
Gemini 2.5 Flash API is Google’s latest multimodal AI model, designed for high-speed, cost-efficient tasks with controllable reasoning capabilities, allowing developers to toggle advanced “thinking” features on or off via the Gemini API.Latest Models is gemini-2.5-flash.
Overview of Gemini 2.5 Flash
Gemini 2.5 Flash is engineered to deliver rapid responses without compromising on the quality of output. It supports multimodal inputs, including text, images, audio, and video, making it suitable for diverse applications. The model is accessible through platforms like Google AI Studio and Vertex AI, providing developers with the tools necessary for seamless integration into various systems.
Basic Information (Features)
Gemini 2.5 Flash introduces several stand-out features that distinguish it within the Gemini 2.5 family:
- Hybrid Reasoning: Developers can set a thinking_budget parameter to finely control how many tokens the model dedicates to internal reasoning before output .
- Pareto Frontier: Positioned at the optimal cost-performance point, Flash offers the best price-to-intelligence ratio among 2.5 models .
- Multimodal Support: Processes text, images, video, and audio natively, enabling richer conversational and analytical capabilities .
- 1 Million-Token Context: Unmatched context length allows deep analysis and long document understanding in a single request .
Model Versioning
Gemini 2.5 Flash has transitioned through the following key versions:
- gemini-2.5-flash-lite-preview-09-2025: Enhanced tool usability: Improved performance on complex, multi-step tasks, with a 5% increase in SWE-Bench Verified scores (from 48.9% to 54%). Improved efficiency: When enabling reasoning, higher-quality output is achieved with fewer tokens, reducing latency and costs.
- Preview 04-17: Early access release with “thinking” capability, available via gemini-2.5-flash-preview-04-17.
- Stable General Availability (GA): As of June 17, 2025, the stable endpoint gemini-2.5-flash replaces the preview, ensuring production-grade reliability with no API changes from the May 20 preview .
- Deprecation of Preview: Preview endpoints were scheduled for shutdown on July 15, 2025; users must migrate to the GA endpoint before this date .
As of July 2025, Gemini 2.5 Flash is now publicly available and stable (no changes from the gemini-2.5-flash-preview-05-20 ).If you are using gemini-2.5-flash-preview-04-17, the existing preview pricing will continue until the scheduled retirement of the model endpoint on July 15, 2025, when it will be shut down. You can migrate to the generally available model “gemini-2.5-flash” .
Faster, cheaper, smarter:
- Design goals: low latency + high throughput + low cost;
- Overall speedup in reasoning, multimodal processing, and long text tasks;
- Token usage is reduced by 20–30%, significantly reducing reasoning costs.
Technical Specifications
Input Context Window: Up to 1 million tokens, allowing for extensive context retention.
Output Tokens: Capable of generating up to 8,192 tokens per response.
Modalities Supported: Text, images, audio, and video.
Integration Platforms: Available through Google AI Studio and Vertex AI.
Pricing: Competitive token-based pricing model, facilitating cost-effective deployment.
Technical Details
Under the hood, Gemini 2.5 Flash is a transformer-based large language model trained on a mixture of web, code, image, and video data. Key technical specifications include:
Multimodal Training: Trained to align multiple modalities, Flash can seamlessly mix text with images, video, or audio, useful for tasks like video summarization or audio captioning .
Dynamic Thinking Process: Implements an internal reasoning loop where the model plans and breaks down complex prompts before final output .
Configurable Thinking Budgets: The thinking_budget can be set from 0 (no reasoning) up to 24,576 tokens, allowing trade-offs between latency and answer quality .
Tool Integration: Supports Grounding with Google Search, Code Execution, URL Context, and Function Calling, enabling real-world actions directly from natural language prompts .
Benchmark Performance
In rigorous evaluations, Gemini 2.5 Flash demonstrates industry-leading performance:
- LMArena Hard Prompts: Scored second only to 2.5 Pro on the challenging Hard Prompts benchmark, showcasing strong multi-step reasoning capabilities .
- MMLU Score of 0.809: Exceeds average model performance with a 0.809 MMLU accuracy, reflecting its broad domain knowledge and reasoning prowess .
- Latency and Throughput: Achieves 271.4 tokens/sec decoding speed with a 0.29 s Time-to-First-Token, making it ideal for latency-sensitive workloads.
- Price-to-Performance Leader: At $0.26/1 M tokens, Flash undercuts many competitors while matching or surpassing them on key benchmarks .
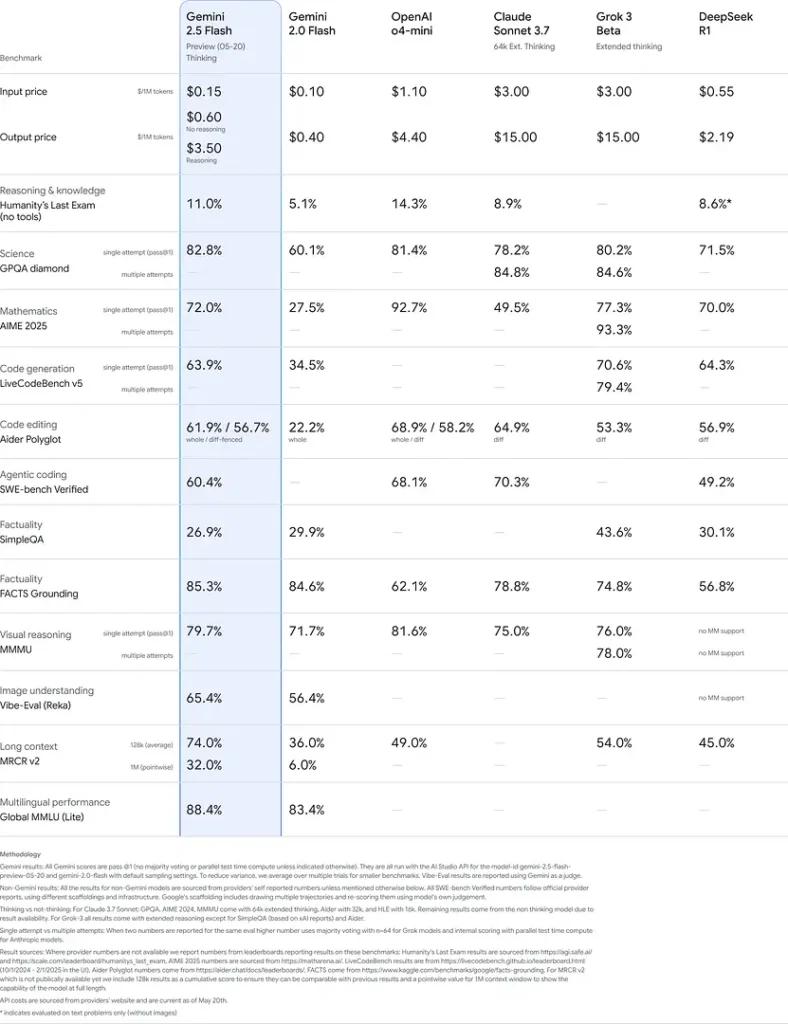
These results indicate Gemini 2.5 Flash’s competitive edge in reasoning, scientific understanding, mathematical problem-solving, coding, visual interpretation, and multilingual capabilities:
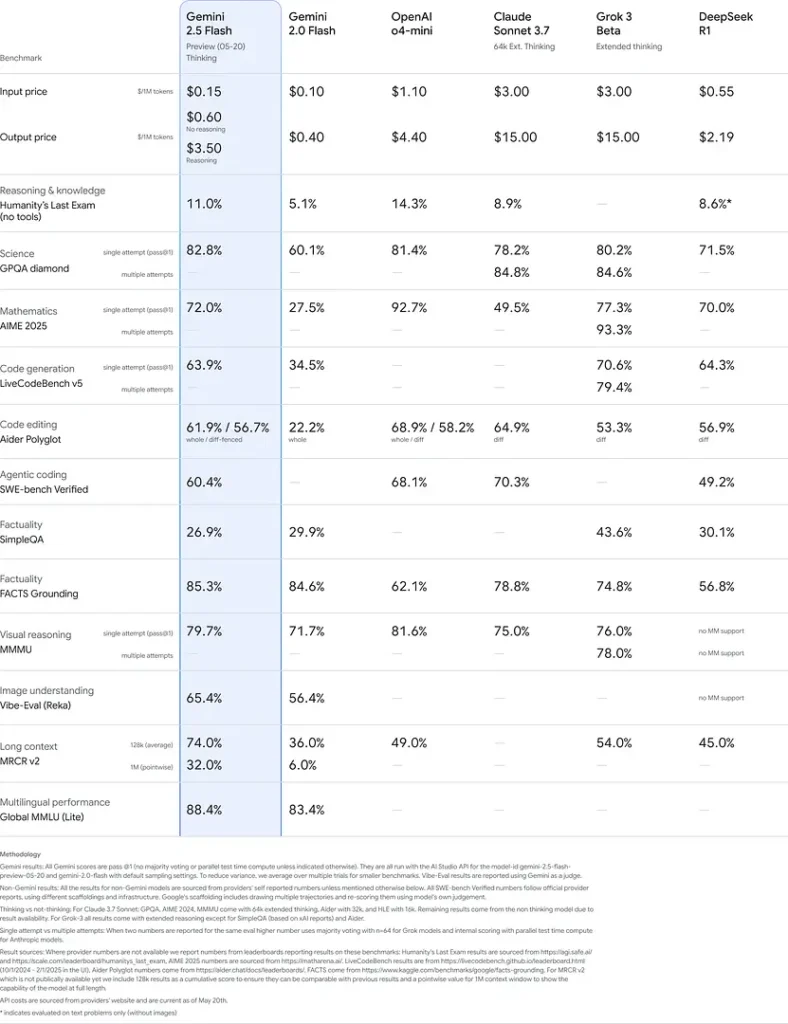
Limitations
While powerful, Gemini 2.5 Flash carries certain limitations:
- Safety Risks: The model can exhibit a “preachy” tone and may produce plausible-sounding but incorrect or biased outputs (hallucinations), particularly on edge-case queries. Rigorous human oversight remains essential.
- Rate Limits: API usage is constrained by rate limits (10 RPM, 250,000 TPM, 250 RPD on default tiers), which can impact batch processing or high-volume applications.
- Intelligence Floor: While exceptionally capable for a flash model, it remains less accurate than 2.5 Pro on the most demanding agentic tasks like advanced coding or multi-agent coordination.
- Cost Trade-Offs: Although offering the best price-performance, extensive use of the thinking mode increases overall token consumption, raising costs for deeply reasoning prompts .
See Also Gemini 2.5 Pro API
Conclusion
Gemini 2.5 Flash stands as a testament to Google’s commitment to advancing AI technologies. With its robust performance, multimodal capabilities, and efficient resource management, it offers a comprehensive solution for developers and organizations seeking to harness the power of artificial intelligence in their operations.
How to call Gemini 2.5 Flash API from CometAPI
Gemini 2.5 Flash API Pricing in CometAPI,20% off the official price:
- Input Tokens: $0.24 / M tokens
- Output Tokens: $0.96/ M tokens
Required Steps
- Log in to cometapi.com. If you are not our user yet, please register first
- Get the access credential API key of the interface. Click “Add Token” at the API token in the personal center, get the token key: sk-xxxxx and submit.
- Get the url of this site: https://api.cometapi.com/
Useage Methods
- Select the “
gemini-2.5-flash” endpoint to send the API request and set the request body. The request method and request body are obtained from our website API doc. Our website also provides Apifox test for your convenience. - Replace <YOUR_AIMLAPI_KEY> with your actual CometAPI key from your account.
- Insert your question or request into the content field—this is what the model will respond to.
- . Process the API response to get the generated answer.
For Model lunched information in Comet API please see https://api.cometapi.com/new-model.
For Model Price information in Comet API please see https://api.cometapi.com/pricing.
API Usage Example
Developers can interact with gemini-2.5-flash through CometAPI’s API, enabling integration into various applications. Below is a Python example :
import os
from openai import OpenAI
client = OpenAI(
base_url="
https://api.cometapi.com/v1/chat/completions",
api_key="<YOUR_API_KEY>",
)
response = openai.ChatCompletion.create(
model="gemini-2.5-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the concept of quantum entanglement."}
]
)
print(response)
This script sends a prompt to the Gemini 2.5 Flash model and prints the generated response, demonstrating how to utilize Gemini 2.5 Flash for complex explanations.