

Le 17 juin 2025, MiniMax (également connu sous le nom de Xiyu Technology), leader de l'IA basé à Shanghai, a officiellement lancé MiniMax-M1 (ci-après « M1 »), le premier modèle de raisonnement à attention hybride, ouvert et à grande échelle au monde. Combinant une architecture Mixture-of-Experts (MoE) avec un mécanisme innovant Lightning Attention, M1 atteint des performances de pointe dans les tâches axées sur la productivité, rivalisant avec les meilleurs systèmes propriétaires tout en maintenant une rentabilité inégalée. Dans cet article détaillé, nous explorons ce qu'est M1, son fonctionnement, ses caractéristiques et donnons des conseils pratiques pour accéder au modèle et l'utiliser.
Qu'est-ce que MiniMax-M1 ?
MiniMax-M1 représente l'aboutissement des recherches de MiniMaxAI sur les mécanismes d'attention évolutifs et efficaces. S'appuyant sur la base MiniMax-Text-01, l'itération M1 intègre l'attention éclair à un framework MoE pour atteindre une efficacité sans précédent, tant lors de l'apprentissage que de l'inférence. Cette combinaison permet au modèle de maintenir des performances élevées même lors du traitement de séquences extrêmement longues, une exigence essentielle pour les tâches impliquant des bases de code volumineuses, des documents juridiques ou de la littérature scientifique.
Architecture de base et paramétrisation
À la base, MiniMax-M1 s'appuie sur un système MoE hybride qui achemine dynamiquement les jetons via un sous-ensemble de sous-réseaux experts. Bien que le modèle comprenne 456 milliards de paramètres au total, seuls 45.9 milliards sont activés pour chaque jeton, optimisant ainsi l'utilisation des ressources. Cette conception s'inspire des précédentes implémentations MoE, mais affine la logique de routage afin de minimiser la surcharge de communication entre les GPU lors de l'inférence distribuée.
Attention éclair et support de contexte long
Une caractéristique essentielle du MiniMax-M1 est son mécanisme d'attention éclair, qui réduit considérablement la charge de calcul de l'auto-attention pour les séquences longues. En approximant les matrices d'attention par une combinaison de noyaux locaux et globaux, le modèle réduit les FLOP jusqu'à 75 % par rapport aux transformateurs traditionnels lors du traitement de séquences de 100 XNUMX jetons. Cette efficacité accélère non seulement l'inférence, mais ouvre également la voie à la gestion de fenêtres contextuelles allant jusqu'à un million de jetons sans exigences matérielles prohibitives.
Comment MiniMax-M1 atteint-il l'efficacité de calcul ?
Les gains d'efficacité du MiniMax-M1 proviennent de deux innovations majeures : son architecture hybride « Mixture-of-Experts » et le nouvel algorithme d'apprentissage par renforcement CISPO utilisé pendant l'entraînement. Ensemble, ces éléments réduisent le temps d'entraînement et le coût d'inférence, permettant une expérimentation et un déploiement rapides.
Routage hybride avec mélange d'experts
Le composant MoE utilise 32 sous-réseaux d'experts, chacun spécialisé dans différents aspects du raisonnement ou dans des tâches spécifiques à un domaine. Lors de l'inférence, un mécanisme de sélection automatique sélectionne dynamiquement les experts les plus pertinents pour chaque jeton, activant uniquement les sous-réseaux nécessaires au traitement de l'entrée. Cette activation sélective réduit considérablement les calculs redondants et les besoins en bande passante mémoire, offrant au MiniMax-M1 un avantage substantiel en termes de rentabilité par rapport aux modèles de transformateurs monolithiques.
CISPO : Un nouvel algorithme d'apprentissage par renforcement
Pour améliorer l'efficacité de l'apprentissage, MiniMaxAI a développé CISPO (Clipped Importance Sampling with Partial Overrides), un algorithme d'apprentissage par renforcement qui remplace les mises à jour de pondération au niveau des jetons par un découpage basé sur l'échantillonnage d'importance. CISPO atténue les problèmes d'explosion de pondération fréquents dans les configurations d'apprentissage par renforcement à grande échelle, accélère la convergence et garantit une amélioration stable des politiques sur divers benchmarks. Ainsi, l'apprentissage par renforcement complet du MiniMax-M1 sur 512 GPU H800 s'effectue en seulement trois semaines, pour un coût d'environ 534,700 4 $, soit une fraction du coût rapporté pour des exécutions d'apprentissage GPT-XNUMX comparables.
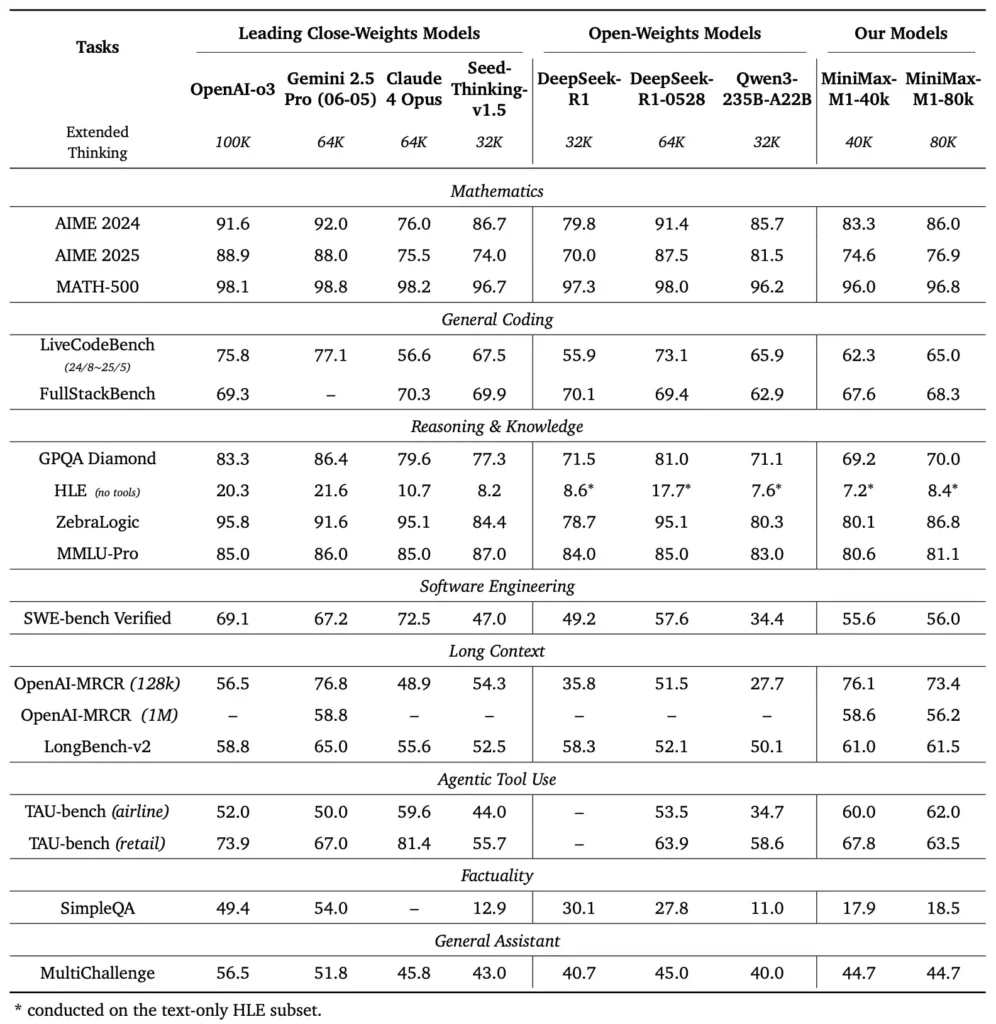
Quels sont les critères de performance du MiniMax-M1 ?
MiniMax-M1 excelle dans une variété de tests standards et spécifiques à un domaine, démontrant ses prouesses dans la gestion du raisonnement à long contexte, la résolution de problèmes mathématiques et la génération de code.
Tâches de raisonnement à long contexte
Lors de tests approfondis de compréhension de documents, MiniMax-M1 traite des fenêtres contextuelles allant jusqu'à 1,000,000 1 100 de jetons, surpassant ainsi DeepSeek-RXNUMX d'un facteur huit en termes de longueur de contexte maximale et réduisant de moitié les besoins de calcul pour les séquences de XNUMX XNUMX jetons. Lors de benchmarks comme l'évaluation contextuelle étendue NarrativeQA, le modèle atteint des scores de compréhension de pointe, grâce à sa capacité d'attention éclair à capturer efficacement les dépendances locales et globales.
Ingénierie logicielle et utilisation des outils
MiniMax-M1 a été spécifiquement entraîné sur des environnements d'ingénierie logicielle sandboxés utilisant le RL à grande échelle, ce qui lui permet de générer et de déboguer du code avec une précision remarquable. Lors de tests de codage tels que HumanEval et MBPP, le modèle atteint des taux de réussite comparables, voire supérieurs, à ceux de Qwen3-235B et DeepSeek-R1, notamment pour les bases de code multifichiers et les tâches nécessitant le croisement de longs segments de code. De plus, les premières démonstrations de MiniMaxAI démontrent la capacité du modèle à s'intégrer aux outils de développement, de la génération de pipelines CI/CD aux workflows d'auto-documentation.
Comment les développeurs peuvent-ils accéder à MiniMax-M1 ?
Afin de favoriser une adoption généralisée, MiniMaxAI a mis MiniMax-M1 à disposition gratuitement sous forme de modèle à pondération ouverte. Les développeurs peuvent accéder aux points de contrôle pré-entraînés, aux pondérations des modèles et au code d'inférence via le dépôt GitHub officiel.
Version Open-weight sur GitHub
MiniMaxAI a publié les fichiers du modèle MiniMax-M1 et les scripts associés sous une licence open source permissive sur GitHub. Les utilisateurs intéressés peuvent cloner le dépôt à l'adresse https://github.com/MiniMax-AI/MiniMax-M1, qui héberge des points de contrôle pour les variantes de budget de 40 80 et XNUMX XNUMX jetons, ainsi que des exemples d'intégration pour des frameworks de ML courants tels que PyTorch et TensorFlow.
Points de terminaison API et intégration cloud
Au-delà du déploiement local, MiniMaxAI s'est associé à des fournisseurs cloud majeurs pour proposer des services d'API managés. Grâce à ces partenariats, les développeurs peuvent appeler MiniMax-M1 via des points de terminaison RESTful, grâce à des SDK disponibles pour Python, JavaScript et Java. Les API incluent des paramètres configurables pour la longueur du contexte, les seuils de routage expert et les budgets de jetons, permettant aux utilisateurs d'adapter les performances à leurs cas d'utilisation tout en surveillant la consommation de calcul en temps réel.
Comment intégrer et utiliser MiniMax-M1 dans des applications réelles ?
Pour exploiter les capacités de MiniMax-M1, il est nécessaire de comprendre ses modèles d'API, ses meilleures pratiques pour les invites à contexte long et ses stratégies d'orchestration des outils.
Exemple d'utilisation de base de l'API
Un appel d'API classique consiste à envoyer une charge utile JSON contenant le texte d'entrée et les options de configuration. Par exemple :
POST /v1/minimax-m1/generate
{
"input": "Analyze the following 500K token legal document and summarize the key obligations:",
"max_output_tokens": 1024,
"context_window": 500000,
"expert_threshold": 0.6
}
La réponse renvoie un JSON structuré avec du texte généré, des statistiques d'utilisation de jetons et des journaux de routage, permettant une surveillance précise des activations d'experts.
Utilisation des outils et agent MiniMax
En plus du modèle principal, MiniMaxAI a introduit MiniMax Agent, un framework d'agent bêta capable d'appeler des outils externes, allant des environnements d'exécution de code aux scrapers web, en arrière-plan. Les développeurs peuvent instancier une session d'agent qui enchaîne le raisonnement du modèle à l'invocation d'outils, par exemple pour récupérer des données en temps réel, effectuer des calculs ou mettre à jour des bases de données. Ce paradigme d'agent simplifie le développement d'applications de bout en bout, permettant à MiniMax-M1 de jouer le rôle d'orchestrateur dans des workflows complexes.
Bonnes pratiques et pièges
- Ingénierie rapide pour les contextes longs:Décomposez les entrées en segments cohérents, intégrez des résumés à des intervalles logiques et utilisez des stratégies « résumer puis raisonner » pour maintenir la concentration du modèle.
- Compromis entre calcul et performances:Expérimentez avec des seuils d'experts inférieurs ou des budgets de réflexion réduits (par exemple, la variante 40K) pour les applications sensibles à la latence.
- Suivi et gouvernance:Utilisez les journaux de routage et les statistiques de jetons pour auditer l'utilisation des experts et garantir la conformité avec les budgets de coûts, en particulier dans les environnements de production.
En suivant ces directives, les développeurs peuvent exploiter les atouts de MiniMax-M1 (gestion de contexte étendue et raisonnement efficace) tout en atténuant les risques associés aux déploiements de modèles à grande échelle.
Comment utiliser MiniMax-M1 ?
Une fois installé, M1 peut être invoqué via de simples scripts Python ou des blocs-notes interactifs.
À quoi ressemble un script d’inférence de base ?
from minimax_m1 import MiniMaxM1Tokenizer, MiniMaxM1ForCausalLM
tokenizer = MiniMaxM1Tokenizer.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
model = MiniMaxM1ForCausalLM.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
inputs = tokenizer("Translate the following paragraph to French: ...", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs))
Cet exemple invoque la variante à budget de 40 XNUMX $ ; en passant à "MiniMax-AI/MiniMax-M1-80k" débloque l'intégralité du budget de raisonnement de 80 6 ().
Comment gérez-vous les contextes ultra-longs ?
Pour les entrées dépassant les tailles de tampon standard, M1 prend en charge la tokenisation en continu. Utilisez le stream=True indicateur dans le tokenizer pour alimenter les jetons en morceaux et exploiter l'inférence de redémarrage du point de contrôle pour maintenir les performances sur des séquences de millions de jetons.
Comment pouvez-vous affiner ou adapter M1 ?
Bien que les points de contrôle de base soient suffisants pour la plupart des tâches, les chercheurs peuvent affiner le RL grâce au code CISPO inclus dans le référentiel. En fournissant des fonctions de récompense personnalisées, allant de l'exactitude du code à la fidélité sémantique, les praticiens peuvent adapter M1 aux flux de travail spécifiques à leur domaine.
Conclusion
MiniMax-M1 se distingue comme un modèle d'IA révolutionnaire, repoussant les limites de la compréhension et du raisonnement du langage à contexte large. Grâce à son architecture MoE hybride, son mécanisme d'attention éclair et son programme d'entraînement soutenu par CISPO, ce modèle offre des performances élevées pour des tâches allant de l'analyse juridique à l'ingénierie logicielle, tout en réduisant considérablement les coûts de calcul. Grâce à sa version ouverte et à ses offres d'API cloud, MiniMax-M1 est accessible à un large éventail de développeurs et d'organisations désireux de créer des applications d'IA de nouvelle génération. Alors que la communauté de l'IA continue d'explorer le potentiel des modèles à contexte large, les innovations de MiniMax-M1 sont appelées à influencer la recherche et le développement de produits futurs dans l'ensemble du secteur.
Pour commencer
CometAPI fournit une interface REST unifiée qui regroupe des centaines de modèles d'IA, dont la famille ChatGPT, sous un point de terminaison cohérent, avec gestion intégrée des clés API, des quotas d'utilisation et des tableaux de bord de facturation. Plus besoin de jongler avec plusieurs URL et identifiants de fournisseurs.
Pour commencer, explorez les capacités des modèles dans le cour de récréation et consultez le Guide de l'API Pour des instructions détaillées, veuillez vous connecter à CometAPI et obtenir la clé API avant d'y accéder.
La dernière intégration de l'API MiniMax‑M1 apparaîtra bientôt sur CometAPI, alors restez à l'écoute ! Pendant que nous finalisons le téléchargement du modèle MiniMax‑M1, explorez nos autres modèles sur le Page des modèles ou essayez-les dans le Aire de jeux IA. Le dernier modèle de MiniMax dans CometAPI est API Minimax ABAB7-Preview et API MiniMax Vidéo-01 ,se référer à :
