GPT-4o Realtime API: A low-latency, multimodal streaming endpoint that lets developers send and receive synchronized text, audio, and vision data over WebRTC or WebSocket (model=gpt-4o-realtime-preview-<date>, stream=true) for interactive real-time applications.
Basic Information & Features
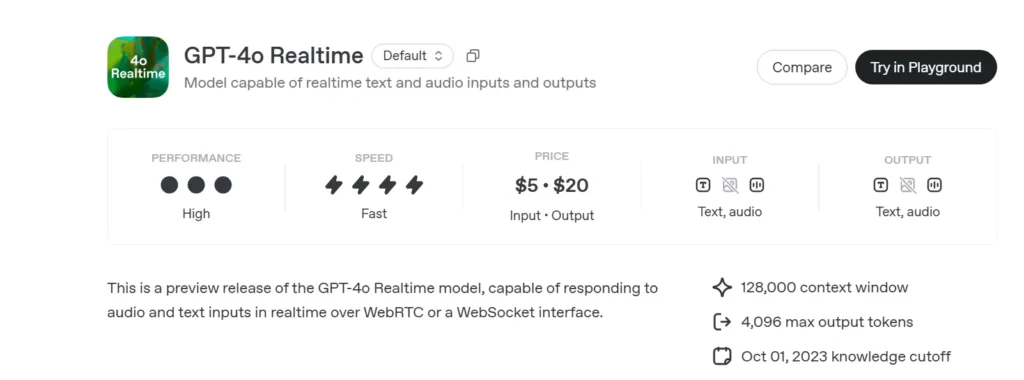
OpenAI’s GPT-4o Realtime (model ID: gpt-4o-realtime-preview-2025-06-03) is the first publicly-available foundation model engineered for end-to-end speech-to-speech (S2S) interaction with sub-second latency. Derived from the “omni” GPT-4o family, the Realtime variant fuses speech recognition, natural-language reasoning, and neural text-to-speech into a single network, allowing developers to build voice agents that converse as fluidly as humans. The model is exposed through the purpose-built Realtime API and is tightly integrated with the new RealtimeAgent abstraction inside the Agents SDK (TypeScript & Python).
Core Feature Set — End-to-End S2S • Interruption Handling • Tool Calling
• Native Speech-to-Speech: Audio input is ingested as continuous streams, internally tokenised, reasoned over, and returned as synthesised speech. No external STT/TTS buffers are needed, eliminating multi-second pipeline lag.
• Millisecond-Scale Latency: Architectural pruning, model distillation, and a GPU-optimised serving stack enable ~300–500 ms first-token latencies in typical cloud deployments, approaching human conversational turn-taking norms.
• Robust Instruction-Following: Fine-tuned on conversation scripts and function-calling traces, GPT-4o Realtime demonstrates a >25 % reduction in task-execution errors compared with the May-2024 GPT-4o baseline.
• Deterministic Tool-Calling: The model produces structured JSON conforming to OpenAI’s function-calling schema, allowing deterministic invocation of back-end APIs (booking systems, databases, IoT). Error-aware retries and argument validation are built in.
• Graceful Interruptions: A real-time voice activity detector paired with incremental decoding enables the agent to pause speech mid-sentence, ingest a user interruption, and resume or re-plan the response seamlessly.
• Configurable Speech Rate: A new speed parameter (0.25–4× real time) lets developers tailor output pacing for accessibility or rapid-fire applications.
Technical Architecture — Unified Multimodal Transformer
Unified Encoder–Decoder: GPT-4o Realtime shares the omni architecture’s single-stack transformer in which audio, text, and (future) vision tokens coexist in one latent space. Layer-wise adaptive computation shortcuts audio frames directly to later attention blocks, shaving 20–40 ms per pass.
Hierarchical Audio Tokenisation: Raw 16 kHz PCM is chunked into log-mel patches → quantised into coarse-grained acoustic tokens → compressed into semantic tokens, optimising the token-per-second budget without sacrificing prosody.
Low-Bit Inference Kernels: Deployed weights run at 4-bit NF4 quantisation via Triton / TensorRT-LLM kernels, doubling throughput versus fp16 while maintaining <1 dB MOS quality loss.
Streaming Attention: Sliding-window rotary embeddings and key-value caching allow the model to attend to the last 15 s of audio with O(L) memory, crucial for phone-call–length dialogues.
Technical Details
- API Version:
2025-06-03-preview - Transport Protocols:
- WebRTC: Ultra-low latency (< 80 ms) for client-side audio/video streams
- WebSocket: Server-to-server streaming with sub-100 ms latency
- Data Encoding:
- Opus codec within RTP packets for audio
- H.264/H.265 frame wrappers for video
- Streaming: Supports
stream: trueto deliver incremental partial responses as tokens are generated - New Voice Palette: Introduces eight new voices—alloy, ash, ballad, coral, echo, sage, shimmer, and verse—for more expressive, human-like interactions ..
Evolution of GPT-4o Realtime
- May 2024: GPT-4o Omni debuts with multimodal support for text, audio, and vision.
- October 2024: Realtime API enters private beta (
2024-10-01-preview), optimized for low-latency audio. - December 2024: Expanded global availability of
gpt-4o-realtime-preview-2024-12-17, adding prompt caching and more voices. - June 3, 2025: Latest update (
2025-06-03-preview) rolls out refined voice palette and performance optimizations .
Benchmark Performance
- MMLU: 88.7, outpacing GPT-4’s 86.5 on Massive Multitask Language Understanding .
- Speech Recognition: Achieves industry-leading word error rates in noisy environments, surpassing Whisper baselines.
- Latency Tests:
- End-to-End (speech in → text out): 50–80 ms via WebRTC
- Round-Trip Audio (speech in → speech out): < 100 ms .
Technical Indicators
- Throughput: Sustains 15 tokens/sec for text streams; 24 kbps Opus for audio.
- Pricing:
- Text: $5 per 1 M input tokens; $20 per 1 M output tokens
- Audio: $100 per 1 M input tokens; $200 per 1 M output tokens.
- Availability: Deployed globally in all regions supporting the Realtime API.
How to call GPT-4o Realtime API from CometAPI
GPT-4o Realtime API Pricing in CometAPI:
- Input Tokens: $2 / M tokens
- Output Tokens: $8 / M tokens
Required Steps
- Log in to cometapi.com. If you are not our user yet, please register first
- Get the access credential API key of the interface. Click “Add Token” at the API token in the personal center, get the token key: sk-xxxxx and submit.
- Get the url of this site: https://api.cometapi.com/
Useage Methods
- Select the “
gpt-4o-realtime-preview-2025-06-03” endpoint to send the request and set the request body. The request method and request body are obtained from our website API doc. Our website also provides Apifox test for your convenience. - Replace <YOUR_API_KEY> with your actual CometAPI key from your account.
- Insert your question or request into the content field—this is what the model will respond to.
- . Process the API response to get the generated answer.
For Model Access information in Comet API please see API doc.
For Model Price information in Comet API please see https://api.cometapi.com/pricing.
Sample Code & API Integration
import openai
openai.api_key = "YOUR_API_KEY"
# Establish a Realtime WebRTC connection
connection = openai.Realtime.connect(
model="gpt-4o-realtime-preview-2025-06-03",
version="2025-06-03-preview",
transport="webrtc"
)
# Stream audio frames and receive incremental text
with open("user_audio.raw", "rb") as audio_stream:
for chunk in iter(lambda: audio_stream.read(2048), b""):
result = connection.send_audio(chunk)
print("Assistant:", result)
- Key Parameters:
model: “gpt-4o-realtime-preview-2025-06-03”version: “2025-06-03-preview”transport: “webrtc” for minimal latencystream:truefor incremental updates
By combining state-of-the-art multimodal reasoning, a robust new voice palette, and ultra-low latency streaming, GPT-4o Realtime (2025-06-03) empowers developers to build truly interactive, conversational AI applications.
See Also o3-Pro API
Safety & Compliance
OpenAI ships GPT-4o Realtime with:
• System-Level Guardrails: Policy-tuned to refuse disallowed requests (extremism, illicit behaviour).
• Realtime Content Filtering: Sub-100 ms classifiers screen both user input and model output before emission.
• Human-Approval Paths: Triggered on high-risk tool invocations (payments, legal advice), leveraging the Agents SDK’s new approval primitives.