

The Gemini 2.5 Flash-Lite API represents Google’s latest offering in its family of hybrid reasoning models, designed to deliver unparalleled cost-efficiency and ultra-low latency for high-volume, latency-sensitive applications.
Basic Information & Features
Announced in a preview release on June 17, 2025, Flash-Lite rounds out the Gemini 2.5 lineup—alongside Flash and Pro—by providing developers with an option optimized for speed, price-performance, and adaptive thinking capabilities .
You can start using Gemini 2.5 Flash-Lite by specifying “gemini-2.5-flash-lite” in your code. If you are using a preview version, you can switch to “gemini-2.5-flash-lite”, which is the same as the preview version. Google plans to remove the preview alias for Flash-Lite on August 25th.
| Stability | Model | Date |
| Stable (GA) | gemini-2.5-flash-lite | July 22, 2025 |
| Experimental Preview | gemini-2.5-flash-lite-06-17 | Availability Window: June 17 – August 25, 2025 |
| latest version | gemini-2.5-flash-lite-preview-09-2025 | 09-2025 |
- Thinking Control: Implements a dynamic thinking budget via an API parameter, with thinking disabled by default to maximize speed and reduce cost.
- Low Latency: Engineered for a fast time-to-first-token, Flash-Lite minimizes startup overhead, achieving sub-100 ms latencies on standard Google Cloud infrastructure .
- High Throughput: With capable decoding pipelines, it sustains hundreds of tokens per second, unlocking real-time user experiences in chatbots and streaming applications.
- Multimodal Support: Though optimized primarily for text, Flash-Lite also accepts images, audio, and video inputs via the Gemini API, enabling versatile use cases from document summarization to light vision tasks .
Technical Details
- Adaptive Reasoning:
Gemini 2.5 Flash-Litesupports on-demand thinking, allowing developers to allocate compute resources only when deeper reasoning is required. - Tool Integrations: Full compatibility with Gemini 2.5’s native tools, including Grounding with Google Search, Code Execution, URL Context, and Function Calling for seamless multimodal workflows.
- Model Context Protocol (MCP): Leverages Google’s MCP to fetch real-time web data, ensuring responses are up-to-date and contextually relevant.
- Deployment Options: Available through the CometAPI, Gemini API, Vertex AI, and Google AI Studio, with a preview track for early adopters to experiment and provide feedback .
Benchmark Performance of Gemini 2.5 Flash-Lite
- Latency: Achieves up to 50% lower median response times compared to Gemini 2.5 Flash, with typical sub-100 ms latencies on standard classification and summarization benchmarks.
- Throughput: Optimized for high-volume workloads, sustaining tens of thousands of requests per minute without degradation in performance.
- Price-Performance: Demonstrates a 25% reduction in cost per 1,000 tokens versus its Flash counterpart, making it the Pareto-optimal choice for cost-sensitive deployments.
- Industry Adoption: Early users report seamless integration into production pipelines, with performance metrics aligning with or exceeding initial projections .
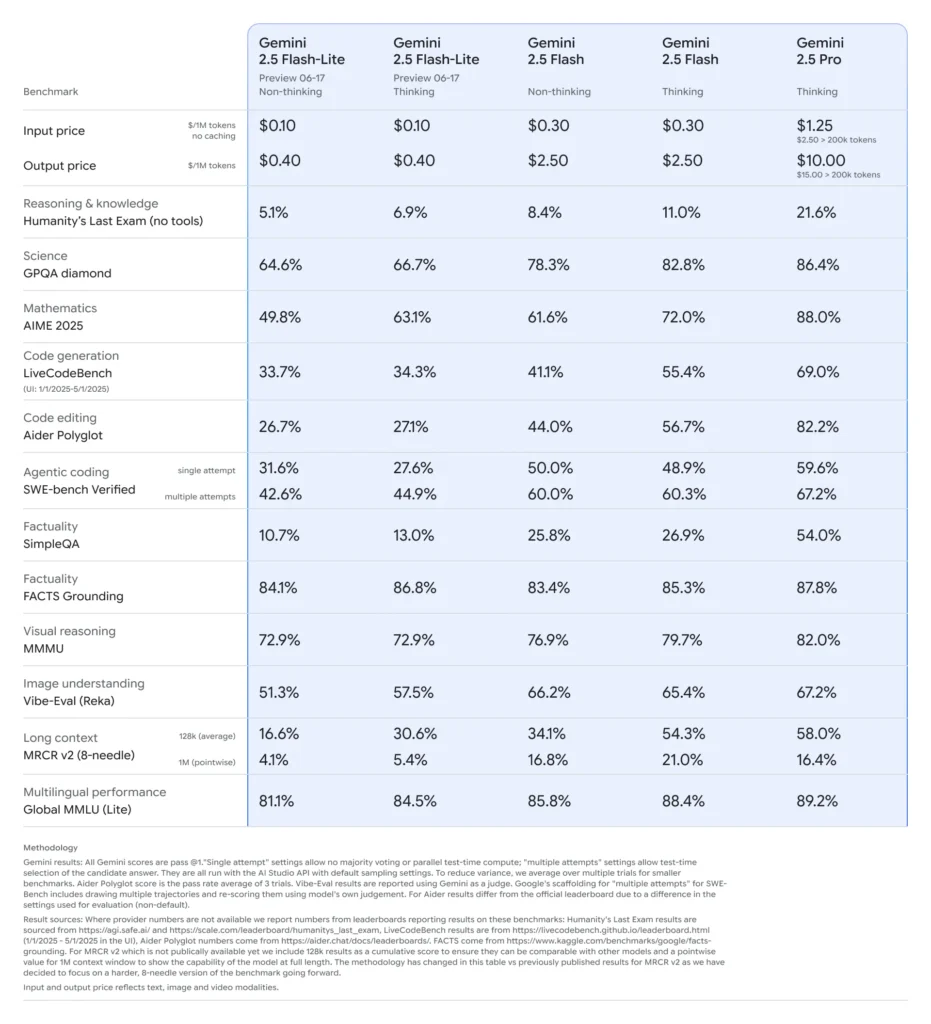
Ideal Use Cases
- High-Frequency, Low-Complexity Tasks: Automated tagging, sentiment analysis, and bulk translation
- Cost-Sensitive Pipelines: Data extraction from large document corpora, periodic batch summarization
- Edge and Mobile Scenarios: When latency is critical but resource budgets are limited
Limitations of Gemini 2.5 Flash-Lite
- Preview Status: May undergo API changes before GA; integrations should account for possible version bumps.
- No On-the-Fly Fine-Tuning: Cannot upload custom weights; rely on prompt engineering and system messages.
- Reduced Creativity: Tuned for deterministic, high-throughput tasks; less suited for open-ended generation or “creative” writing.
- Resource Ceiling: Scales linearly only up to ~16 vCPUs; beyond this, throughput gains diminish.
- Multimodal Constraints: Supports image/audio inputs but with limited fidelity; not ideal for heavy vision or audio transcription tasks.
- Context-Window Trade-Off : Although it accepts up to 1 M tokens, practical inference at that scale may see degraded throughput.
How to call Gemini 2.5 Flash-Lite API from CometAPI
Gemini 2.5 Flash-Lite API Pricing in CometAPI,20% off the official price:
- Input Tokens: $0.08/ M tokens
- Output Tokens: $0.32/ M tokens
Required Steps
- Log in to cometapi.com. If you are not our user yet, please register first
- Get the access credential API key of the interface. Click “Add Token” at the API token in the personal center, get the token key: sk-xxxxx and submit.
- Get the url of this site: https://api.cometapi.com/
Useage Methods
- Select the “
gemini-2.5-flash-lite” endpoint to send the API request and set the request body. The request method and request body are obtained from our website API doc. Our website also provides Apifox test for your convenience. - Replace <YOUR_AIMLAPI_KEY> with your actual CometAPI key from your account.
- Insert your question or request into the content field—this is what the model will respond to.
- . Process the API response to get the generated answer.
CometAPI provides a fully compatible REST API—for seamless migration. Key details to API doc:
- Base URL: https://api.cometapi.com/v1/chat/completions
- Model Names: “
gemini-2.5-flash-lite“ - Authentication:
Bearer YOUR_CometAPI_API_KEYheader
See Also Gemini 2.5 Pro