

Kimi K2 Thinking est la nouvelle variante « pensante » de la famille Kimi K2 développée par Moonshot AI : un modèle Mixture-of-Experts (MoE) clairsemé à mille milliards de paramètres, conçu spécifiquement pour Réfléchissez en agissant — c’est-à-dire, entrelacer un raisonnement complexe et structuré avec des appels d’outils fiables, une planification à long terme et des autocontrôles automatisés. Il combine une architecture robuste et clairsemée (≈1 T de paramètres au total, ~32 milliards activés par jeton), un pipeline de quantification INT4 natif et une conception évolutive. temps d'inférence raisonnement (plus de « jetons de réflexion » et plus d’itérations d’appel d’outils) plutôt que de simplement augmenter le nombre de paramètres statiques.
En clair : K2 Thinking considère le modèle comme un outil de résolution de problèmes agent Au lieu d'un générateur de langage ponctuel, ce changement – d'un « modèle de langage » à un « modèle de pensée » – confère à cette version son caractère remarquable et explique pourquoi de nombreux spécialistes la considèrent comme une étape importante dans le domaine de l'IA agentielle open source.
Que signifie exactement « Kimi K2 Thinking » ?
Architecture et spécifications clés
K2 Thinking est construit comme un modèle MoE clairsemé (384 experts, 8 experts sélectionnés par jeton) avec environ 1 billion de paramètres au total et ~32B paramètres activés Ce modèle utilise une architecture hybride (attention MLA, activations SwiGLU) et a été entraîné avec l'optimiseur Muon/MuonClip de Moonshot, en appliquant des budgets de jetons importants, comme décrit dans leur rapport technique. La variante « thinking » étend le modèle de base avec une quantification post-entraînement (prise en charge native d'INT4), une fenêtre de contexte de 256 000 jetons et des mécanismes d'ingénierie permettant d'exposer et de stabiliser la trace de raisonnement interne du modèle lors de son utilisation réelle.
Ce que signifie « penser » en pratique
Ici, « penser » désigne un objectif d'ingénierie : permettre au modèle de : (1) générer de longues chaînes structurées de raisonnement interne (jetons de la chaîne de pensée) ; (2) faire appel à des outils externes (recherche, environnements d'exécution Python, navigateurs, bases de données) dans le cadre de ce raisonnement ; (3) évaluer et auto-vérifier les affirmations intermédiaires ; et (4) itérer sur de nombreux cycles de ce type sans perte de cohérence. La documentation et la fiche du modèle Moonshot montrent que K2 Thinking a été explicitement entraîné et optimisé pour entrelacer le raisonnement et les appels de fonctions, et pour conserver un comportement d'agent stable sur des centaines d'étapes.
Quel est l'objectif principal ?
Les limites des modèles traditionnels à grande échelle sont les suivantes :
- Le processus de génération est à courte vue, dépourvu de logique transversale ;
- L'utilisation des outils est limitée (généralement, seuls les outils externes peuvent être appelés une ou deux fois) ;
- Ils ne peuvent pas s'autocorriger face à des problèmes complexes.
L'objectif principal de K2 Thinking est de résoudre ces trois problèmes. En pratique, K2 Thinking peut, sans intervention humaine : exécuter 200 à 300 appels d'outils consécutifs ; maintenir des centaines d'étapes de raisonnement logiquement cohérent ; résoudre des problèmes complexes grâce à une auto-vérification contextuelle.
Repositionnement : modèle de langage → modèle de pensée
Le projet K2 Thinking illustre un changement stratégique plus large dans le domaine : aller au-delà de la génération de texte conditionnelle pour aller résolveurs de problèmes agentsL’objectif principal n’est pas d’améliorer la perplexité ou la prédiction du prochain jeton, mais de créer des modèles capables de :
- Plan leurs propres stratégies en plusieurs étapes ;
- Coordonner outils et effecteurs externes (recherche, exécution de code, bases de connaissances) ;
- Vérifier résultats intermédiaires et correction des erreurs ;
- Soutenir cohérence à travers de longs contextes et de longues chaînes d'outils.
Ce recadrage modifie à la fois l'évaluation (les critères de référence mettent l'accent sur les processus et les résultats, et non plus seulement sur la qualité du texte) et l'ingénierie (structures pour le routage des outils, le comptage des étapes, l'autocritique, etc.).
Méthodes de travail : comment fonctionnent les modèles de pensée
En pratique, K2 Thinking illustre plusieurs méthodes de travail qui caractérisent l’approche du « modèle de pensée » :
- Traces internes persistantes : Le modèle produit des étapes intermédiaires structurées (traces de raisonnement) qui sont conservées dans leur contexte et peuvent être réutilisées ou auditées ultérieurement.
- Routage dynamique des outils : En fonction de chaque étape interne, K2 décide quel outil appeler (recherche, interpréteur de code, navigateur Web) et à quel moment l'appeler.
- Mise à l'échelle au moment du test : Lors de l'inférence, le système peut étendre sa « profondeur de réflexion » (davantage de jetons de raisonnement internes) et augmenter le nombre d'appels d'outils pour mieux explorer les solutions.
- Auto-vérification et récupération : Le modèle vérifie explicitement les résultats, effectue des tests de cohérence et replanifie en cas d'échec des vérifications.
Ces méthodes combinent l'architecture du modèle (MoE + contexte long) avec l'ingénierie système (orchestration des outils, contrôles de sécurité).
Quelles innovations technologiques permettent la pensée Kimi K2 ?
Le mécanisme de raisonnement de Kimi K2 Thinking prend en charge la pensée entrelacée et l'utilisation d'outils. La boucle de raisonnement de K2 Thinking :
- Comprendre le problème (analyse et abstraction)
- Générer un plan de raisonnement en plusieurs étapes (chaîne de plans)
- Utilisation d'outils externes (code, navigateur, moteur mathématique)
- Vérification et révision des résultats (vérifier et réviser)
- Conclure le raisonnement (conclure le raisonnement)
Ci-dessous, je présenterai trois techniques clés qui rendent possibles les boucles de raisonnement dans xx.
1) Mise à l'échelle au moment du test
Qu'est-ce que c'est: Les « lois d'échelle » traditionnelles consistent à augmenter le nombre de paramètres ou de données pendant l'entraînement. L'innovation de K2 Thinking réside dans : l'expansion dynamique du nombre de jetons (c'est-à-dire la profondeur de la réflexion) pendant la phase de raisonnement ; et l'expansion simultanée du nombre d'appels d'outils (c'est-à-dire l'étendue de l'action). Cette méthode, appelée mise à l'échelle en temps réel, repose sur le principe suivant : « Une chaîne de raisonnement plus longue + des outils plus interactifs = un bond qualitatif en matière d'intelligence. »
Pourquoi c'est important: K2 Thinking optimise explicitement cela : Moonshot montre que l’expansion des « jetons de réflexion » et du nombre/de la profondeur des appels d’outils produit des améliorations mesurables dans les benchmarks d’agents, permettant au modèle de surpasser d’autres modèles de taille similaire ou plus grande dans des scénarios FLOPs équivalents.
2) Raisonnement augmenté par des outils
Qu'est-ce que c'est: K2 Thinking a été conçu pour analyser nativement les schémas d'outils, décider de manière autonome du moment opportun pour appeler un outil et intégrer les résultats de cet outil à son flux de raisonnement continu. Moonshot a entraîné et optimisé le modèle pour entrelacer le raisonnement et les appels de fonctions, puis a stabilisé ce comportement sur des centaines d'étapes d'exécution d'outils séquentielles.
Pourquoi c'est important: Cette combinaison — analyse fiable + état interne stable + outils API — est ce qui permet au modèle d'effectuer une navigation Web, d'exécuter du code et d'orchestrer des flux de travail à plusieurs étapes dans le cadre d'une seule session.
Au sein de son architecture interne, le modèle forme une trajectoire d'exécution de « processus de pensée visualisé » : invite → jetons de raisonnement → appel d'outil → observation → raisonnement suivant → réponse finale
3) Cohérence à long terme et auto-vérification
Qu'est-ce que c'est: La cohérence à long terme désigne la capacité du modèle à maintenir un plan et un état interne cohérents sur de nombreuses étapes et dans des contextes très longs. L'auto-vérification signifie que le modèle vérifie proactivement ses résultats intermédiaires et relance ou corrige les étapes en cas d'échec de la vérification. Les tâches longues entraînent souvent une dérive ou des anomalies dans le modèle. K2 Thinking remédie à ce problème grâce à plusieurs techniques : des fenêtres de contexte très longues (256 000), des stratégies d'entraînement qui préservent l'état au cours de longues séquences de cohérence de tâche, et des modèles de fidélité/jugement explicites au niveau de la phrase pour détecter les affirmations non étayées.
Pourquoi c'est important: Le mécanisme de « mémoire de raisonnement récurrent » assure la persistance de l’état de raisonnement, lui conférant une « stabilité de la pensée » et une « auto-supervision contextuelle » comparables à celles de l’humain. Lorsque les tâches s’étendent sur de nombreuses étapes (projets de recherche, tâches de codage multi-fichiers, longs processus éditoriaux, etc.), il devient essentiel de maintenir un fil conducteur cohérent. L’auto-vérification réduit les erreurs silencieuses : au lieu de renvoyer une réponse plausible mais incorrecte, le modèle peut détecter les incohérences et consulter à nouveau les outils ou revoir sa stratégie.
capacités:
- Cohérence contextuelle : maintient la continuité sémantique sur plus de 10 000 jetons ;
- Détection et restauration des erreurs : identifie et corrige les écarts logiques dans les premiers processus de réflexion ;
- Boucle d'auto-vérification : vérifie automatiquement la pertinence de la réponse une fois le raisonnement terminé ;
- Fusion de raisonnements multi-chemins : sélectionne le chemin optimal parmi plusieurs chaînes logiques.
Quelles sont les quatre capacités fondamentales de la pensée K2 ?
Raisonnement profond et structuré
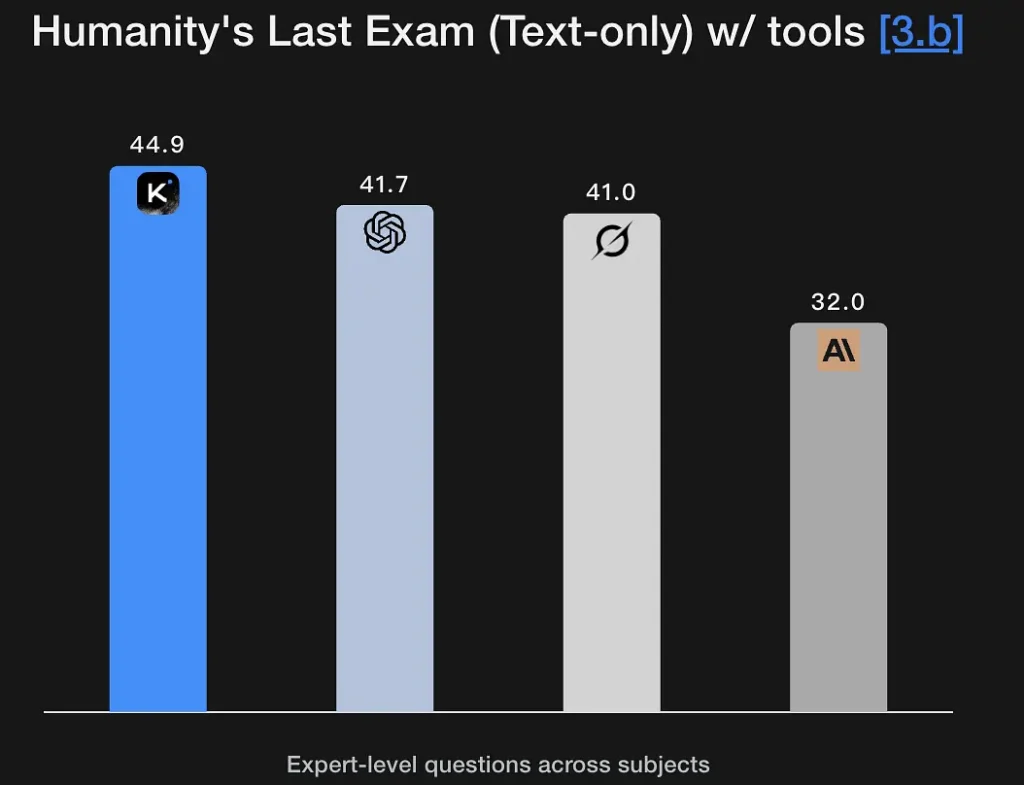
K2 Thinking est conçu pour générer des raisonnements explicites et multi-étapes et les exploiter afin de parvenir à des conclusions robustes. Le modèle obtient d'excellents résultats aux tests de mathématiques et de raisonnement rigoureux (GSM8K, AIME, tests de type OIM) et démontre sa capacité à maintenir la cohérence du raisonnement sur de longues séquences – une condition essentielle à la résolution de problèmes de niveau recherche. Son excellent score au test Humanity's Last Exam (44.9 %) témoigne de ses capacités d'analyse de haut niveau. Il peut extraire des cadres logiques à partir de descriptions sémantiques floues et générer des graphes de raisonnement.
Caractéristiques principales:
- Prend en charge le raisonnement symbolique : comprend et utilise les structures mathématiques, logiques et de programmation.
- Possède des capacités de vérification d'hypothèses : peut proposer et vérifier spontanément des hypothèses.
- Peut effectuer une décomposition de problèmes en plusieurs étapes : décompose les objectifs complexes en plusieurs sous-tâches.
Recherche d'agents
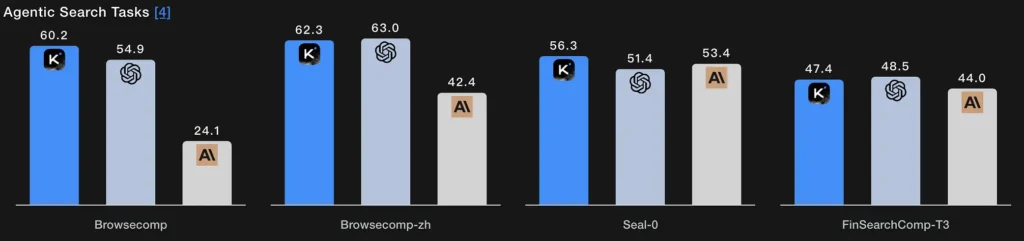
Au lieu d'une simple requête de récupération, la recherche automatisée permet au modèle de planifier une stratégie de recherche (définir les éléments à rechercher), de l'exécuter par des appels Web/outils répétés, de synthétiser les résultats obtenus et d'affiner la requête. Les scores BrowseComp et Seal-0 de K2 Thinking, obtenus avec l'outil correspondant, témoignent de ses excellentes performances ; le modèle est conçu spécifiquement pour gérer des recherches Web itératives avec une planification dynamique.
Essence technique :
- Le module de recherche et le modèle de langage forment une boucle fermée : génération de requêtes → récupération de pages Web → filtrage sémantique → fusion du raisonnement.
- Le modèle peut adapter sa stratégie de recherche de manière adaptative, par exemple en recherchant d'abord les définitions, puis les données, et enfin en vérifiant les hypothèses.
- Il s'agit essentiellement d'une intelligence composite de « recherche d'informations + compréhension + argumentation ».
Codage agentique
Il s'agit de la capacité à écrire, exécuter, tester et itérer K2 Thinking intègre le code dans une boucle de raisonnement. Il affiche des résultats compétitifs lors des tests de programmation en direct et de vérification de code, prend en charge les chaînes d'outils Python et peut exécuter des boucles de débogage multi-étapes en appelant un environnement isolé, en lisant les erreurs et en corrigeant le code par itérations successives. Ses scores EvalPlus/LiveCodeBench témoignent de ces atouts. Avec un score de 71.3 % au test SWE-Bench Verified, il est capable de réaliser correctement plus de 70 % des tâches de réparation logicielle réelles.
Il démontre également des performances stables dans l'environnement de compétition LiveCodeBench V6, mettant en valeur ses capacités d'implémentation et d'optimisation d'algorithmes.

Essence technique :
- Il adopte un processus de « analyse sémantique + refactorisation au niveau de l’AST + vérification automatique » ;
- L'exécution et le test du code sont réalisés grâce à des appels d'outils au niveau de la couche d'exécution ;
- Il permet un développement automatisé en boucle fermée, depuis la compréhension du code → le diagnostic des erreurs → la génération de correctifs → la vérification du succès.
Écriture agentique
Au-delà de la prose créative, l'écriture participative consiste en une production documentaire structurée et orientée vers un objectif précis, pouvant nécessiter des recherches externes, des citations, la création de tableaux et un processus d'amélioration itératif (par exemple : rédaction d'une ébauche → vérification des faits → révision). La capacité de K2 Thinking à gérer un contexte étendu et à orchestrer ses outils le rend particulièrement adapté aux flux de travail d'écriture en plusieurs étapes (notes de recherche, synthèses réglementaires, contenus à chapitres multiples). Les excellents taux de réussite du modèle aux tests de type Arena et aux indicateurs d'écriture de textes longs confirment cette affirmation.
Essence technique :
- Génère automatiquement des segments de texte grâce à une planification de la pensée automatisée ;
- Contrôle en interne la logique du texte grâce à des jetons de raisonnement ;
- Peut invoquer simultanément des outils tels que la recherche, le calcul et la génération de graphiques pour réaliser une « écriture multimodale ».
Comment pouvez-vous utiliser la pensée K2 aujourd'hui ?
Modes d'accès
K2 Thinking est disponible en version open source (poids et points de contrôle du modèle) et via des plateformes et des hubs communautaires (Hugging Face, plateforme Moonshot). Vous pouvez l'héberger vous-même si vous disposez d'une puissance de calcul suffisante, ou utiliser… API CometL'API/interface utilisateur hébergée de permet une prise en main plus rapide. Elle documente également reasoning_content champ qui expose les jetons de pensée internes à l'appelant lorsqu'il est activé.
Conseils pratiques d'utilisation
- Commencez par des éléments constitutifs agentsCommencez par exposer un petit ensemble d'outils déterministes (recherche, environnement de test Python et base de données de faits fiable). Fournissez des schémas d'outils clairs afin que le modèle puisse analyser et valider les appels.
- Optimiser le calcul en temps de testPour la résolution de problèmes complexes, prévoyez un temps de réflexion plus long et davantage d'itérations sur les outils ; mesurez l'amélioration de la qualité par rapport à la latence et au coût. Moonshot préconise l'optimisation du temps de test comme levier principal.
- **Utilisez les modes INT4 pour optimiser les coûts.**K2 Thinking prend en charge la quantification INT4, ce qui offre des gains de vitesse significatifs ; mais il est important de valider le comportement dans les cas limites sur vos tâches.
- Contenu du raisonnement de surface soigneusementExposer les chaînes internes peut faciliter le débogage, mais augmente également le risque d'erreurs brutes dans le modèle. Traitez le raisonnement interne comme diagnostique Non officiel ; à associer à une vérification automatisée.
Conclusion
Kimi K2 Thinking est une réponse délibérément conçue pour la prochaine ère de l'IA : non seulement des modèles plus grands, mais agents qui pensent, agissent et vérifientK2 Thinking combine la mise à l'échelle MoE, les stratégies de calcul en temps réel, l'inférence native à faible précision et l'orchestration explicite des outils pour permettre une résolution de problèmes multi-étapes et durable. Pour les équipes qui ont besoin de résoudre des problèmes en plusieurs étapes et qui possèdent la rigueur technique nécessaire pour intégrer, tester et superviser les systèmes multi-agents, K2 Thinking représente une avancée majeure et concrète, ainsi qu'un test de résistance important quant à la manière dont l'industrie et la société encadreront une IA de plus en plus performante et orientée vers l'action.
Les développeurs peuvent accéder API de réflexion Kimi K2 via CometAPI, la dernière version du modèle est constamment mis à jour avec le site officiel. Pour commencer, explorez les capacités du modèle dans la section cour de récréation et consultez le Guide de l'API Pour des instructions détaillées, veuillez vous connecter à CometAPI et obtenir la clé API avant d'y accéder. API Comet proposer un prix bien inférieur au prix officiel pour vous aider à vous intégrer.
Prêt à partir ?→ Inscrivez-vous à CometAPI dès aujourd'hui !
Si vous souhaitez connaître plus de conseils, de guides et d'actualités sur l'IA, suivez-nous sur VK, X et Discord!