

Dans un paysage dominé par la philosophie du « scale-at-all-costs » — où des modèles comme Flux.2 et Hunyuan-Image-3.0 portent le nombre de paramètres dans la plage massive de 30B à 80B — un nouveau prétendant est apparu pour bousculer le statu quo. Z-Image, développé par le Tongyi Lab d’Alibaba, a officiellement été lancé, déjouant les attentes avec une architecture légère de 6 milliards de paramètres qui rivalise avec la qualité de sortie des géants du secteur tout en tournant sur du matériel grand public.
Publié fin 2025, Z-Image (et sa variante ultra-rapide Z-Image-Turbo) a immédiatement captivé la communauté IA, dépassant 500 000 téléchargements dans les 24 heures suivant ses débuts. En produisant des images photoréalistes en seulement 8 étapes d’inférence, Z-Image n’est pas qu’un autre modèle ; c’est une force de démocratisation de l’IA générative, permettant une création haute fidélité sur des ordinateurs portables qui suffoqueraient avec ses concurrents.
Qu’est-ce que Z-Image ?
Z-Image est un nouveau modèle fondation open source de génération d’images développé par l’équipe de recherche Tongyi-MAI / Alibaba Tongyi Lab. Il s’agit d’un modèle génératif de 6 milliards de paramètres, construit sur une architecture novatrice de Transformer de diffusion à flux unique et évolutif (S3-DiT) qui concatène les tokens de texte, les tokens sémantiques visuels et les tokens VAE dans un seul flux de traitement. L’objectif de conception est explicite : offrir un photoréalisme de premier plan et une forte conformité aux instructions tout en réduisant drastiquement le coût d’inférence et en permettant une utilisation pratique sur du matériel grand public. Le projet Z-Image publie le code, les poids du modèle et une démo en ligne sous licence Apache-2.0.
Z-Image est livré en plusieurs variantes. La version la plus discutée est Z-Image-Turbo — une version distillée à peu d’étapes, optimisée pour le déploiement — ainsi que la variante non distillée Z-Image-Base (checkpoint de base, mieux adaptée au fine-tuning) et Z-Image-Edit (ajustée par instructions pour l’édition d’images).
L’avantage « Turbo » : inférence en 8 étapes
La variante phare, Z-Image-Turbo, utilise une technique de distillation progressive appelée Decoupled-DMD (Distribution Matching Distillation). Cela permet au modèle de compresser le processus de génération de la norme 30-50 étapes à seulement 8 étapes.
Résultat : des temps de génération sous la seconde sur des GPU d’entreprise (H800) et une performance pratiquement en temps réel sur des cartes grand public (RTX 4090), sans l’aspect « plastique » ou « délavé » typique d’autres modèles turbo/lightning.
4 fonctionnalités clés de Z-Image
Z-Image regorge de fonctionnalités qui s’adressent à la fois aux développeurs techniques et aux professionnels créatifs.
1. Photoréalisme et esthétique incomparables
Bien qu’il ne possède que 6 milliards de paramètres, Z-Image produit des images d’une clarté stupéfiante. Il excelle en :
- Texture de peau : Reproduction des pores, imperfections et éclairage naturel sur des sujets humains.
- Physique des matériaux : Rendu précis du verre, du métal et des tissus.
- Éclairage : Gestion supérieure des éclairages cinématographiques et volumétriques par rapport à SDXL.
2. Rendu natif du texte bilingue
L’un des principaux points de douleur de la génération d’images par IA a été le rendu du texte. Z-Image résout ce problème avec une prise en charge native de l’anglais et du chinois.
- Il peut générer des affiches, logos et enseignes complexes avec une orthographe et une calligraphie correctes dans les deux langues, une fonctionnalité souvent absente des modèles centrés sur l’Occident.
3. Z-Image-Edit : édition basée sur des instructions
Parallèlement au modèle de base, l’équipe a publié Z-Image-Edit. Cette variante est fine-tunée pour les tâches image-vers-image, permettant aux utilisateurs de modifier des images existantes à l’aide d’instructions en langage naturel (par exemple, « Faire sourire la personne », « Changer l’arrière-plan en une montagne enneigée »). Elle maintient une forte cohérence d’identité et d’éclairage pendant ces transformations.
4. Accessibilité sur matériel grand public
- Efficacité VRAM : Fonctionne confortablement sur 6GB de VRAM (avec quantification) à 16GB de VRAM (pleine précision).
- Exécution locale : Prend entièrement en charge le déploiement local via ComfyUI et
diffusers, libérant les utilisateurs des dépendances cloud.
Comment Z-Image fonctionne-t-il ?
Transformer de diffusion à flux unique (S3-DiT)
Z-Image s’écarte des conceptions classiques à double flux (encodeurs/flux de texte et d’image séparés) et concatène à la place les tokens de texte, les tokens VAE d’image et les tokens sémantiques visuels en une seule entrée de transformer. Cette approche à flux unique améliore l’utilisation des paramètres et simplifie l’alignement intermodal au sein de l’ossature du transformer, ce que les auteurs indiquent produire un compromis efficacité/qualité favorable pour un modèle 6B.
Decoupled-DMD et DMDR (distillation + RL)
Pour permettre une génération en peu d’étapes (8 étapes) sans la pénalité de qualité habituelle, l’équipe a développé une approche de distillation Decoupled-DMD. La technique sépare l’augmentation CFG (classifier-free guidance) de l’appariement de distribution, permettant une optimisation indépendante de chacune. Ils appliquent ensuite une étape de reinforcement learning post-entraînement (DMDR) pour affiner l’alignement sémantique et l’esthétique. Ensemble, ces éléments produisent Z-Image-Turbo avec beaucoup moins de NFEs que les modèles de diffusion typiques tout en conservant un réalisme élevé.
Débit d’entraînement et optimisation des coûts
Z-Image a été entraîné avec une approche d’optimisation du cycle de vie : pipelines de données sélectionnées, curriculum simplifié et choix d’implémentation sensibles à l’efficacité. Les auteurs rapportent avoir achevé l’ensemble du workflow d’entraînement en environ 314K heures GPU H800 (≈ USD $630K) — une métrique d’ingénierie explicite et reproductible qui positionne le modèle comme rentable par rapport aux alternatives très grandes (>20B).
Résultats de référence du modèle Z-Image
Z-Image-Turbo s’est classé en tête de plusieurs classements contemporains, y compris une position open source de premier plan sur le leaderboard Artificial Analysis Text-to-Image et de solides performances sur les évaluations de préférence humaine d’Alibaba AI Arena.
Mais la qualité réelle dépend également de la formulation du prompt, de la résolution, du pipeline d’upscaling et d’un post-traitement supplémentaire.
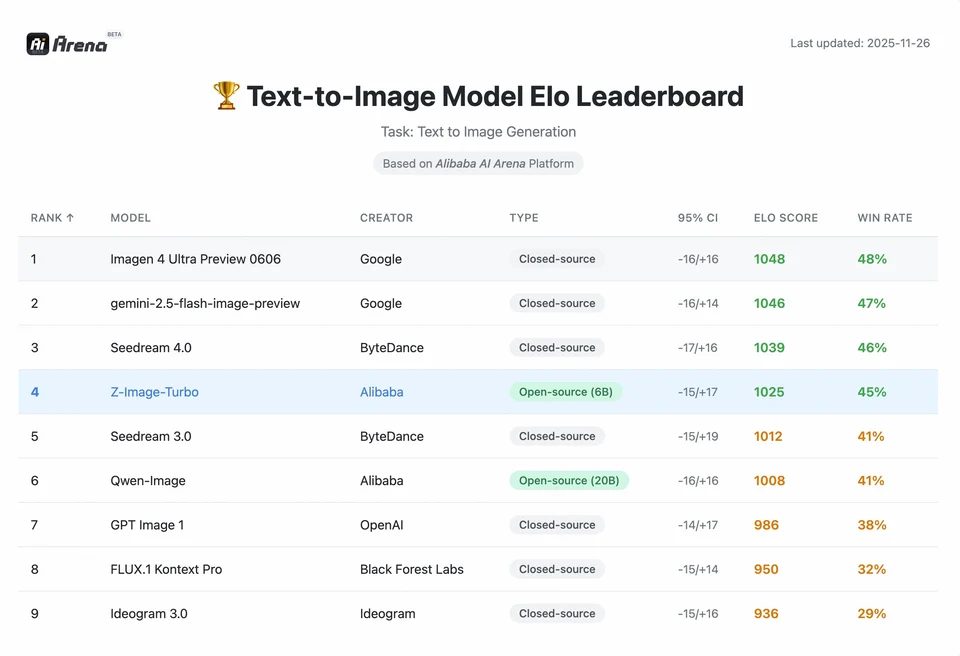
Pour comprendre l’ampleur de la réussite de Z-Image, nous devons examiner les données. Ci-dessous figure une analyse comparative de Z-Image par rapport aux modèles open source et propriétaires leaders.
Résumé comparatif des benchmarks
| Fonctionnalité / Métrique | Z-Image-Turbo | Flux.2 (Dev/Pro) | SDXL Turbo | Hunyuan-Image |
|---|---|---|---|---|
| Architecture | S3-DiT (Flux unique) | MM-DiT (Flux double) | U-Net | Transformer de diffusion |
| Paramètres | 6 milliards | 12B / 32B | 2.6B / 6.6B | ~30B+ |
| Étapes d’inférence | 8 étapes | 25 - 50 étapes | 1 - 4 étapes | 30 - 50 étapes |
| VRAM requise | ~6GB - 12GB | 24GB+ | ~8GB | 24GB+ |
| Rendu du texte | Élevé (EN + CN) | Élevé (EN) | Modéré (EN) | Élevé (CN + EN) |
| Vitesse de génération (4090) | ~1.5 - 3.0 secondes | ~15 - 30 secondes | ~0.5 secondes | ~20 secondes |
| Score de photoréalisme | 9.2/10 | 9.5/10 | 7.5/10 | 9.0/10 |
| Licence | Apache 2.0 | Non-Commercial (Dev) | OpenRAIL | Custom |
Analyse des données et enseignements de performance
- Vitesse vs qualité : Bien que SDXL Turbo soit plus rapide (1 étape), sa qualité se dégrade de manière significative sur des prompts complexes. Z-Image-Turbo atteint le « sweet spot » à 8 étapes, égalant la qualité de Flux.2 tout en étant 5x à 10x plus rapide.
- Démocratisation matérielle : Flux.2, bien que puissant, est de fait réservé aux cartes 24GB VRAM (RTX 3090/4090) pour des performances raisonnables. Z-Image permet aux utilisateurs avec des cartes milieu de gamme (RTX 3060/4060) de générer des images professionnelles 1024x1024 en local.
Comment les développeurs peuvent-ils accéder à Z-Image et l’utiliser ?
Il existe trois approches typiques :
- Hébergé / SaaS (interface web ou API) : Utiliser des services comme z-image.ai ou d’autres fournisseurs qui déploient le modèle et exposent une interface web ou une API payante pour la génération d’images. C’est la voie la plus rapide pour expérimenter sans configuration locale.
- Pipelines Hugging Face + diffusers : La bibliothèque
diffusersde Hugging Face inclutZImagePipelineetZImageImg2ImgPipelineet fournit les workflowsfrom_pretrained(...).to("cuda")typiques. C’est la voie recommandée pour les développeurs Python qui souhaitent une intégration simple et des exemples reproductibles. - Inférence native locale depuis le dépôt GitHub : Le dépôt Tongyi-MAI inclut des scripts d’inférence natifs, des options d’optimisation (FlashAttention, compilation, offload CPU) et des instructions pour installer
diffusersdepuis la source pour la dernière intégration. Cette voie est utile pour les chercheurs et les équipes souhaitant un contrôle total ou exécuter un entraînement/fine-tuning personnalisé.
À quoi ressemble un exemple Python minimal ?
Ci-dessous se trouve un extrait Python concis utilisant Hugging Face diffusers qui démontre la génération texte-vers-image avec Z-Image-Turbo.
# minimal_zimage_turbo.pyimport torchfrom diffusers import ZImagePipelinedef generate(prompt, output_path="zimage_output.png", height=1024, width=1024, steps=9, guidance_scale=0.0, seed=42): # Use bfloat16 where supported for efficiency on modern GPUs pipe = ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) pipe.to("cuda") generator = torch.Generator("cuda").manual_seed(seed) image = pipe( prompt=prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=guidance_scale, generator=generator, ).images[0] image.save(output_path) print(f"Saved: {output_path}")if __name__ == "__main__": generate("A cinematic portrait of a robot painter, studio lighting, ultra detailed")
Notes : les valeurs par défaut et les réglages recommandés de guidance_scale diffèrent pour les modèles Turbo ; la documentation suggère que le guidage peut être faible ou nul pour Turbo selon le comportement visé.
Comment exécuter l’image-vers-image (édition) avec Z-Image ?
ZImageImg2ImgPipeline prend en charge l’édition d’images. Exemple :
from diffusers import ZImageImg2ImgPipelinefrom diffusers.utils import load_imageimport torchpipe = ZImageImg2ImgPipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16)pipe.to("cuda")init_image = load_image("sketch.jpg").resize((1024, 1024))prompt = "Turn this sketch into a fantasy river valley with vibrant colors"result = pipe(prompt, image=init_image, strength=0.6, num_inference_steps=9, guidance_scale=0.0, generator=torch.Generator("cuda").manual_seed(123))result.images[0].save("zimage_img2img.png")
Cela reflète les schémas d’utilisation officiels et convient aux tâches d’édition créative et d’inpainting.
Comment aborder les prompts et le guidage ?
- Soyez explicite sur la structure : Pour des scènes complexes, structurez les prompts pour inclure la composition de la scène, l’objet principal, la caméra/l’objectif, l’éclairage, l’ambiance et les éléments textuels éventuels. Z-Image bénéficie de prompts détaillés et gère bien les indications positionnelles/narratives.
- Ajustez soigneusement
guidance_scale: Les modèles Turbo peuvent recommander des valeurs de guidage plus faibles ; l’expérimentation est nécessaire. Pour de nombreux workflows Turbo,guidance_scale=0.0–1.0avec une seed et un nombre d’étapes fixe produit des résultats cohérents. - Utilisez l’image-vers-image pour des modifications contrôlées : Lorsque vous devez préserver la composition mais changer le style/la couleur/les objets, partez d’une image initiale et utilisez
strengthpour contrôler l’ampleur du changement.
Meilleurs cas d’usage et bonnes pratiques
1. Prototypage rapide et storyboarding
Cas d’usage : Les réalisateurs et les concepteurs de jeux doivent visualiser des scènes instantanément.
Pourquoi Z-Image ? Avec une génération en moins de 3 secondes, les créateurs peuvent itérer des centaines de concepts en une session, en affinant l’éclairage et la composition en temps réel sans attendre des minutes pour un rendu.
2. E-commerce et publicité
Cas d’usage : Générer des arrière-plans produits ou des scènes lifestyle pour des articles.
Bonne pratique : Utilisez Z-Image-Edit.
Téléchargez une photo brute du produit et utilisez un prompt d’instruction comme « Placer ce flacon de parfum sur une table en bois dans un jardin baigné de soleil. » Le modèle préserve l’intégrité du produit tout en halluciant un arrière-plan photoréaliste.
3. Création de contenu bilingue
Cas d’usage : Campagnes marketing globales nécessitant des ressources pour les marchés occidentaux et asiatiques.
Bonne pratique : Exploitez la capacité de rendu du texte.
- Prompt : « Une enseigne au néon indiquant ‘OPEN’ et ‘营业中’ qui brille dans une ruelle sombre. »
- Z-Image rendra correctement les caractères anglais et chinois, un exploit que la plupart des autres modèles n’atteignent pas.
4. Environnements à faibles ressources
Cas d’usage : Exécuter la génération IA sur des appareils en périphérie ou des ordinateurs portables de bureau standard.
Astuce d’optimisation : Utilisez la version quantifiée INT8 de Z-Image. Cela réduit l’utilisation de la VRAM en dessous de 6GB avec une perte de qualité négligeable, la rendant viable pour des applications locales sur des ordinateurs portables non dédiés au jeu.
En bref : qui devrait utiliser Z-Image ?
Z-Image est conçu pour les organisations et les développeurs qui veulent un photoréalisme de haute qualité avec une latence et un coût pratiques, et qui préfèrent des licences ouvertes ainsi qu’un hébergement sur site ou personnalisé. Il est particulièrement attrayant pour les équipes qui ont besoin d’itérations rapides (outillage créatif, maquettes de produits, services en temps réel) et pour les chercheurs/membres de la communauté intéressés par le fine-tuning d’un modèle d’images compact mais puissant.
CometAPI propose des modèles Grok Image également moins restreints, ainsi que des modèles comme Nano Banana Pro, GPT- image 1.5, Sora 2(Can Sora 2 generate NSFW content? How can we try it?) etc — à condition d’avoir les bons conseils et astuces NSFW pour contourner les restrictions et commencer à créer librement. Avant d’y accéder, veuillez vous assurer que vous êtes connecté à CometAPI et que vous avez obtenu la clé API. CometAPI offre un prix bien inférieur au prix officiel pour vous aider à intégrer.
Prêt à démarrer ? → Free trial for Creating !