

Google and its research arm DeepMind have quietly (and then not-so-quietly) pushed another major step in the Gemini roadmap: Gemini 3.1 Pro. The release, rolled out across consumer-facing surfaces CometAPI, is positioned as a performance-and-reasoning upgrade to the Gemini 3 family — promising notably stronger long-form reasoning, improved multimodal understanding, and better scalability for real-world applications.
Google’s newest model — what is Gemini 3.1 Pro?
Gemini 3.1 Pro is the first incremental update in the Gemini 3 family positioned as a “most-capable” reasoning model optimized for multi-step, multimodal, and agentic tasks. Released into public preview in mid-February 2026 (preview announced Feb 19–20, 2026), the model is explicitly targeted at scenarios that require sustained chains of thought, tool use, and long-context understanding — for example: large-scale research synthesis, engineering agents that coordinate tools and systems, and multimodal analysis of documents that mix text, images, audio and video.
At a high level, Gemini 3.1 Pro is described by its developers as:
- Natively multimodal — able to accept and reason over text, images, audio and video.
- Built for long context — supporting very large context windows suitable for entire codebases, multi-document dossiers, or long transcripts.
- Optimized for reliable reasoning and agentic workflows, meaning it is tuned to plan, call tools, and verify outputs across multi-step tasks.
Why this matters now: organizations and developers are moving from “good conversational assistants” to “high-stakes decision-support and research agents” (legal drafting, R&D synthesis, multimodal document understanding). Gemini 3.1 Pro is explicitly designed for that corridor — to reduce hallucinations, produce traceable reasoning, and integrate with CometAPI for both prototyping and production.
What are the technical highlights and features of Gemini 3.1 Pro?
Native multimodality and extreme context windows
Gemini 3.1 Pro continues the Gemini lineage’s focus on multimodality. According to the model card and product notes, the model accepts and reasons over text, images, audio, and video in the same pipeline — a capability that simplifies workflows where data types are mixed (e.g., legal depositions with audio + transcript + scans). Notably, the model supports a 1,000,000-token context window and can produce long outputs (published notes put output limits at very large sizes appropriate to long-form tasks). This scale makes it suitable for use-cases such as analyzing whole code repositories, multi-chapter documents, or long transcripts without chunking.
“Dynamic thinking”: improved reasoning & stepwise planning
Google describes 3.1 Pro as having improved “thinking” — i.e., better internal chain-of-thought handling and dynamic selection of reasoning strategies depending on task complexity. The model is tuned to engage explicit multi-step planning when needed, and to be token-efficient while doing so. In practice, this translates to fewer hallucinations for complex, stepwise problems and improved factual consistency on multi-step reasoning benchmarks.
Agentic workflows & tool use
A major design focus for 3.1 Pro is agentic performance: coordinating tools, invoking web grounding or search, writing and executing code snippets, and verifying outputs through secondary passes. Google has integrated 3.1 Pro into agent-first products (e.g., the Antigravity development environment) to let models run tasks that involve an editor, terminal, and browser — and record artifacts like screenshots and browser recordings to verify progress. These features aim to reduce the gap between “advice-giving” models and models that actually perform multi-tool workflows reliably.
Specialized submodes (Deep Research, Deep Think)
Google pairs 3.1 Pro with “Deep Research” and references a forthcoming “Deep Think” variant. These submodes are targeted at—respectively—high-recall research tasks and maximal reasoning depth (at extra compute cost and latency). They’re meant to service analysts, researchers, and developers who need more deliberate, higher-quality outputs rather than the fastest, cheapest responses.
How does Gemini 3.1 Pro perform on benchmarks?
Gemini 3.1 Pro achieving strong gains over previous Gemini 3 Pro results, often taking the lead on a broad set of multi-step reasoning and multimodal measures — but trailing some competitors on specific specialized tasks (notably certain advanced coding or expert-level question suites). In short: broad improvements with narrow competitor edges in specialty benchmarks.
Key benchmark claims and headline numbers
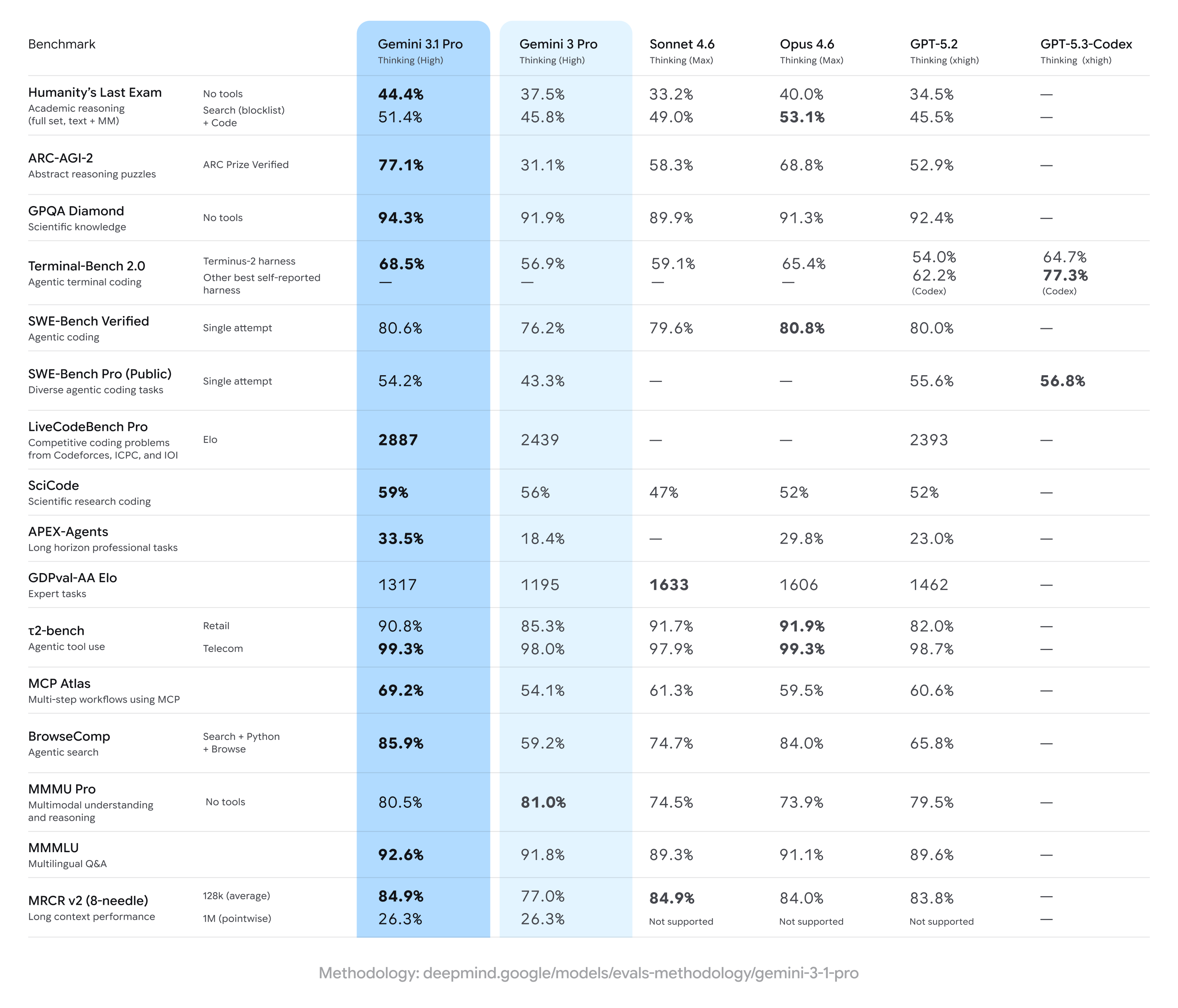
- ARC-AGI-2 (abstract reasoning / multi-step science puzzles): Reported increases for Gemini 3.1 Pro show substantial improvement from previous Gemini 3 Pro versions; one community test suite indicated a more-than-twofold improvement on ARC-AGI-2 vs the prior Gemini 3 Pro baseline in short, focused tests. Specific reported scores (community tests) put Gemini 3.1 Pro at ~77.1% on some ARC-style aggregations (public reporting).
- GPQA Diamond and graduate-level science benchmarks: Data repor ts indicate Gemini 3.1 Pro hit record highs on GPQA Diamond (a graduate-level science QA benchmark), surpassing earlier Gemini models and setting a new high watermark for the family in independent runs. These gains reflect the model’s improved chain-of-thought and stepwise reasoning tuning.
- “Humanity’s Last Exam” with tools enabled (multi-tool, grounded reasoning): In head-to-head comparisons with Anthropic’s Claude Opus 4.6, Claude achieved 53.1% on this complex tool-enabled benchmark while Gemini 3.1 Pro reached 51.4% in the same round of testing — showing Gemini close behind but not quite on top on that particular multi-tool exam.
- Coding & terminal benchmarks (Terminal-Bench 2.0, SWE-Bench Pro): Specialist coding benchmarks showed more divergence. On Terminal-Bench 2.0 with specific harnesses, GPT-5.3-Codex variants scored around 77.3% vs Gemini 3.1 Pro’s ~68.5% in the same comparisons. On SWE-Bench Pro publicly reported results, Gemini 3.1 Pro scored ~54.2% vs GPT-5.3-Codex’s 56.8% — closer, but with OpenAI’s Codex family holding an edge on specialized programming tasks in those runs.
- GDPval-AA Elo (expert tasks rating): In an Elo-style aggregated ranking for expert tasks, Claude Sonnet/Opus variants scored higher (e.g., ~1606–1633 points) while one public report placed Gemini 3.1 Pro at ~1317 points in that same dataset — indicating room for improvement on certain narrow expert domains.
Real-world trial results and hands-on tests
Hands-on analyst writeups show Gemini 3.1 Pro particularly excels at:
- Long-context summarization and multi-document synthesis, where the 1M token window avoids artifact-prone chunking.
- Multimodal comprehension tasks where image + text grounding improves factual extraction.
- Agentic automation (e.g., coordinating simple toolchains) — with Antigravity trials demonstrating multi-agent task orchestration is feasible with artifacts that record each step.
Where Gemini 3.1 Pro still lags (what the numbers say)
No model is uniformly best. Independent commentary and community testing highlight specific gaps:
- Software engineering and code-maintenance benchmarks (SWE-Bench Pro and similar) — Gemini 3.1 Pro trailing a competitor (Anthropic’s Claude Opus 4.6) on tasks that test practical software engineering abilities: large-scale refactors, bug triage in messy codebases and some types of automated program repair. In other words, for day-to-day engineering maintenance, specialized models still maintain an edge in certain testbeds.
- Latency-sensitive microtasks — because Gemini 3.1 Pro is tuned for depth, tasks requiring ultra-low latency and high throughput (e.g., micro-inference for lightweight conversational UIs) may be better served by “Flash” or other optimized variants in the Gemini family.
What is the pricing for Gemini 3.1 Pro?
you can access Gemini 3.1 Pro two ways — consumer subscription or the developer API — and the pricing is different for each.
- Consumer (Gemini app / Google AI Pro): Access to Gemini 3.1 Pro is included in the Google AI Pro subscription, which in the U.S. is $19.99 / month (Google also offers lower-tier “AI Plus” and a higher “AI Ultra” tier). Google.
- Developer / API (token-based): If you call the Gemini models via the Gemini/AI developer API, pricing is metered by tokens. For the Gemini 3.x Pro preview the published developer prices are roughly: $2.00 per 1M input tokens and $12.00 per 1M output tokens for the standard (≤200k prompts) band — with higher tiers (e.g. $4/$18 per 1M) for very large contexts. (See the Gemini API pricing table for full details and batch pricing.)
- If you use Gemini 3.1 Pro via CometAPI:
| Comet Price (USD / M Tokens) | Official Price (USD / M Tokens) |
|---|---|
| Input:$1.6/M; Output:$9.6/M | Input:$2/M; Output:$12/M |
Consumer subscription pricing (Gemini app)
For end-user plans inside the Gemini app, Google structures tiers that gate access to model variants and extra features: Google AI Pro and Google AI Ultra. Prices vary by market and currency; published examples show Google AI Pro at $19.99/month (with promotional trials available) and tiered currency pricing is shown on the product page (including trial offers and short-term reduced rates). AI Ultra bundles higher access (e.g., priority access to new innovations, higher credits for video generation) at a higher monthly rate. These consumer plan prices are competitive with other high-end consumer AI subscriptions and are positioned to give individual power users or small teams access to 3.1 Pro features without API integration.
Practical prompt & usage tips (what I’d do)
Use these to get reliable, repeatable results:
- Explicit step planner
Prompt pattern:1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.This leverages 3.1 Pro’s stronger stepwise execution and gives you checkpoints. - Structured output with schemas
Ask for JSON with a schema andstrict: true. Because 3.1 Pro produces long, schema-adherent outputs more reliably, you’ll get bigger single responses you can parse downstream. - Tool-check sandwich
When invoking external tools (APIs, code runners), have the model produce: plan → exact tool call (copy/paste friendly) → validation steps. Then verify the validation steps outside the model before continuing. - Beware of single-step trust
Even if the model writes perfect-looking code or commands, run independent validation (tests, linters, sandboxed execution) — especially for agentic/autonomous actions.
Hands-On With Gemini 3.1 Pro
Trial case 1: Long-context research assistant (NotebookLM / Deep Research)
Goal: Evaluate the model’s ability to synthesize 10–50 long documents (e.g., reports, whitepapers) into a multi-page executive summary with citations and action items.
Setup: Feed a corpus totaling 200k–800k tokens; task the model to produce a 2–4 page summary with explicit citations and “next step” recommendations. Use a repeatable prompt template and measure time, token usage (cost), and factual accuracy.
Results: Faster end-to-end summarization with fewer chunking artifacts relative to older models, higher citation fidelity in the summary, and improved coherence at scale — at the cost of significant token usage (so plan budget). Benchmarks and hands-on tests show Gemini 3.1 Pro excels at multi-document synthesis due to the 1M token window.
Trial case 2: Agentic coding assistant (Antigravity + GitHub Copilot)
Goal: Measure reduction in time-to-complete for multi-step developer tasks (e.g., implement a feature across several files, run tests, fix failing tests).
Setup: Use Antigravity or GitHub Copilot in preview with Gemini 3.1 Pro selected. Define reproducible tasks (issue creation → implement → run tests), log steps and agent artifacts, and compare to a human-only baseline.
Results: Improved orchestration of multi-step tasks (artifact recording, automatic suggestion of patch candidates), better multi-file reasoning than previous Gemini 3 Pro, and measurable time savings on routine feature work. Specialty, low-level system debugging tasks may still favor specialized code-first models (community results show a gap vs some GPT-Codex variants on certain terminal benchmarks).
Trial case 3: Multimodal legal/medical document review
Goal: Use the model to ingest a mixed corpus (scanned PDFs, images, audio transcripts), extract key facts, and produce a risk matrix and prioritized actions.
Setup: Supply a dataset with scanned images and OCR text, plus supporting audio. Measure precision in named entity extraction, false positive rate, and the model’s ability to reference source artifacts.
results: Stronger integrated reasoning across modalities and better traceable outputs (ability to point to the image / page / audio timestamp that supports an assertion). The long context window reduces the need for manual chunking and cross-referencing. However, in regulated domains, outputs should be validated by domain experts and a grounding/verification pipeline should be used.
First impressions (what feels different)
- Deeper stepwise reasoning. Tasks that previously needed multiple back-and-forths — e.g., multi-document synthesis, multi-step math/logic — tend to complete in fewer passes and with clearer chain-of-thought style outputs (without exposing internal instruction text). This is the headline Google emphasized.
- Longer, higher-quality structured outputs. JSON and long-form automations are more consistent and often much longer (some users reported output sizes far larger than 3.0). That makes it great for generator jobs where you want a single, big payload. Expect to handle bigger outputs and streaming.
- More efficient tokens / context handling. Improved token efficiency and a more “grounded, factually consistent” behavior for tool-using scenarios. That shows in fewer hallucinations on short factual lookups.
Final analysis: Is Gemini 3.1 Pro worth adopting now?
Gemini 3.1 Pro represents a meaningful forward step in the Gemini family with demonstrable improvements on reasoning, coding and agentic benchmarks — backed by Google’s published model card and independent trackers that cite large jumps on select leaderboards. For teams that need advanced reasoning, agentic tool coordination, or long-context multimodal capabilities, 3.1 Pro is a compelling candidate.
Developers can access Gemini 3.1 Pro via CometAPI now.To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up fo Gemini 3.1 pro today !
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!