).
.webp)
Effet pratique : les équipes peuvent fournir directement des diaporamas complets, des rapports de recherche scannés ou des documents riches en images au modèle et demander des synthèses interdocuments — réduisant fortement le travail d’extraction manuelle.
4) Comment l’invocation d’outils et l’exécution des tâches ont-elles évolué ?
GPT-5.2 pousse plus loin le comportement agentique : il est meilleur pour planifier des tâches multi-étapes, décider quand appeler des outils externes, et exécuter des séquences d’appels d’API/d’outils pour mener un travail de bout en bout. Des améliorations d’« appel d’outils agentique » — le modèle proposera un plan, appellera des outils (bases de données, calcul, systèmes de fichiers, navigateur, exécuteurs de code), et synthétisera les résultats dans un livrable final plus fiablement que les versions antérieures. L’API introduit un routage et des contrôles de sécurité (listes d’outils autorisés, échafaudage d’outils) et l’interface ChatGPT peut acheminer automatiquement les requêtes vers la variante 5.2 appropriée (Instant vs Thinking).
GPT-5.2 a obtenu 98.7% au benchmark Tau2-Bench Telecom, démontrant ses capacités matures d’appel d’outils dans des tâches complexes multi-tours.
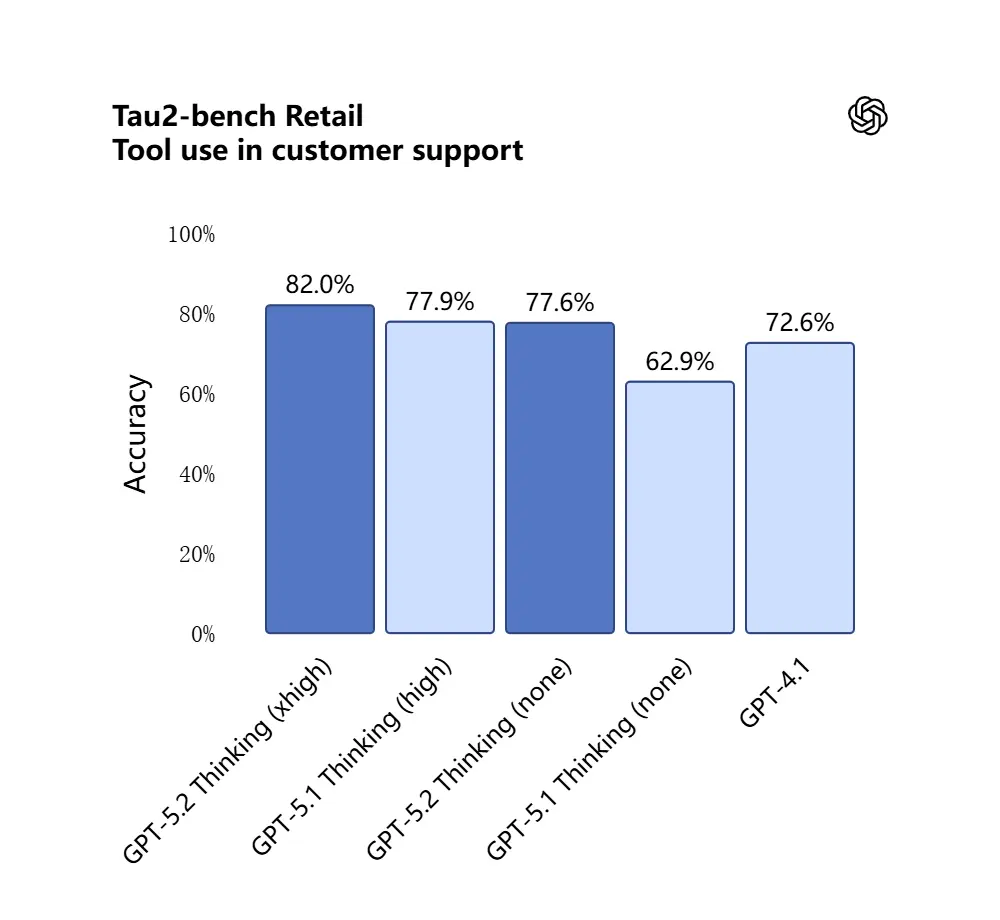
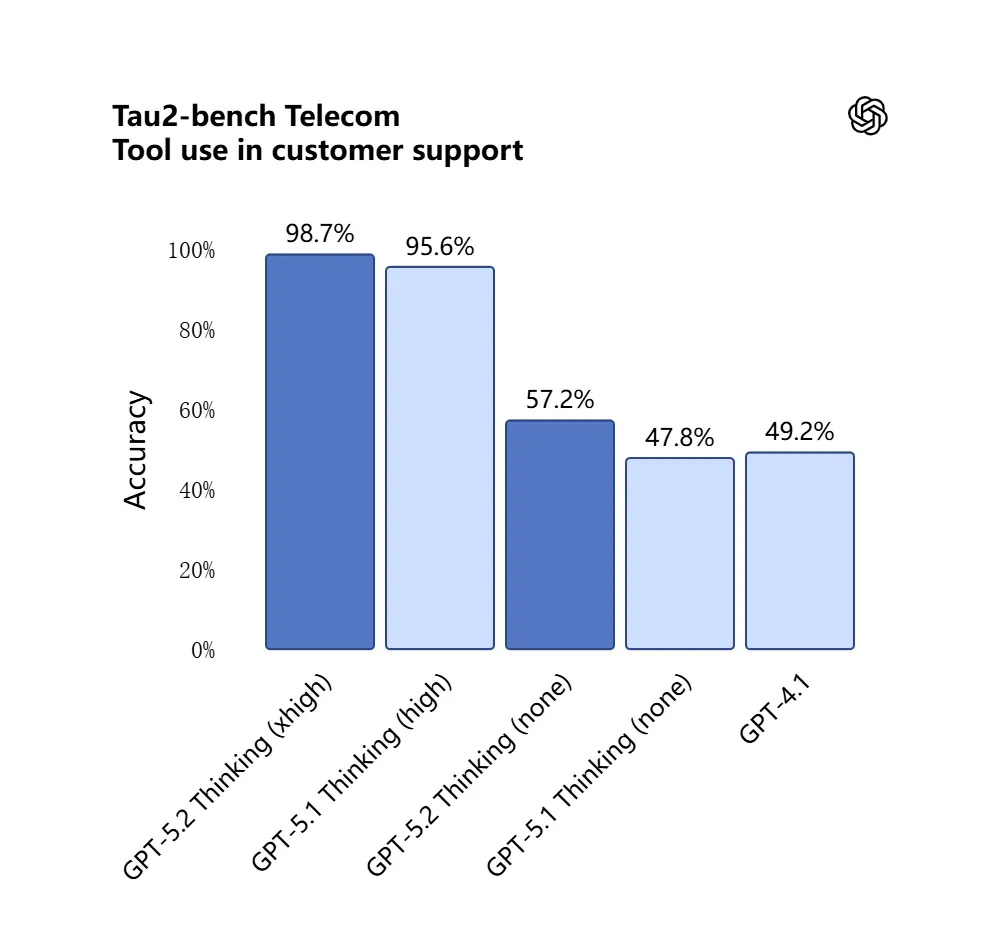
Pourquoi c’est important : cela rend GPT-5.2 plus utile comme assistant autonome pour des workflows tels que « ingérer ces contrats, extraire des clauses, mettre à jour une feuille de calcul, et écrire un e-mail de synthèse » — des tâches qui auparavant nécessitaient une orchestration minutieuse.
5) Capacité de programmation en évolution
GPT-5.2 est nettement meilleur sur les tâches d’ingénierie logicielle : il écrit des modules plus complets, génère et exécute des tests plus fiablement, comprend des graphes de dépendances de projets complexes, et est moins enclin au « codage paresseux » (omission de boilerplate ou incapacité à relier des modules). Sur des benchmarks de codage de niveau industriel (SWE-bench Pro, etc.) GPT-5.2 établit de nouveaux records. Pour les équipes qui utilisent des LLM comme co-programmeurs, cette amélioration peut réduire la vérification manuelle et la reprise nécessaires après génération.
Dans le test SWE-Bench Pro (tâche réelle d’ingénierie logicielle industrielle), le score de GPT-5.2 Thinking a été amélioré à 55.6%, tandis qu’il a également atteint un nouveau sommet de 80% dans le test SWE-Bench Verified.
_Software%20engineering.webp)
Dans les applications pratiques, cela signifie :
- Le débogage automatique du code en environnement de production conduit à une plus grande stabilité ;
- Prise en charge de la programmation multilingue (non limitée à Python) ;
- Capacité à accomplir indépendamment des tâches de réparation de bout en bout.
Quelles sont les différences entre GPT-5.2 et GPT-5.1 ?
Réponse courte : GPT-5.2 est une amélioration itérative mais substantielle. Il conserve l’architecture de la famille GPT-5 et ses fondations multimodales, mais progresse sur quatre dimensions pratiques :
- Profondeur et constance du raisonnement. 5.2 introduit des niveaux d’effort de raisonnement plus élevés et un meilleur chaînage pour les problèmes multi-étapes ; 5.1 avait déjà amélioré le raisonnement, mais 5.2 élève le plafond pour les mathématiques complexes et la logique multi-niveaux.
- Fiabilité en contexte long. Les deux versions ont étendu le contexte, mais 5.2 est ajusté pour maintenir la précision au cœur d’entrées très longues (OpenAI affirme une rétention améliorée jusqu’à des centaines de milliers de tokens).
- Fidélité vision + multimodale. 5.2 améliore le croisage entre images et texte — par ex., lire un graphique et intégrer ces données dans une feuille de calcul — en affichant une précision plus élevée au niveau des tâches.
- Comportement agentique d’outils et fonctionnalités API. 5.2 expose de nouveaux paramètres d’effort de raisonnement (
xhigh) et des fonctionnalités de compaction du contexte dans l’API, et OpenAI a affiné la logique de routage dans ChatGPT afin que l’interface choisisse automatiquement la meilleure variante. - Moins d’erreurs, plus de stabilité : GPT-5.2 réduit son « taux d’illusion » (taux de réponses fausses) de 38%. Il répond plus fiablement aux questions de recherche, d’écriture et d’analyse, réduisant les instances de « faits fabriqués ». Dans des tâches complexes, sa sortie structurée est plus claire et sa logique plus stable. Par ailleurs, la sécurité des réponses du modèle est significativement améliorée pour les tâches liées à la santé mentale. Il fonctionne plus solidement dans des scénarios sensibles comme la santé mentale, l’automutilation, le suicide et la dépendance émotionnelle.
Dans les évaluations système, GPT-5.2 Instant a obtenu 0.995 (sur 1.0) sur la tâche « Aide en santé mentale », significativement plus élevé que GPT-5.1 (0.883).
Quantitativement, les benchmarks publiés par OpenAI montrent des gains mesurables sur GDPval, les benchmarks de mathématiques (FrontierMath), et les évaluations d’ingénierie logicielle. GPT-5.2 surpasse GPT-5.1 dans des tâches de tableur de banque d’investissement junior de plusieurs points de pourcentage.
GPT-5.2 est-il gratuit — combien ça coûte ?
Puis-je utiliser GPT-5.2 gratuitement ?
OpenAI a déployé GPT-5.2 en commençant par les formules payantes de ChatGPT et l’accès API. Historiquement, OpenAI a conservé les modèles les plus rapides/les plus profonds derrière des niveaux payants tout en rendant des variantes plus légères disponibles plus largement plus tard ; avec 5.2, la société a indiqué que le déploiement commencerait sur les formules payantes (Plus, Pro, Business, Enterprise) et que l’API est disponible pour les développeurs. Cela signifie que l’accès immédiat gratuit est limité : le niveau gratuit peut recevoir ultérieurement un accès dégradé ou routé (par exemple vers des sous-variantes plus légères) à mesure qu’OpenAI étend le déploiement.
La bonne nouvelle est que CometAPI s’intègre désormais à GPT-5.2, et qu’il est actuellement en promotion de Noël. Vous pouvez désormais utiliser GPT-5.2 via CometAPI ; le playground vous permet d’interagir librement avec GPT-5.2, et les développeurs peuvent utiliser l’API GPT-5.2 (CometAPI est tarifé à 20% de celui d’OpenAI) pour construire des workflows.
Combien cela coûte via l’API (usage développeur / production) ?
L’utilisation de l’API est facturée par token. Les prix publiés de la plateforme d’OpenAI au lancement affichent (CometAPI est tarifé à 20% de celui d’OpenAI) :
- GPT-5.2 (chat standard) — $1.75 par 1M de tokens d’entrée et $14 par 1M de tokens de sortie (des réductions s’appliquent aux entrées mises en cache).
- GPT-5.2 Pro (phare) — $21 par 1M de tokens d’entrée et $168 par 1M de tokens de sortie (significativement plus cher car destiné à des charges de travail à haute précision et fortement consommatrices de calcul).
- À titre de comparaison, GPT-5.1 était moins cher (par ex., $1.25 entrée / $10 sortie par 1M de tokens).
Interprétation : les coûts de l’API ont augmenté par rapport aux générations précédentes ; le prix indique que les capacités de raisonnement premium et de contexte long de 5.2 sont tarifées comme un niveau de produit distinct. Pour les systèmes de production, les coûts des plans dépendent fortement du nombre de tokens que vous entrez/sortez et de la fréquence à laquelle vous réutilisez les entrées mises en cache (les entrées mises en cache bénéficient de fortes réductions).
Ce que cela signifie en pratique
- Pour un usage occasionnel via l’interface de ChatGPT, les plans d’abonnement mensuels (Plus, Pro, Business, Enterprise) sont la voie principale. Les prix des niveaux d’abonnement ChatGPT n’ont pas changé avec la sortie 5.2 (OpenAI maintient des prix de plans stables même si l’offre de modèles change).
- Pour un usage en production et développeur, budgétez les coûts en tokens. Si votre application diffuse beaucoup de longues réponses ou traite de longs documents, le prix des tokens de sortie ($14 / 1M tokens pour Thinking) dominera les coûts à moins de mettre soigneusement en cache les entrées et de réutiliser les sorties.
GPT-5.2 Instant vs GPT-5.2 Thinking vs GPT-5.2 Pro
OpenAI a lancé GPT-5.2 avec trois variantes adaptées aux usages : Instant, Thinking, et Pro :
- GPT-5.2 Instant : rapide, économique, optimisé pour le travail quotidien — FAQ, guides, traductions, rédaction rapide. Latence plus faible ; bons premiers jets et workflows simples.
- GPT-5.2 Thinking : réponses plus profondes et de meilleure qualité pour un travail soutenu — synthèse de longs documents, planification multi-étapes, revues de code détaillées. Latence et qualité équilibrées ; le « cheval de bataille » par défaut pour les tâches professionnelles.
- GPT-5.2 Pro : qualité et fiabilité maximales. Plus lent et plus coûteux ; idéal pour des tâches difficiles et à forts enjeux (ingénierie complexe, synthèse juridique, décisions à forte valeur) et lorsque qu’un effort de raisonnement « xhigh » est requis.
Tableau de comparaison
| Fonctionnalité / Mesure | GPT-5.2 Instant | GPT-5.2 Thinking | GPT-5.2 Pro |
|---|---|---|---|
| Usage prévu | Tâches quotidiennes, brouillons rapides | Analyse approfondie, documents longs | Qualité maximale, problèmes complexes |
| Latence | La plus faible | Modérée | La plus élevée |
| Effort de raisonnement | Standard | Élevé | xHigh disponible |
| Idéal pour | FAQ, tutoriels, traductions, prompts courts | Résumés, planification, feuilles de calcul, tâches de codage | Ingénierie complexe, synthèse juridique, recherche |
| Exemples de nom d’API | gpt-5.2-chat-latest | gpt-5.2 | gpt-5.2-pro |
| Prix token d’entrée (API) | $1.75 / 1M | $1.75 / 1M | $21 / 1M |
| Prix token de sortie (API) | $14 / 1M | $14 / 1M | $168 / 1M |
| Disponibilité (ChatGPT) | Déploiement progressif ; plans payants puis plus large | Déploiement vers les plans payants | Utilisateurs Pro / Enterprise (payant) |
| Exemple de cas d’usage | Rédaction d’e-mails, petits extraits de code | Construire un modèle financier multi-feuilles, Questions-Réponses sur un long rapport | Auditer une base de code, générer un design système de niveau production |
Qui est concerné par l’utilisation de GPT-5.2 ?
GPT-5.2 est conçu pour un large ensemble d’utilisateurs cibles. Ci-dessous des recommandations par rôle :
Entreprises et équipes produit
Si vous construisez des produits de travail de connaissance (assistants de recherche, revue de contrats, pipelines analytiques ou outils développeur), les capacités de contexte long et agentiques de GPT-5.2 peuvent réduire significativement la complexité d’intégration. Les entreprises qui ont besoin d’une compréhension robuste des documents, de rapports automatisés ou de copilotes intelligents trouveront Thinking/Pro utiles. Microsoft et d’autres partenaires de plateforme intègrent déjà 5.2 dans des suites de productivité (par ex., Microsoft 365 Copilot).
Développeurs et équipes d’ingénierie
Les équipes qui veulent utiliser des LLM comme co-programmeurs ou pour automatiser la génération/test de code bénéficieront de la fidélité de programmation améliorée de 5.2. L’accès API (avec les modes thinking ou pro) permet des synthèses plus profondes de grandes bases de code grâce à la fenêtre de contexte de 400k tokens. Attendez-vous à payer davantage via l’API en utilisant Pro, mais la réduction du débogage et des revues manuels peut justifier ce coût pour des systèmes complexes.
Chercheurs et analystes axés sur les données
Si vous synthétisez régulièrement de la littérature, parsez de longs rapports techniques, ou souhaitez une conception d’expériences assistée par modèle, le contexte long et les améliorations en mathématiques de GPT-5.2 accélèrent les workflows. Pour une recherche reproductible, associez le modèle à une ingénierie de prompt soignée et des étapes de vérification.
Petites entreprises et utilisateurs avancés
ChatGPT Plus (et Pro pour les utilisateurs avancés) bénéficiera d’un accès routé aux variantes 5.2 ; cela rend l’automatisation avancée et des sorties de haute qualité accessibles à de petites équipes sans construire une intégration API. Pour les utilisateurs non techniques qui ont besoin d’une meilleure synthèse de documents ou de création de diapositives, GPT-5.2 apporte une valeur pratique notable.
Notes pratiques pour les développeurs et les opérateurs
Fonctionnalités API à surveiller
- Niveaux
reasoning.effort(par ex.,medium,high,xhigh) vous permettent d’indiquer au modèle combien de calcul consacrer au raisonnement interne ; utilisez-les pour arbitrer la latence et la précision requête par requête. - Compactage du contexte : l’API inclut des outils pour compresser et compacter l’historique afin que le contenu réellement pertinent soit préservé sur de longues chaînes. C’est crucial lorsque vous devez maintenir l’utilisation de tokens effective maîtrisée.
- Échafaudage d’outils et contrôles des outils autorisés : les systèmes de production doivent explicitement définir la liste blanche de ce que le modèle peut invoquer et journaliser les appels d’outils pour l’audit.
Conseils de maîtrise des coûts
- Mettez en cache des embeddings de documents fréquemment utilisés et utilisez des entrées mises en cache (qui bénéficient de fortes réductions) pour des requêtes répétées sur le même corpus. La tarification de la plateforme d’OpenAI inclut des réductions significatives pour les entrées mises en cache.
- Dirigez les requêtes exploratoires/à faible valeur vers Instant et réservez Thinking/Pro pour des traitements par lots ou des passes finales.
- Estimez soigneusement l’utilisation de tokens (entrée + sortie) lorsque vous projetez les coûts API, car les longues sorties multiplient le coût.
En bref — devriez-vous passer à GPT-5.2 ?
Si votre travail dépend du raisonnement sur de longs documents, de la synthèse interdocuments, de l’interprétation multimodale (images + texte), ou de la construction d’agents qui appellent des outils, GPT-5.2 est une mise à niveau évidente : il augmente la précision pratique et réduit le travail d’intégration manuel. Si vous exploitez principalement des chatbots à grand volume et faible latence ou des applications strictement contraintes par le budget, Instant (ou des modèles antérieurs) peut rester un choix raisonnable.
GPT-5.2 représente un passage délibéré de « meilleur chat » à « meilleur assistant professionnel » : plus de calcul, plus de capacités, et des niveaux de coût plus élevés — mais aussi de vrais gains de productivité pour les équipes capables de tirer parti d’un contexte long fiable, d’une meilleure compréhension des mathématiques/du raisonnement, de la compréhension d’images et de l’exécution agentique d’outils.
Pour commencer, explorez les modèles GPT-5.2(GPT-5.2;GPT-5.2 pro, GPT-5.2 chat ) et leurs capacités dans le Playground et consultez le guide API pour des instructions détaillées. Avant l’accès, veuillez vous assurer que vous êtes connecté à CometAPI et que vous avez obtenu la clé API. CometAPI propose un prix bien inférieur au prix officiel pour vous aider à intégrer.
Prêt à démarrer ?→ Essai gratuit des modèles gpt-5.2 !