

Google DeepMind has today announced significant expansions to its Gemini 2.5 family, unveiling the stable releases of Gemini 2.5 Pro and Gemini 2.5 Flash alongside a preview of the all‑new Gemini 2.5 Flash‑Lite model. These updates reflect Google’s continued commitment to offering a spectrum of AI models that balance cost, speed, and performance for diverse workloads .
Stable Releases: Gemini 2.5 Pro & Flash
On June 17, 2025, Google marked the general availability of Gemini 2.5 Pro and Gemini 2.5 Flash. The Pro variant delivers maximum reasoning power and is tailored for high‑complexity tasks such as advanced code generation, scientific analysis, and large‑scale data synthesis. In contrast, Gemini 2.5 Flash offers a mid‑tier option optimized for everyday uses that demand low latency—ideal for chatbots, summarization, and content creation at scale.
Overview: Three Models in the Gemini -2.5 Family
| Model | Status | Strengths | Ideal Use Cases |
|---|---|---|---|
| Gemini 2.5 Flash‑Lite (preview) | Preview | Fastest & cheapest; multimodal; controllable reasoning; tool-enabled | High-volume tasks like chatbots, summarization, search |
| Gemini 2.5 Flash | Stable | Balanced: low latency, good reasoning, multimodal | Real-time conversations, customer support |
| Gemini 2.5 Pro | Stable | Most capable: deep reasoning, huge context, multimodal | Research, complex coding, scientific tasks |
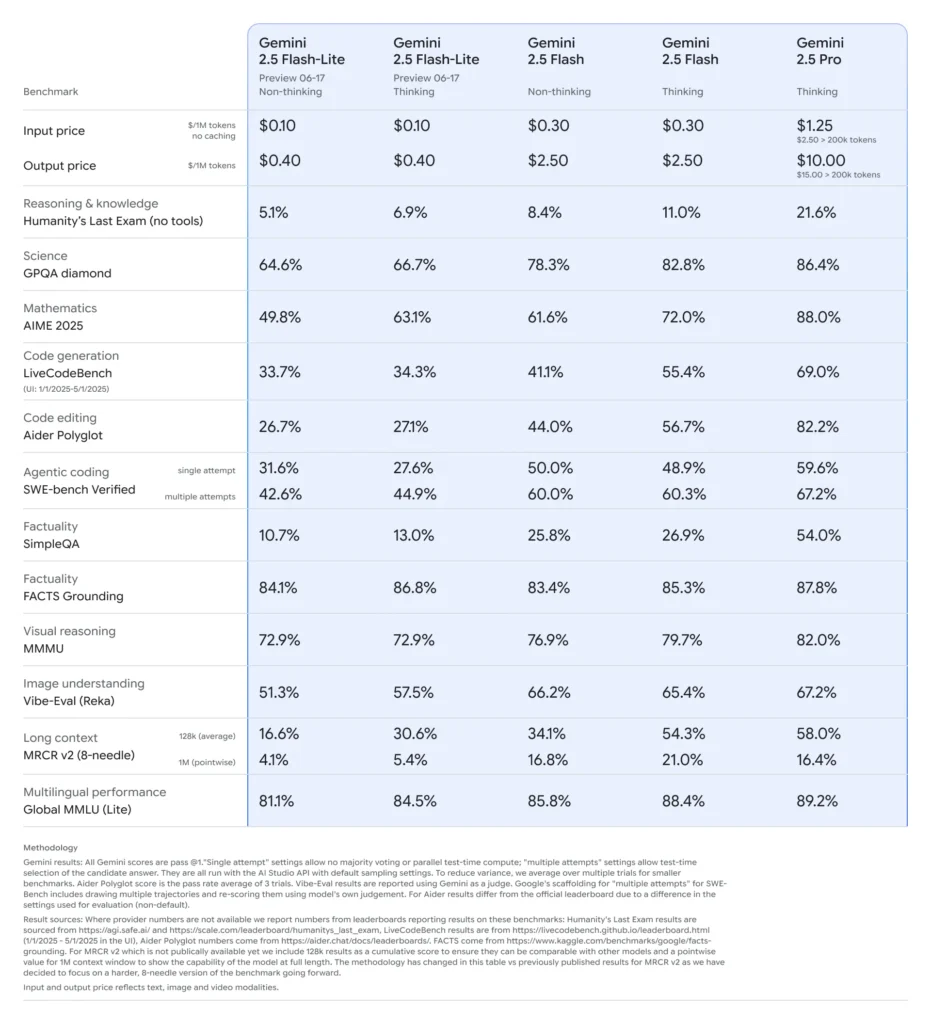
Gemini 2.5 Flash‑Lite: Preview Highlights
Ultra‑low latency & cost savings:Designed for high-volume, real-time applications like translation, classification, and summarization. Boasts faster inference and lower cost per call compared to both 2.0 Flash‑Lite and the full Flash version .
Improved foundational performance: Outperforms earlier Flash‑Lite models across benchmarks in code generation, logic, math, multimodal reasoning, and science.
Cost and efficiency: Flash‑Lite pricing (preview): ~$0.10 per 1M input tokens and ~$0.40 per 1M output tokens—significantly cheaper than Flash ($0.30/$2.50) and Pro ($1.25/$10) .
Full Gemini -2.5 capabilities:
- Controllable Thinking: Users can set “thinking budgets” (token limits) to trade speed for depth—Flash‑Lite can toggle this on as needed.
- Multimodal Input: Supports text, image, audio, and video (including hour-long clips), with abilities to parse charts, UI, scenes, event summaries .
- Tool Integration: Includes Google Search, code execution and a million-token context window, matching the capabilities of Flash and Pro.
Positioning on the Price‑Performance Curve
Google positions Flash‑Lite’s high speed and low cost at the Pareto frontier, meaning it’s among the most cost‑efficient-yet-capable models worldwide (). In comparative evaluations, Flash‑Lite represents the best value: smart yet affordable .
About Flash and Pro
- Gemini 2.5 Flash: Stable, low-latency, multi-modal thinking model. Positioned below Pro but roughly on par with GPT-4o in capability, with superior speed and cost efficiency ().
- Gemini 2.5 Pro: Google’s most advanced model. Renowned for handling hours-long video/audio, complex code and math, and huge-context reasoning. Also introduces selective “thinking budgets” and improved code quality to serve as a long-term stable flagship AI .
Deployment & Pricing
- Availability: All three models are accessible through Google AI Studio, Google Cloud Vertex AI, and the Gemini app .
- Cost structure (Vertex AI pricing from June 16, 2025):
- Pro: $1.25/1M input, $10/1M output (higher beyond 200K tokens)
- Flash: $0.15/1M input, $3.50/1M output in “thinking” mode—and includes 1,500 free grounded prompts daily ()
- Flash‑Lite (preview): ~$0.10/$0.40 per 1M tokens
Getting Started
CometAPI provides a unified REST interface that aggregates hundreds of AI models—under a consistent endpoint, with built-in API-key management, usage quotas, and billing dashboards. Instead of juggling multiple vendor URLs and credentials.
Developers can access Gemini 2.5 Flash-Lite (preview) API through CometAPI, the latest models listed are as of the article’s publication date. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.