

On March 3, 2026, Google introduced Gemini 3.1 Flash-Lite, the newest member of the Gemini 3 family designed specifically as a high-throughput, low-latency, cost-efficient engine for developer and enterprise workloads. Google positions Flash-Lite as the “fastest and most cost-efficient” model in the Gemini 3 line: a lightweight variant that aims to deliver streaming interactions, large-scale background processing, and high-frequency production tasks (for example, translation, extraction, UI generation, and large-volume classification) at a much lower price point than its Pro counterparts.
Below we unpack what Flash-Lite is.
What is Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite is a member of Google’s Gemini 3 family that intentionally trades some of the highest-tier reasoning depth for speed and cost efficiency. It is natively multimodal in the Gemini lineage (able to accept text, images and other modalities as input), but is tuned and deployed specifically to deliver maximal tokens-per-second throughput and substantially lower per-token billing for workloads that require rapid, repeated inference rather than maximal cognitive depth. The model is described as being derived from the 3.1 Pro architecture but optimized for throughput, latency, and cost.
Key design tradeoffs
The "Lite" moniker signals the model’s engineering emphasis:
- Throughput over heavyweight reasoning: Flash-Lite intentionally reduces compute per token to deliver faster Time-to-First-Token (TTFT) and continual output speed. That makes it ideal for pipelines where each request must be served rapidly and at scale (e.g., safety filters, real-time assistants, high-volume generation).
- Cost efficiency for high volumes: By lowering per-token compute, the model can be offered at lower prices per million tokens, which reduces marginal cost in large-scale applications (e.g., millions to billions of tokens per month). Google’s preview pricing shows a significant delta versus the Pro tier.
- Quality tuned for pragmatic tasks: According to early scoring summaries, Flash-Lite maintains strong results on standard classification, multilingual and many multimodal tasks, but it is not positioned to beat Pro on the most complex multi-step reasoning or code generation benchmarks where depth matters.
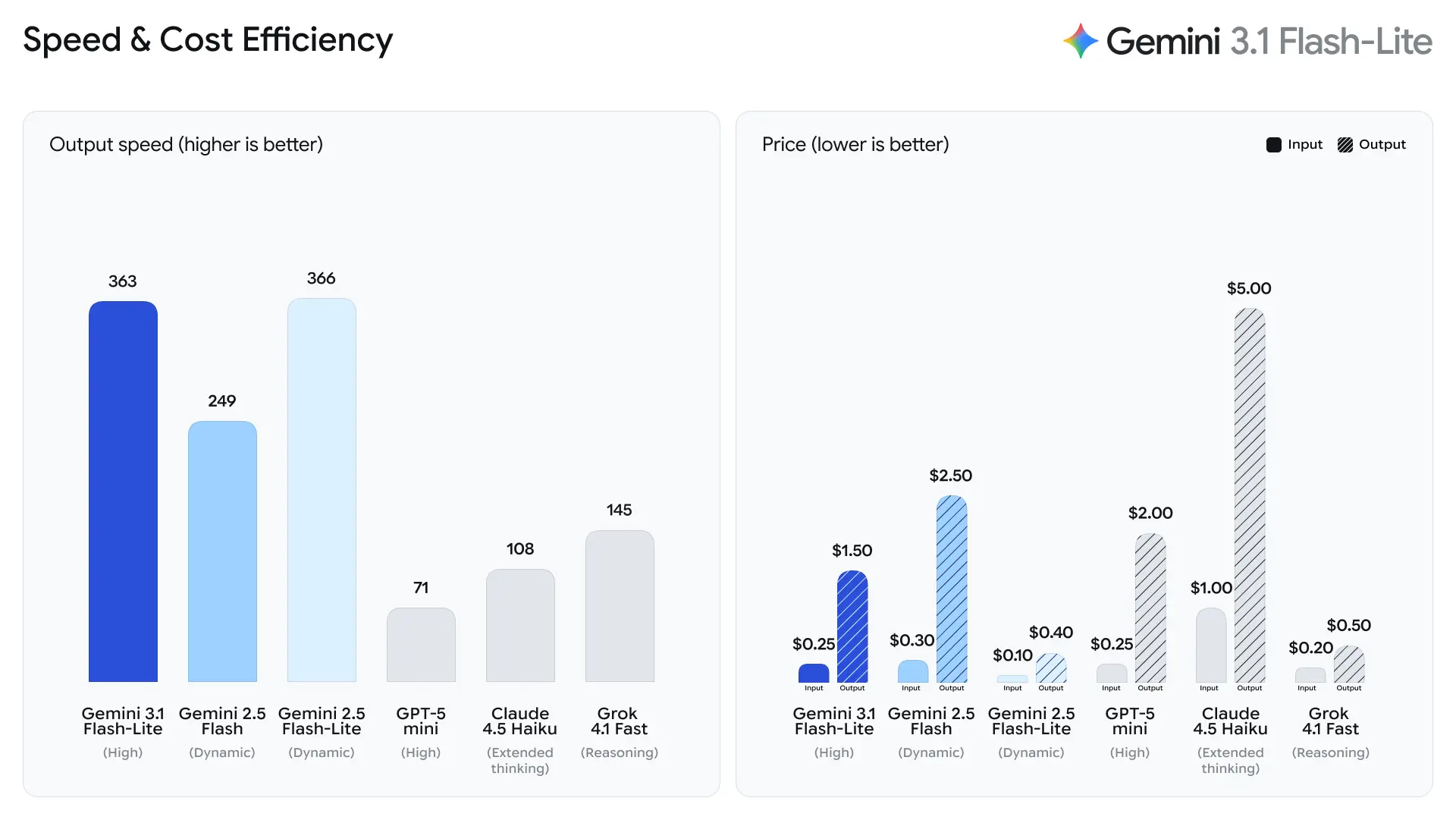
These workloads require reliable output and high throughput, but they do not always require the complex multi-step reasoning capabilities of flagship models.
Key Features of Gemini 3.1 Flash-Lite
1. Low latency and fast first-token time
Google emphasizes time-to-first-answer token as a primary metric for Flash-Lite. The company reports ~2.5× faster time-to-first-token compared to Gemini 2.5 Flash and up to 45% faster output generation — improvements that directly impact perceived responsiveness for end users and throughput costs for back-end systems. These gains make Flash-Lite well suited to interactive features (e.g., chatbots embedded in apps) and high-QPS pipelines where microseconds matter.
This improvement significantly enhances real-time applications such as:
- conversational AI
- AI-powered search assistants
- interactive chatbots
- live translation services
Lower latency improves the user experience by reducing waiting time and enabling more fluid interactions.
2. Cost-Efficient Token Pricing
AI inference costs are often calculated per token, making pricing a critical factor for large-scale deployments.
Gemini 3.1 Flash-Lite introduces a highly competitive pricing structure:
| Token Type | Price |
|---|---|
| Input tokens | $0.25 per 1M tokens |
| Output tokens | $1.50 per 1M tokens |
This represents a reduction compared with previous Flash models, making the model attractive for organizations running large workloads.
By comparison:
| Model | Input Price | Output Price |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
This pricing strategy allows developers to run AI at scale without dramatically increasing operational costs.
If you're looking for an even better price, then Gemini Flash-Lite offers a 20% discount on CometAPI.
3. “Thinking levels” (controllable inference depth)
Gemini 3.1 Flash-Lite includes the “thinking levels” capability — a developer-configurable knob that instructs the model to prefer faster, shallower processing for trivial tasks and deeper reasoning for harder tasks. This is important in practice because it enables dynamic cost/latency tradeoffs per request without switching models.
Developers can configure the model’s reasoning depth to match the complexity of the task.Thinking levels: Supports four levels: Minimal, Low, Medium, and High.
This dynamic approach allows applications to optimize resource usage while maintaining quality where it matters.The practical strategy is roughly as follows:
- Minimal/Low: Suitable for high-concurrency but logically simple tasks such as translation, classification, and sentiment analysis, prioritizing maximum speed and minimum cost.
- Medium: Suitable for most production tasks, striking a balance between quality and efficiency.
- High: Suitable for tasks requiring deep reasoning, such as generating user interfaces, creating simulations, and executing complex instructions.
4. Multimodal capability with a lightweight footprint
Although Flash-Lite is optimized for speed and cost, it retains the Gemini 3 line’s multimodal foundations: it can accept image inputs for classification or light multimodal reasoning when the use case requires it — but developers should expect the economical design to favor shorter, bounded multimodal operations over very large image-heavy workflows. Like other Gemini models, Gemini 3.1 Flash-Lite supports multimodal inputs, allowing developers to process different types of data.
Supported inputs include:
- Text
- Images
- Video
- Audio
- PDFs
The model’s ability to analyze multiple types of information enables new use cases, such as:
- automated document processing
- visual data extraction
- multimedia summarization
Earlier Gemini models also demonstrated strong multimodal reasoning capabilities across visual and knowledge benchmarks.
Performance benchmarks — real numbers and what they mean
Google’s announcement and product documentation present several benchmark data points intended to help buyers understand where Flash-Lite sits within the ecosystem.
Developer-facing speed metrics
- 2.5× faster Time to First Answer Token vs Gemini 2.5 Flash (Google’s stated internal comparison).
- 45% faster output generation vs Gemini 2.5 Flash.
These are performance-engineering metrics rather than human-judged quality metrics; they reflect improvements in runtime microarchitecture, batching, and inference stack optimizations that reduce latency for short responses. Faster first-token times reduce perceived lag in interactive applications and increase overall per-server throughput, which can lower total compute costs for the same QPS.
Tokens-per-second (t/s) and throughput
According to Artificial Analysis's test data, the 3.1 Flash-Lite achieved an output speed of 388.8 tokens per second (the median for models in the same price range is only 96.7 tokens/second). This speed is top-tier among models in its class.
However, Artificial Analysis also pointed out a problem: the 3.1 Flash-Lite's first token latency (TTFT) is 5.18 seconds, which is relatively high for inference models in the same price range (the median is 1.82 seconds). Additionally, the model generated 53 million tokens during the evaluation process, which is relatively high compared to the average of 20 million. This means that if your scenario is very sensitive to first token latency or has strict requirements for output conciseness, you may need to optimize the thought level and prompts.
Benchmark scores for reasoning and factuality
Google included cross-model comparisons showing Gemini 3.1 Flash-Lite performing strongly against peers and previous Gemini variants on aggregate reasoning/factual tasks:
- Arena.ai Elo score: Gemini 3.1 Flash-Lite reportedly achieved an Elo of 1432 on the Arena evaluation leaderboard — a composite head-to-head ranking showing competitive relative performance in direct-match scenarios.
- GPQA Diamond: 86.9% (a gauge of question answering robustness).
- MMMU Pro: 76.8% (a multimodal/multi-task metric used internally/externally by some labs).
- LiveCodeBench (Coding Ability): 72.0%
- CharXiv Reasoning (Graphical Reasoning): 73.2%
- Video-MMMU (Video Comprehension): 84.8%
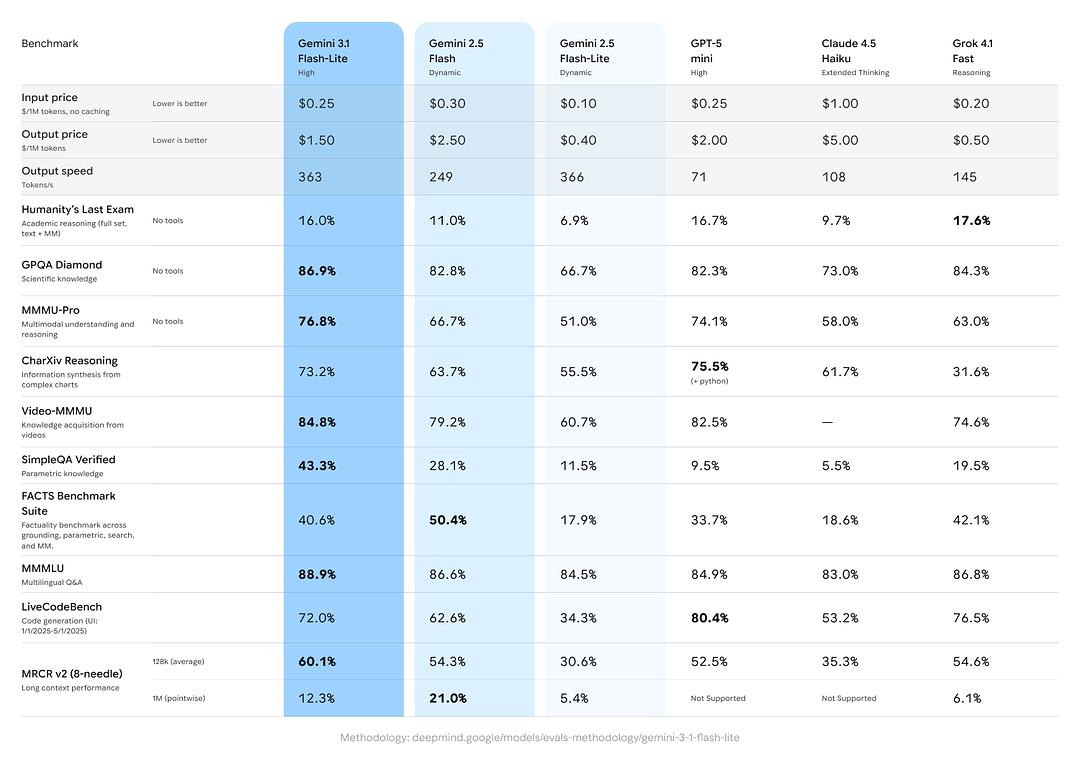
Gemini 3.1 Flash-Lite surpasses older Gemini 2.5 Flash on several of these metrics while delivering much better speed/cost.
Use cases that fit Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite is designed around a clear set of practical workloads where high throughput and lower cost per token are decisive:
High-frequency conversational agents & streaming UI
Real-time chatbots, live transcription + translation streams, and collaborative UIs that display partial answers as the model generates benefit from Flash-Lite’s streaming token output and low time-to-first-token.
Bulk data processing (RAG, transformation pipelines)
Massive document ingestion: entity extraction, metadata tagging, classification, and translation tasks performed over millions of documents — Gemini 3.1 Flash-Lite lowers inference cost while providing acceptable accuracy for templated or rule-driven outputs.
Edge-style or background compute
Workloads that process incoming telemetry or unstructured data continuously (e.g., content moderation classification pipelines, automated report generation) are good fits because Gemini 3.1 Flash-Lite minimizes per-unit cost.
Developer tooling and batch code completion
For features like multi-file scaffolding, large-scale code linting, and template generation at scale, Gemini 3.1 Flash-Lite’s speed advantages reduce latency and cost for developer experience tooling where absolute maximal reasoning depth is not required.
Comparing Gemini 3.1 Flash-Lite to other Gemini models and competitors
Within the Gemini family
- Gemini 3.1 Pro: highest capability on complex reasoning and multi-step planning; significantly costlier and slower per token but better for deep nuanced tasks.
- Gemini 3.1 Flash (non-Lite): targets a middle ground between raw throughput and capability—Flash-Lite optimizes further down the compute stack for throughput.
Versus competing “fast” models
Gemini 3.1 Flash-Lite outperforming or matching several fast/mini models on many throughput and quality metrics — yet independent analysts caution that direct head-to-head comparisons are sensitive to evaluation methodology and dataset selection. Expect Gemini 3.1 Flash-Lite to be highly competitive in throughput and cost while remaining near the middle of the pack on the highest reasoning metrics.
Conclusion — where Flash-Lite fits in the AI stack
Gemini 3.1 Flash-Lite is a deliberately engineered offering: an efficient, throughput-focused member of the Gemini 3 family that lets teams trade off some per-example compute for dramatic improvements in latency and cost. For businesses and developers building high-volume pipelines — translations, batch processing, streaming UIs, and moderate-complexity agentic tasks — Flash-Lite represents a sensible baseline engine. For organizations that require the absolute highest reasoning fidelity, the Pro models remain the appropriate choice.
If your workload is dominated by many short, repeatable inferences or you need rapid streaming output at large scale, Flash-Lite is worth piloting. If your workload hinges on deep multi-hop reasoning, plan a hybrid approach: route throughput traffic to Flash-Lite and escalate high-value, complex queries to Pro models.
Developers can access Gemini 3.1 Flash Lite via CometAPI now.To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up fo Gemini 3.1 Flash lite today !
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!