GPT-4o Audio API: A unified /chat/completions endpoint extension that accepts Opus-encoded audio (and text) inputs and returns synthesized speech or transcripts with configurable parameters (model=gpt-4o-audio-preview-<date>, speed, temperature) for batch and streaming voice interactions.
Basic infornation of GPT-4o Audio
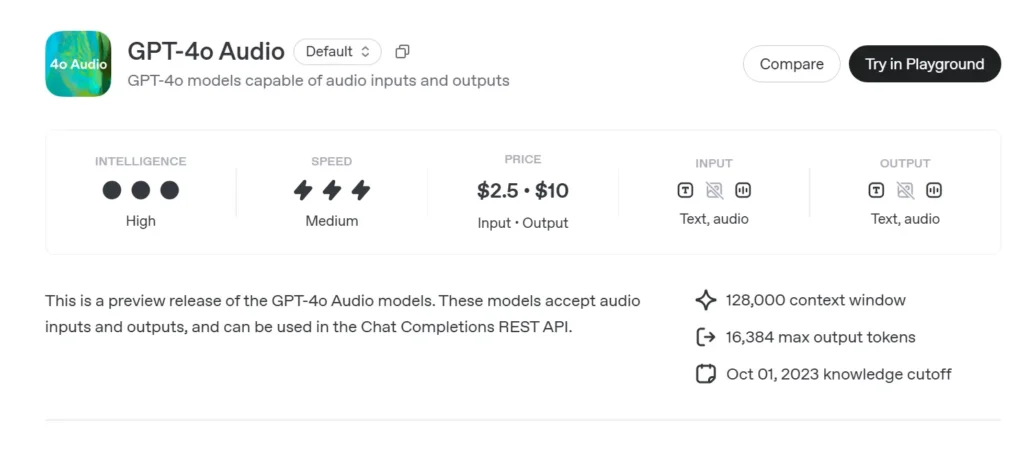
GPT-4o Audio Preview (gpt-4o-audio-preview-2025-06-03) is OpenAI’s newest speech-centric large language model made available through the standard Chat Completions API rather than the ultra-low-latency Realtime channel. Built on the same “omni” foundation as GPT-4o, this variant specialises in high-fidelity speech input and output for turn-based conversations, content creation, accessibility tools, and agentic workflows that do not require millisecond timing. It inherits all text-reasoning strengths of GPT-4-class models while adding end-to-end speech-to-speech (S2S) pipelines, deterministic function calling, and the new speed parameter for voice-rate control.
Core Feature Set of GPT-4o Audio
• Unified Speech-to-Speech Processing – Audio is transformed directly to semantically-rich tokens, reasoned upon, and re-synthesised without external STT/TTS services, yielding consistent voice timbre, prosody, and context retention.
• Improved Instruction Following – June-2025 tuning delivers +19 pp pass-at-1 on voice-command tasks versus the May-2024 GPT-4o baseline, reducing hallucinations in domains such as customer support and content drafting.
• Stable Tool Calling – The model outputs structured JSON that conforms to the OpenAI function-calling schema, enabling backend APIs (search, booking, payments) to be triggered with >95 % argument accuracy.
• speed Parameter (0.25–4×) – Developers can modulate speech playback for slow-paced learning, normal narration, or rapid “audible skim” modes, without re-synthesising text externally.
• Interrupt-Aware Turn-Taking – While not as latency-driven as the Realtime variant, the preview supports partial streaming: tokens are emitted as soon as they are computed, allowing users to interrupt early if necessary.
Technical Architecture of GPT-4o
• Single-Stack Transformer – Like all GPT-4o derivatives, the audio preview employs a unified encoder–decoder where text and acoustic tokens pass through identical attention blocks, promoting cross-modal grounding.
• Hierarchical Audio Tokenisation – Raw 16 kHz PCM → log-mel patches → coarse acoustic codes → semantic tokens. This multi-stage compression achieves 40–50× bandwidth reduction while preserving nuance, enabling multi-minute clips per context window.
• NF4 Quantised Weights – Inference is served at 4-bit Normal-Float precision, cutting GPU memory by half compared to fp16 and sustaining 70+ streaming RTF (real-time factor) on A100-80 GB nodes.
• Streaming Attention & KV Caching – Sliding-window rotary embeddings maintain context over ~30 s of speech while keeping O(L) memory usage, ideal for podcast editors or assistive reading tools.
Versioning & Naming — Preview Track with Date-Stamped Builds
| Identifier | Channel | Purpose | Release Date | Stability |
|---|---|---|---|---|
| gpt-4o-audio-preview-2025-06-03 | Chat Completions API | Turn-based audio interactions, agentic tasks | 03 Jun 2025 | Preview (feedback encouraged) |
Key elements in the name:
- gpt-4o – Omni multimodal family.
- audio – Optimised for speech use-cases.
- preview – API contract may evolve; not yet GA.
- 2025-06-03 – Training & deployment snapshot for reproducibility.
How to call GPT-4o Audio API API from CometAPI
GPT-4o Audio API API Pricing in CometAPI:
- Input Tokens: $2 / M tokens
- Output Tokens: $8 / M tokens
Required Steps
- Log in to cometapi.com. If you are not our user yet, please register first
- Get the access credential API key of the interface. Click “Add Token” at the API token in the personal center, get the token key: sk-xxxxx and submit.
- Get the url of this site: https://api.cometapi.com/
Useage Methods
- Select the “
gpt-4o-audio-preview-2025-06-03” endpoint to send the request and set the request body. The request method and request body are obtained from our website API doc. Our website also provides Apifox test for your convenience. - Replace <YOUR_API_KEY> with your actual CometAPI key from your account.
- Insert your question or request into the content field—this is what the model will respond to.
- . Process the API response to get the generated answer.
For Model Access information in Comet API please see API doc.
For Model Price information in Comet API please see https://api.cometapi.com/pricing.
API Workflow — Chat Completions with Audio Parts & Function Hooks
- Input Format –
audio/*MIME orbase64WAV chunks embedded inmessages[].content. - Output Options –
•mode: "text"→ pure text for captioning.
•mode: "audio"→ returns a streaming Opus or µ-law payload with timestamps. - Function Invocation – Add
functions:schema; the model emitsrole: "function"with JSON arguments; the developer executes the tool call and optionally pipes the result back. - Rate Control – Set
voice.speed=1.25to accelerate playback; safe ranges 0.25–4.0. - Token/Audio Limits – 128 k context (~4 min speech) at launch; 4096 audio tokens / 8192 text tokens whichever first.
Sample Code & API Integration
pythonimport openai
openai.api_key = "YOUR_API_KEY"
# Single-step audio completion (batch)
with open("prompt.wav", "rb") as audio:
response = openai.ChatCompletion.create(
model="gpt-4o-audio-preview-2025-06-03",
messages=[
{"role": "system", "content": "You are a helpful voice assistant."},
{"role": "user", "content": "audio", "audio": audio}
],
temperature=0.3,
speed=1.2 # 20% faster playback
)
print(response.choices.message)
- Highlights:
- model:
"gpt-4o-audio-preview-2025-06-03" - audio key in user message to send binary stream
- speed: Controls voice rate between slow (0.5) and fast (2.0)
- temperature: Balances creativity vs. consistency
Technical Indicators — Latency, Quality, Accuracy
| Metric | Audio Preview | GPT-4o (Text-Only) | Delta |
|---|---|---|---|
| First Token Latency (1-shot) | 1.2 s avg | 0.35 s | +0.85 s |
| MOS (Speech Naturalness, 5-pt) | 4.43 | — | — |
| Instruction Compliance (Voice) | 92 % | 73 % | +19 pp |
| Function Call Arg Accuracy | 95.8 % | 87 % | +8.8 pp |
| Word Error Rate (Implicit STT) | 5.2 % | n/a | — |
| GPU Memory / Stream (A100-80GB) | 7.1 GB | 14 GB (fp16) | −49 % |
Benchmarks executed via Chat Completions streaming, batch size = 1.
See Also GPT-4o Realtime API