

Google’s Gemini family just grew more cost-efficient and broadly accessible with a new “Flash” tier in the Gemini 3 line. Gemini 3 Flash targets low-latency, high-throughput use cases: it’s a lighter, faster variant of Gemini 3 that’s already appearing in the Gemini app and is available through CometAPI. Its published unit prices (per million tokens) position it at a fraction of Gemini 3 Pro’s cost—making Flash attractive for production workloads where price and speed matter more than the absolute top-tier reasoning ceiling.
What is Gemini 3 Flash?
Gemini 3 Flash is a price- and latency-optimized member of the Gemini 3 family. Where Gemini 3 Pro focuses on the absolute frontier of multimodal reasoning, very large context lengths, and the highest-quality agentic behaviors, the Flash variant trades some of that peak compute intensity for much lower operational cost and faster responses—without sacrificing Gemini’s multimodal design (text, image, audio, etc.) for everyday tasks.
Currently, it can be accessed through the Gemini APP and CometAPI. Among the options provided by the Gemini APP, fast is the standard version of Gemini 3 flash, thinking is the thinking version of Gemini 3 flash, and pro is Gemini 3 Pro.
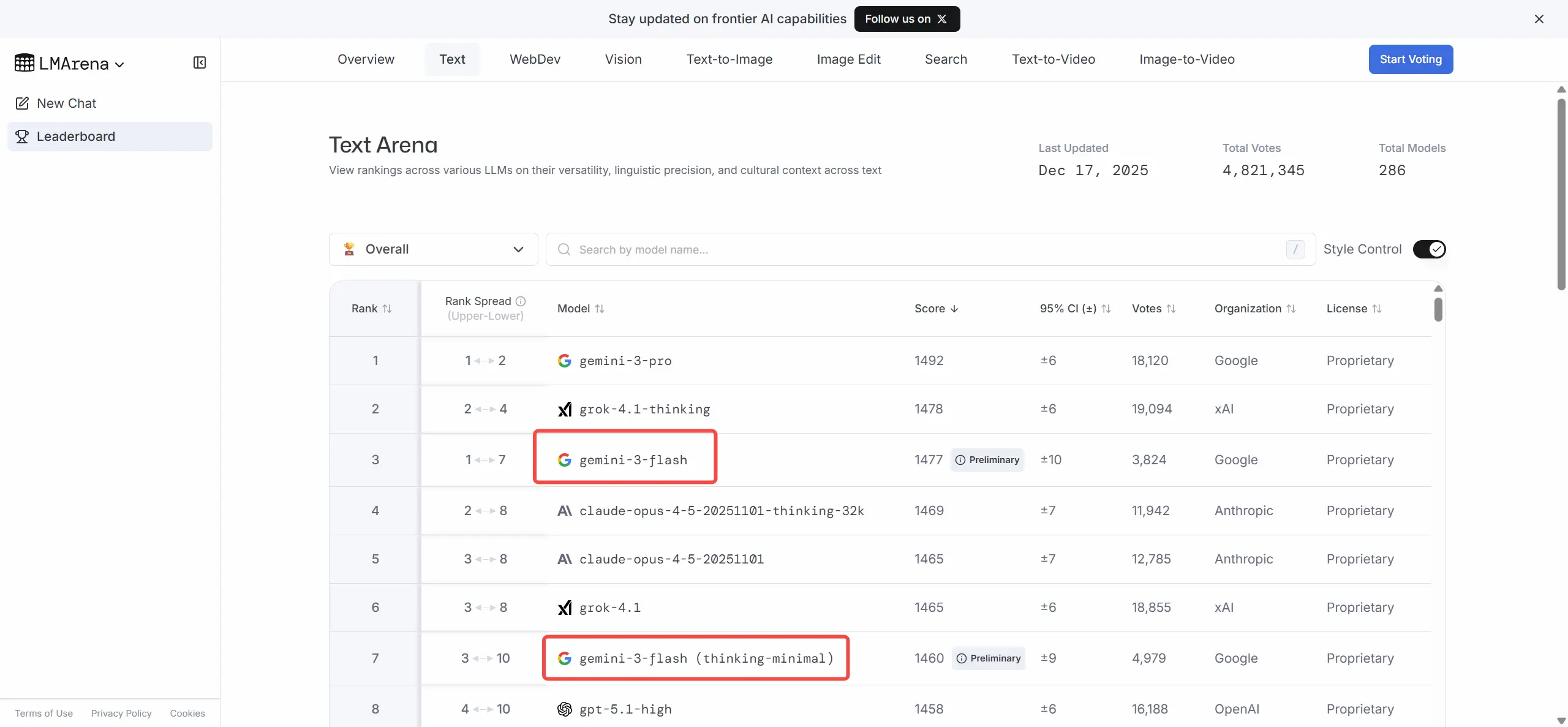
LMArena’s Text Arena currently ranks gemini-3-flash near the top of the text leaderboard: rank 3, score 1477 (95% CI ±10), 3,824 votes; a close runner to gemini-3-pro (1492±6, 18,120 votes). The gap is small (≈15 Elo), which translates to only a ~52% expected head-to-head win probability for Gemini 3 Pro against Flash — in practice this means Flash’s text quality is extremely close to Pro on the community-driven Text Arena measure.
How does Flash sit inside the Gemini family?
Think of Gemini 3 as a model family with multiple points on the performance/cost curve:
- Gemini 3 Pro — the flagship: maximum reasoning, largest agentic/tooling capabilities, and the highest price per token.
- Gemini 3 Flash — the price/performance workhorse: lower unit cost, lower latency, still multimodal and capable for most production tasks.
This product stratification is common among modern LLM providers: give enterprises an “all-capable” model and give developers a faster, cheaper option for bulk inference.
How does Gemini 3 Flash compare to Gemini 3 Pro in technical ability?
Short answer: Flash is highly capable for most practical use cases, but Pro remains the best choice for the hardest reasoning, longest contexts, and most demanding multimodal/agentic tasks. Here’s a breakdown.
When to pick Gemini 3 Pro
- Extremely complex reasoning tasks (research-grade problem solving, multi-stage code synthesis).
- Tasks needing the largest available context windows or experimental “Deep Think” modes where chain-of-thought and tool orchestration matter deeply.
When to pick Gemini 3 Flash
- High-throughput chatbots, customer support pipelines, content generation at scale.
- Real-time interactive experiences where latency and cost matter more than eeking out the final bits of reasoning accuracy.
- Embedded, on-demand services where predictable per-token spend is critical.
Both models are part of the same family and share architecture lineage; choice comes down to the tradeoffs above.
How much does Gemini 3 Flash cost — and compare to Gemini 3 Pro
This is one of the most important practical questions for teams and product owners: what will it cost in production, and how much can Flash save you?
Published per-token list prices (official and CometAPI)
- Gemini 3 Pro (official Google API preview): Input = $2.00 per 1M tokens, Output = $12.00 per 1M tokens for the standard (≤ 200k) context tier. These numbers come from Google’s Gemini 3 API pricing documentation.
- Gemini 3 Flash (official Google Flash price): Google’s official “Flash” pricing entries list Flash at about $0.50 per 1M input tokens and $3.00 per 1M output tokens for the standard tiers.
- Gemini 3 Flash (CometAPI reseller / aggregator price): CometAPI lists $0.24 per 1M input tokens and $2.00 per 1M output tokens for
gemini-3-flashon its model page (The official discount is usually 20%, but it can be adjusted depending on holidays and marketing plans.).
If you access Gemini 3 Flash through CometAPI at the prices they list, Flash is ~8.3× cheaper on input and 6× cheaper on output versus Gemini 3 Pro.
How can you access Gemini 3 Flash?
Can I use Gemini 3 Flash in the Gemini app? If so, how?
Yes — Google rolled the Gemini 3 family into the Gemini app as part of the November 2025 “Gemini Drop” updates. The app’s model selector allows users to pick between model variants (for example switching from 2.5 Flash to Gemini 3 Pro or to other available models), and Gemini 3’s appearance in the mobile app. To switch models in the mobile app: open the Gemini app, tap the model listed at the bottom of the home screen to open the model selector, and choose the model/“Thinking” variant you want.
Quick steps (mobile app):
- Open the Gemini app (iOS / Android).
- Tap the model name or model selector near the bottom of the home screen (often shows the currently active model, e.g., “2.5 Flash”).
- From the model selector, choose Gemini 3 family / Gemini 3 Flash if it’s listed (or choose Gemini 3 Pro / Deep Think if you need more capacity).
Note: availability in the app can be regionally phased and may depend on subscription tier (free, Plus, Pro, Ultra), feature testing, or staged rollouts. If you don’t see Gemini 3 Flash immediately, check for app updates and the official Gemini release notes.
How can developers call Gemini 3 Flash via API (CometAPI example)
CometAPI has already added gemini-3-flash to its catalogue, and its model page explains how to call it through CometAPI’s unified endpoint. Minimal CometAPI flow (high level):
- Process the response the same way you would with other LLM gateways (handle streaming if supported, parse function call JSON, etc.).
- Sign up / log in to CometAPI and create an API token.
- Use the
gemini-3-flashmodel id and CometAPI’s base URL to post a generate request.
Below is a compact example (based on CometAPI’s sample patterns) showing how to call gemini-3-flash via CometAPI; replace <YOUR_COMETAPI_KEY> with your actual key. The model ID and endpoints below match CometAPI’s docs.
from google import genai
import os
# Get your CometAPI key from https://api.cometapi.com/console/token, and paste it here
COMETAPI_KEY = os.environ.get("COMETAPI_KEY") or "<YOUR_COMETAPI_KEY>"
BASE_URL = "https://api.cometapi.com"
client = genai.Client(
http_options={"api_version": "v1beta", "base_url": BASE_URL},
api_key=COMETAPI_KEY,
)
response = client.models.generate_content(
model="gemini-3-flash",
contents="Explain how AI works in a few words",
)
print(response.text)
FAQs
Is Gemini 3 Flash the same model family as Gemini 3 Pro?
Yes — they’re part of the Gemini-3 family and share architecture and API paradigms; Flash is the speed/cost-optimized variant while Pro is the high-fidelity reasoning variant.
Can I switch between Flash and Pro without code changes?
Generally yes — the Gemini family exposes similar API surfaces so the change is often as simple as changing the model ID (for example gemini-3-pro-preview to gemini-3-flash) and adjusting parameters. However, you should validate any changes in a staging environment because subtle behavioral differences may require prompt tuning.
How do I verify live pricing for my account?
Check the official provider billing console (Google Cloud / Vertex AI) or your aggregator (CometAPI dashboard). Aggregator prices can differ from Google’s list prices, and enterprise discounts / negotiated rates may apply.
Conclusion — should you adopt Gemini 3 Flash?
If your priority is real-time performance, predictable throughput and materially lower per-token costs, Gemini 3 Flash is a strong candidate. It’s purpose-built for conversational UIs, streaming agents, and bulk preprocessing where the cost/latency tradeoff matters. If your workloads demand the absolute best reasoning, the deepest multimodal fidelity, or extremely long context windows, you’ll still want Gemini 3 Pro for those high-value cases. A common and pragmatic pattern is to use Flash as the front line (fast, cheap) and escalate to Pro for the cases that fail a quality threshold — that pattern captures the best of both worlds.
To begin, explore Gemini 3 Flash’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Free trial of Gemini 3 Flash !