

GPT-5-Codex est la nouvelle version de GPT-5 d'OpenAI, axée sur l'ingénierie, spécialement conçue pour l'ingénierie logicielle agentique au sein de la famille de produits Codex. Elle est conçue pour prendre en charge des workflows d'ingénierie concrets et de grande envergure : création de projets complets de A à Z, ajout de fonctionnalités et de tests, débogage, refactorisations et revues de code tout en interagissant avec des outils et suites de tests externes. Cette version représente une amélioration ciblée du produit plutôt qu'un tout nouveau modèle fondamental : OpenAI a intégré GPT-5-Codex à Codex CLI, à l'extension Codex IDE, à Codex Cloud, aux workflows GitHub et aux expériences mobiles ChatGPT ; la disponibilité de l'API est prévue, mais pas immédiate.
Qu’est-ce que GPT-5-Codex et pourquoi existe-t-il ?
GPT-5-Codex est GPT-5 « spécialisé pour le codage ». Au lieu d'être un assistant conversationnel général, il est optimisé et entraîné grâce à l'apprentissage par renforcement et à des ensembles de données spécifiques à l'ingénierie pour mieux prendre en charge les tâches de codage itératives assistées par outils (par exemple : exécution de tests, itération sur les échecs, refactorisation de modules et respect des conventions de programmation). OpenAI le présente comme le successeur des précédents Codex, mais s'appuie sur l'infrastructure GPT-5 pour améliorer la profondeur de raisonnement sur les bases de code volumineuses et optimiser la fiabilité des tâches d'ingénierie en plusieurs étapes.
La motivation est pratique : les workflows des développeurs s'appuient de plus en plus sur des agents capables de faire plus que des suggestions d'extraits isolés. En alignant spécifiquement un modèle sur la boucle « générer → exécuter des tests → corriger → répéter » et sur les normes organisationnelles de relations publiques, OpenAI vise à créer une IA qui se comporte comme un coéquipier plutôt que comme une source de réalisations ponctuelles. Ce passage de « générer une fonction » à « livrer une fonctionnalité » constitue la valeur unique du modèle.
Comment GPT-5-Codex est-il architecturé et formé ?
Architecture de haut niveau
GPT-5-Codex est une variante de l'architecture GPT-5 (la lignée élargie de GPT-5) plutôt qu'une architecture entièrement nouvelle. Cela signifie qu'il hérite de la conception basée sur les transformateurs, des propriétés de mise à l'échelle et des améliorations de raisonnement de GPT-5, mais ajoute un entraînement spécifique à Codex et un réglage fin basé sur l'apprentissage par renforcement (RL) ciblant les tâches d'ingénierie logicielle. L'addendum d'OpenAI décrit GPT-5-Codex comme étant entraîné pour des tâches d'ingénierie complexes et concrètes et met l'accent sur l'apprentissage par renforcement dans les environnements où le code est exécuté et validé.
Comment a-t-il été formé et optimisé pour le code ?
Le programme de formation du GPT-5-Codex met l'accent sur tâches d'ingénierie du monde réelIl utilise un réglage fin de type apprentissage par renforcement sur des ensembles de données et des environnements construits à partir de workflows de développement logiciel concrets : refactorisations multifichiers, différences de PR, exécution de suites de tests, sessions de débogage et signaux de révision humaine. L'objectif de l'entraînement est de maximiser l'exactitude des modifications de code, de réussir les tests et de produire des commentaires de révision précis et pertinents. C'est cette approche qui différencie Codex du réglage fin général basé sur le chat : les fonctions de perte, les harnais d'évaluation et les signaux de récompense sont alignés sur les résultats d'ingénierie (réussite des tests, différences correctes, réduction des commentaires erronés).
À quoi ressemble la formation « agentique »
- Réglage fin axé sur l'exécutionLe modèle est entraîné dans des contextes où le code généré est exécuté, testé et évalué. Les boucles de rétroaction, issues des résultats des tests et des signaux de préférences humaines, encouragent le modèle à itérer jusqu'à la réussite d'une suite de tests.
- Apprentissage par renforcement à partir de la rétroaction humaine (RLHF):Similaire dans l'esprit aux travaux antérieurs du RLHF, mais appliqué aux tâches de codage en plusieurs étapes (créer un PR, exécuter des tests, corriger les échecs), de sorte que le modèle apprend l'attribution de crédits temporels sur une séquence d'actions.
- Contexte à l'échelle du dépôt:La formation et l'évaluation incluent de grands référentiels et des refactorisations, aidant le modèle à apprendre le raisonnement inter-fichiers, les conventions de nommage et les impacts au niveau de la base de code. ()
Comment GPT-5-Codex gère-t-il l'utilisation des outils et les interactions avec l'environnement ?
Une fonctionnalité architecturale clé réside dans la capacité améliorée du modèle à appeler et coordonner des outils. Codex combinait historiquement les sorties du modèle avec un petit système d'exécution/agent capable d'exécuter des tests, d'ouvrir des fichiers ou d'appeler des fonctions de recherche. GPT-5-Codex étend cette fonctionnalité en apprenant à appeler les outils et en intégrant mieux les retours de test dans la génération de code ultérieure, bouclant ainsi efficacement la boucle entre synthèse et vérification. Ceci est réalisé par l'entraînement sur des trajectoires où le modèle émet des actions (comme « exécuter le test X ») et conditionne les générations ultérieures sur les sorties de test et les différences.
Que peut réellement faire GPT-5-Codex ? Quelles sont ses fonctionnalités ?
L’une des innovations de produits déterminantes est durée de la pensée adaptativeGPT-5-Codex ajuste la quantité de raisonnement caché qu'il effectue : les requêtes triviales s'exécutent rapidement et à moindre coût, tandis que les refactorisations complexes ou les tâches longues permettent au modèle de « réfléchir » beaucoup plus longtemps. Parallèlement, pour les petits tours interactifs, le modèle consomme beaucoup moins de jetons qu'une instance GPT-5 à usage général. Il économise 93.7 % de jetons (y compris l'inférence et la sortie) par rapport à GPT-5. Cette stratégie de raisonnement variable vise à produire des réponses rapides lorsque cela est nécessaire et une exécution approfondie et minutieuse lorsque cela est justifié.
Compétence de base
- Génération et amorçage de projets : Créez des squelettes de projets entiers avec CI, des tests et une documentation de base à partir d'invites de haut niveau.
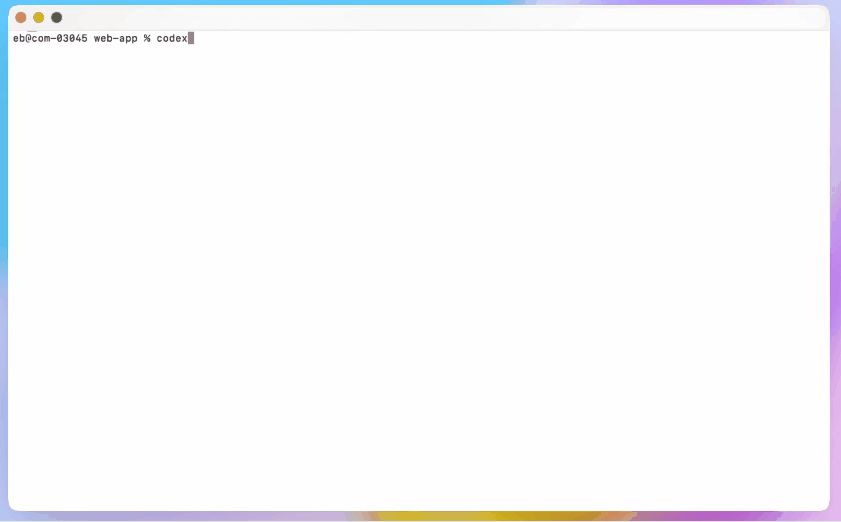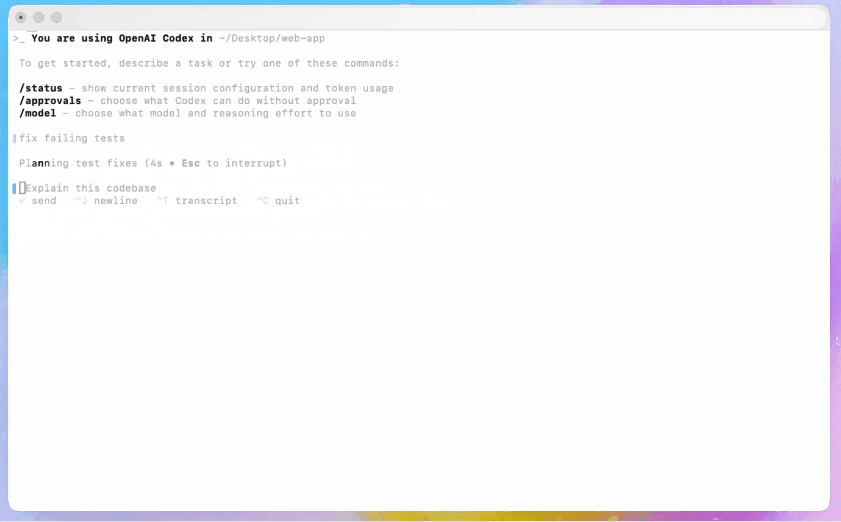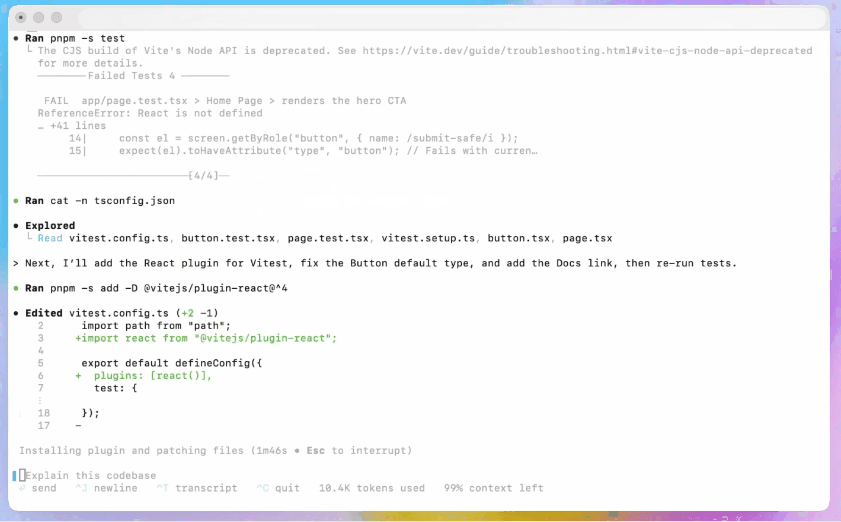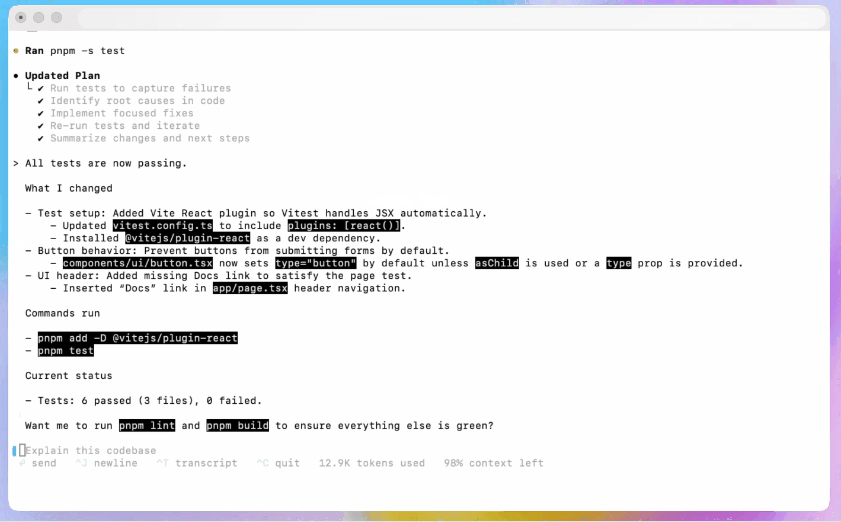
- Tests et itérations agentiques : Générez du code, exécutez des tests, analysez les échecs, corrigez le code et réexécutez-le jusqu'à ce que les tests réussissent, automatisant ainsi efficacement certaines parties de la boucle édition → test → correction d'un développeur.
- Refactorisation à grande échelle : Effectuez des refactorisations systématiques sur de nombreux fichiers tout en préservant le comportement et les tests. Il s'agit d'un domaine d'optimisation déclaré pour GPT-5-Codex par rapport à GPT-5 générique.
- Revue de code et génération de PR : Produisez des descriptions de relations publiques, des suggestions de modifications avec des différences et des commentaires de révision qui correspondent aux conventions du projet et aux attentes en matière de révision humaine.
- Raisonnement de code à grand contexte : Meilleur pour naviguer et raisonner sur les bases de code multi-fichiers, les graphiques de dépendances et les limites de l'API par rapport aux modèles de chat génériques.
- Entrées et sorties visuelles : Lorsqu'il travaille dans le cloud, GPT-5-Codex peut accepter des images/captures d'écran, inspecter visuellement la progression et joindre des artefacts visuels (captures d'écran de l'interface utilisateur créée) aux tâches - une aubaine pratique pour le débogage front-end et les flux de travail d'assurance qualité visuelle.
Intégrations de l'éditeur et du flux de travail
Codex est profondément intégré dans les flux de travail des développeurs :
- Codex CLI — Interaction terminal-first, prise en charge des captures d'écran, du suivi des tâches et des approbations des agents. L'interface de ligne de commande (CLI) est open source et optimisée pour les workflows de codage agentique.
- Extension Codex IDE — intègre l'agent dans VS Code (et les forks) afin que vous puissiez prévisualiser les différences locales, créer des tâches cloud et déplacer le travail entre les contextes cloud et locaux avec un état préservé.
- Codex Cloud / GitHub — les tâches cloud peuvent être configurées pour examiner automatiquement les PR, générer des conteneurs temporaires pour les tests et joindre des journaux de tâches et des captures d'écran aux threads PR.
Limitations et compromis notables
- Optimisation étroite:Certaines évaluations de production non codantes sont légèrement inférieures pour GPT-5-Codex que pour la variante générale GPT-5 — un rappel que la spécialisation peut compromettre la généralité.
- Dépendance aux testsLe comportement agentique dépend des tests automatisés disponibles. Les bases de code avec une couverture de tests insuffisante exposent les utilisateurs à des limites de vérification automatique et peuvent nécessiter une intervention humaine.
Dans quels types de tâches GPT-5-Codex est-il particulièrement efficace ou inefficace ?
Bon à : refactorisations complexes, création d'échafaudages pour de grands projets, écriture et correction de tests, suivi des attentes en matière de relations publiques et diagnostic des problèmes d'exécution multi-fichiers.
Moins bon à : Les tâches nécessitant des connaissances internes de pointe ou propriétaires, non disponibles dans l'espace de travail, ou celles exigeant une exactitude hautement garantie sans révision humaine (les systèmes critiques pour la sécurité nécessitent toujours l'intervention d'experts). Des analyses indépendantes révèlent également une image mitigée de la qualité du code brut par rapport à d'autres modèles de codage spécialisés : les points forts des workflows agentiques ne se traduisent pas uniformément par une exactitude optimale dans tous les benchmarks.
Que révèlent les benchmarks sur les performances de GPT-5-Codex ?
Banc SWE / Banc SWE Vérifié: OpenAI affirme que GPT-5-Codex surpasse GPT-5 sur les benchmarks de codage agentique tels que SWE-bench Verified, et montre des gains sur les tâches de refactorisation de code tirées de grands référentiels. Sur l'ensemble de données SWE-bench Verified, qui contient 500 tâches d'ingénierie logicielle réelles, GPT-5-Codex a atteint un taux de réussite de 74.5 %. Ce taux surpasse les 5 % de GPT-72.8 sur le même benchmark, soulignant les capacités améliorées de l'agent. 500 tâches de programmation issues de véritables projets open source. Auparavant, seules 477 tâches pouvaient être testées, mais maintenant les 500 tâches peuvent être testées → résultats plus complets.
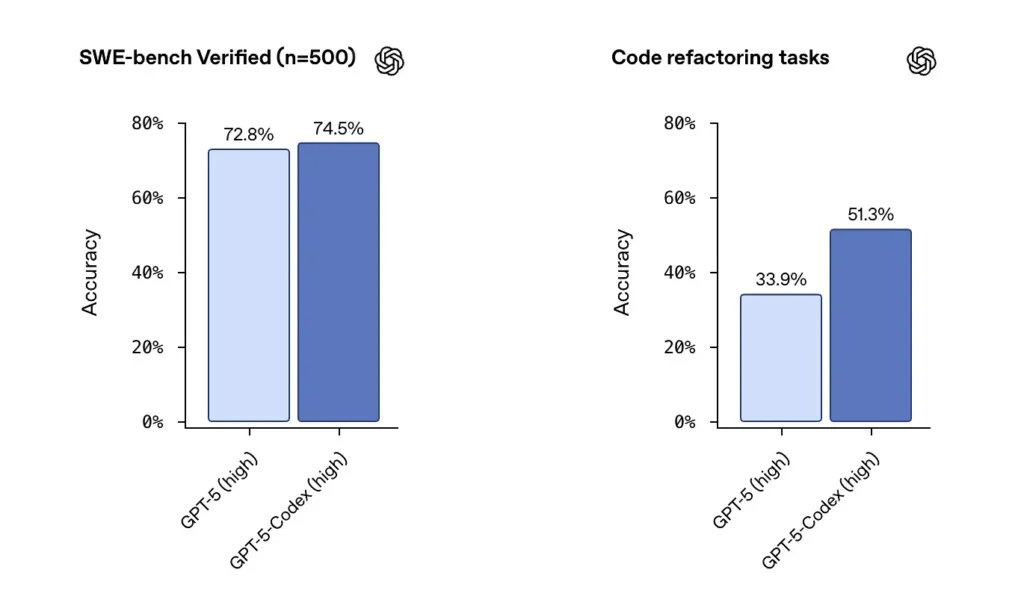
Depuis les paramètres GPT-5 antérieurs vers GPT-5-Codex, les scores d'évaluation de la refactorisation de code ont sensiblement augmenté — des chiffres comme le passage d'environ 34 % à environ 51 % sur une métrique de refactorisation spécifique à haute verbosité ont été mis en évidence dans les premières analyses). Ces gains sont significatifs dans la mesure où ils reflètent une amélioration sur refactorisations importantes et réalistes plutôt que des exemples de jouets — mais des réserves subsistent quant à la reproductibilité et au harnais de test exact.
Comment les développeurs et les équipes peuvent-ils accéder au GPT-5-Codex ?
OpenAI a intégré GPT-5-Codex aux interfaces produit Codex : il est disponible partout où Codex est actuellement exécuté (par exemple, dans l'interface de ligne de commande Codex et les expériences Codex intégrées). Pour les développeurs utilisant Codex via l'interface de ligne de commande et la connexion ChatGPT, l'expérience Codex mise à jour affichera le modèle GPT-5-Codex. OpenAI a annoncé que le modèle serait bientôt disponible dans l'API élargie pour les utilisateurs de clés API, mais, pour le déploiement initial, l'accès principal se fait via les outils Codex plutôt que via un point de terminaison d'API public.
Codex CLI
Autorisez Codex à examiner les projets de PR dans un dépôt sandbox afin d'évaluer la qualité des commentaires sans risque. Utilisez les modes d'approbation avec prudence.
- Repensé autour d'un flux de travail de codage agentique.
- La prise en charge de la connexion d'images (telles que des wireframes, des conceptions et des captures d'écran de bogues d'interface utilisateur) fournit un contexte pour les modèles.
- Ajout d'une fonctionnalité de liste de tâches pour suivre la progression des tâches complexes.
- Fournit un support d'outils externes (recherche Web, connexion MCP).
- La nouvelle interface du terminal améliore l'invocation des outils et le formatage des différences, et le mode d'autorisation a été simplifié à trois niveaux (lecture seule, automatique et accès complet).
Extension IDE
Intégrer dans les flux de travail IDE : Ajoutez l'extension Codex IDE pour les développeurs souhaitant des aperçus en ligne et des itérations plus rapides. Le transfert de tâches entre le cloud et le local, tout en préservant le contexte, peut réduire les frictions sur les fonctionnalités complexes.
- Prend en charge VS Code, Cursor et plus encore.
- Appelez Codex directement depuis l'éditeur pour exploiter le contexte du fichier et du code actuellement ouverts pour des résultats plus précis.
- Basculez de manière transparente les tâches entre les environnements locaux et cloud, en maintenant la continuité contextuelle.
- Affichez et travaillez avec les résultats des tâches cloud directement dans l'éditeur, sans changer de plate-forme.
Intégration GitHub et fonctions cloud
- Examen PR automatisé : déclenche automatiquement la progression du brouillon à la version prête.
- Aide les développeurs à demander des évaluations ciblées directement dans la section @codex d'une PR.
- Infrastructure cloud nettement plus rapide : réduisez les temps de réponse des tâches de 90 % grâce à la mise en cache des conteneurs.
- Configuration automatisée de l'environnement : exécute les scripts d'installation et installe les dépendances (par exemple, pip install).
- Exécute automatiquement un navigateur, vérifie les implémentations frontales et joint des captures d'écran aux tâches ou aux PR.

Quelles sont les considérations en matière de sécurité, de sûreté et de limitation ?
OpenAI met l'accent sur plusieurs couches d'atténuation pour les agents du Codex :
- Formation au niveau du modèle : formation ciblée en matière de sécurité pour résister aux injections rapides et limiter les comportements nocifs ou à haut risque.
- Contrôles au niveau du produit : Comportement par défaut en sandbox, accès réseau configurable, modes d'approbation pour l'exécution des commandes, journaux de terminal et citations pour la traçabilité, et possibilité d'exiger des approbations humaines pour les actions sensibles. OpenAI a également publié un « addendum à la fiche système » décrivant ces mesures d'atténuation et leurs évaluations des risques, notamment pour les capacités des domaines biologique et chimique.
Ces contrôles reflètent le fait qu'un agent capable d'exécuter des commandes et d'installer des dépendances dispose d'une surface d'attaque et d'un risque réels. L'approche d'OpenAI consiste à combiner la formation du modèle avec les contraintes du produit pour limiter les abus.
Quelles sont les limitations connues ?
- Ne remplace pas les réviseurs humains : OpenAI recommande explicitement le Codex comme supplémentaire Examinateur, pas remplaçant. La supervision humaine reste essentielle, notamment pour les décisions relatives à la sécurité, aux licences et à l'architecture.
- Les repères et les revendications doivent être lus attentivement : Les évaluateurs ont souligné des différences dans les sous-ensembles d'évaluation, les paramètres de verbosité et les compromis de coût lors de la comparaison des modèles. Les premiers tests indépendants suggèrent des résultats mitigés : Codex présente un comportement agentique marqué et des améliorations en termes de refactorisation, mais la précision relative par rapport aux autres fournisseurs varie selon le benchmark et la configuration.
- Hallucinations et comportements instables : Comme tous les LLM, Codex peut halluciner (inventer des URL, déformer les graphes de dépendances), et ses agents, qui s'exécutent sur plusieurs heures, peuvent néanmoins rencontrer des problèmes dans certains cas extrêmes. Attendez-vous à valider ses résultats par des tests et une révision humaine.
Quelles sont les implications plus larges pour l’ingénierie logicielle ?
Le Codex GPT-5 démontre un changement de maturité dans la conception des LLM : au lieu de se contenter d'améliorer les capacités du langage nu, les fournisseurs optimisent humain pour les tâches longues et complexes (exécution sur plusieurs heures, développement piloté par les tests, pipelines de révision intégrés). Cela modifie l'unité de productivité : d'un simple extrait généré, achèvement de la tâche — la capacité du modèle à prendre un ticket, exécuter une série de tests et produire de manière itérative une implémentation validée. Si ces agents deviennent robustes et bien gérés, ils transformeront les flux de travail (moins de refactorisations manuelles, cycles de relations publiques plus rapides, temps de développement concentré sur la conception et la stratégie). Mais cette transition nécessite une conception rigoureuse des processus, une supervision humaine et une gouvernance de la sécurité.
Conclusion — Que faut-il retenir ?
Le GPT-5-Codex est une étape ciblée vers ingénieur LLM : une variante de GPT-5 entraînée, optimisée et productisée pour agir comme un agent de codage performant au sein de l'écosystème Codex. Elle apporte de nouveaux comportements tangibles : temps de raisonnement adaptatif, exécutions autonomes longues, exécution intégrée en sandbox et améliorations ciblées de la revue de code, tout en conservant les contraintes habituelles des modèles de langage (nécessité d'une supervision humaine, nuances d'évaluation et hallucinations occasionnelles). Pour les équipes, la voie prudente est l'expérimentation mesurée : piloter sur des dépôts sécurisés, surveiller les indicateurs de résultats et intégrer progressivement l'agent aux workflows des réviseurs. À mesure qu'OpenAI étend l'accès aux API et que les benchmarks tiers prolifèrent, nous devrions nous attendre à des comparaisons plus claires et à des orientations plus concrètes sur les coûts, la précision et la gouvernance des bonnes pratiques.
Pour commencer
CometAPI est une plateforme d'API unifiée qui regroupe plus de 500 modèles d'IA provenant de fournisseurs leaders, tels que la série GPT d'OpenAI, Google Gemini, Claude d'Anthropic, Midjourney, Suno, etc., au sein d'une interface unique et conviviale pour les développeurs. En offrant une authentification, un formatage des requêtes et une gestion des réponses cohérents, CometAPI simplifie considérablement l'intégration des fonctionnalités d'IA dans vos applications. Que vous développiez des chatbots, des générateurs d'images, des compositeurs de musique ou des pipelines d'analyse pilotés par les données, CometAPI vous permet d'itérer plus rapidement, de maîtriser les coûts et de rester indépendant des fournisseurs, tout en exploitant les dernières avancées de l'écosystème de l'IA.
Les développeurs peuvent accéder API GPT-5-Codex Grâce à CometAPI, les derniers modèles de CometAPI répertoriés sont ceux en vigueur à la date de publication de l'article. Avant d'y accéder, assurez-vous d'être connecté à CometAPI et d'avoir obtenu la clé API.