
Gemini 2.5 Flash API adalah model AI multimodal terbaru Google, yang dirancang untuk tugas-tugas berkecepatan tinggi dan hemat biaya dengan kemampuan penalaran yang dapat dikontrol, yang memungkinkan pengembang untuk mengaktifkan atau menonaktifkan fitur “berpikir” tingkat lanjut melalui Gemini API. Model Terbaru adalah gemini-2.5-flash.
Tinjauan Umum Gemini 2.5 Flash
Gemini 2.5 Flash dirancang untuk memberikan respons cepat tanpa mengurangi kualitas output. Model ini mendukung input multimoda, termasuk teks, gambar, audio, dan video, sehingga cocok untuk berbagai aplikasi. Model ini dapat diakses melalui platform seperti Google AI Studio dan Vertex AI, yang menyediakan alat yang diperlukan pengembang untuk integrasi yang lancar ke berbagai sistem.
Informasi Dasar (Fitur)
Gemini 2.5 Flash memperkenalkan beberapa fitur menonjol fitur yang membedakannya dalam keluarga Gemini 2.5:
- Penalaran Hibrida:Pengembang dapat mengatur anggaran_berpikir parameter untuk mengontrol secara tepat berapa banyak token yang didedikasikan model untuk penalaran internal sebelum keluaran.
- Batas Pareto: Diposisikan di titik biaya-kinerja optimal, Flash menawarkan rasio harga-kecerdasan terbaik di antara 2.5 model.
- Dukungan Multimoda: Proses teks, gambar, video, dan audio secara asli, memungkinkan kemampuan percakapan dan analitis yang lebih kaya.
- Konteks 1 Juta Token: Panjang konteks yang tak tertandingi memungkinkan analisis mendalam dan pemahaman dokumen yang panjang dalam satu permintaan.
Versi Model
Gemini 2.5 Flash telah beralih melalui kunci berikut Versi:
- gemini-2.5-flash-lite-preview-09-2025: Kegunaan alat yang ditingkatkan: Performa yang lebih baik pada tugas-tugas kompleks dan multi-langkah, dengan peningkatan skor SWE-Bench Verified sebesar 5% (dari 48.9% menjadi 54%). Efisiensi yang lebih baik: Dengan mengaktifkan penalaran, output berkualitas lebih tinggi dicapai dengan lebih sedikit token, sehingga mengurangi latensi dan biaya.
- Pratinjau 04-17:Rilis akses awal dengan kemampuan “berpikir”, tersedia melalui gemini-2.5-flash-pratinjau-04-17.
- Ketersediaan Umum Stabil (GA):Pada tanggal 17 Juni 2025, titik akhir stabil gemini-2.5-kilat menggantikan pratinjau, memastikan keandalan tingkat produksi tanpa perubahan API dari pratinjau 20 Mei.
- Penghentian Pratinjau: Titik akhir pratinjau dijadwalkan untuk dimatikan pada 15 Juli 2025; pengguna harus bermigrasi ke titik akhir GA sebelum tanggal ini.
Pada bulan Juli 2025, Gemini 2.5 Flash sekarang tersedia untuk umum dan stabil (tidak ada perubahan dari gemini-2.5-flash-pratinjau-05-20 ).Jika Anda menggunakan gemini-2.5-flash-preview-04-17, harga pratinjau yang ada akan berlanjut hingga penghentian titik akhir model yang dijadwalkan pada 15 Juli 2025, saat titik akhir tersebut akan dihentikan. Anda dapat bermigrasi ke model yang tersedia secara umum “gemini-2.5-flash".
Lebih cepat, lebih murah, lebih cerdas:
- Sasaran desain: latensi rendah + throughput tinggi + biaya rendah;
- Peningkatan kecepatan secara keseluruhan dalam penalaran, pemrosesan multimodal, dan tugas teks panjang;
- Penggunaan token berkurang 20–30%, sehingga mengurangi biaya penalaran secara signifikan.
Spesifikasi teknis
Jendela Konteks Input: Hingga 1 juta token, memungkinkan retensi konteks yang luas.
Token Keluaran: Mampu menghasilkan hingga 8,192 token per respons.
Modalitas yang Didukung: Teks, gambar, audio, dan video.
Platform Integrasi: Tersedia melalui Google AI Studio dan Vertex AI.
Harga: Model harga berbasis token yang kompetitif, memfasilitasi penerapan yang hemat biaya.
Rincian Teknis
Di balik kapnya, Gemini 2.5 Flash adalah berbasis transformator model bahasa besar yang dilatih pada campuran data web, kode, gambar, dan video. Kunci teknis spesifikasi meliputi:
Pelatihan Multimoda:Dilatih untuk menyelaraskan beberapa modalitas, Flash dapat dengan mudah mencampur teks dengan gambar, video, atau audio, berguna untuk tugas seperti peringkasan video atau pemberian teks audio.
Proses Berpikir Dinamis: Menerapkan loop penalaran internal di mana model rencana dan memecah perintah yang rumit sebelum keluaran akhir.
Anggaran Berpikir yang Dapat Dikonfigurasi: Para anggaran_berpikir dapat diatur dari 0 (tidak ada alasan) sampai 24,576 token, yang memungkinkan adanya keseimbangan antara latensi dan kualitas jawaban.
Integrasi Alat: Mendukung Grounding dengan Google Search, Eksekusi Kode, Konteks URL, dan Pemanggilan Fungsi, memungkinkan tindakan di dunia nyata langsung dari perintah bahasa alami.
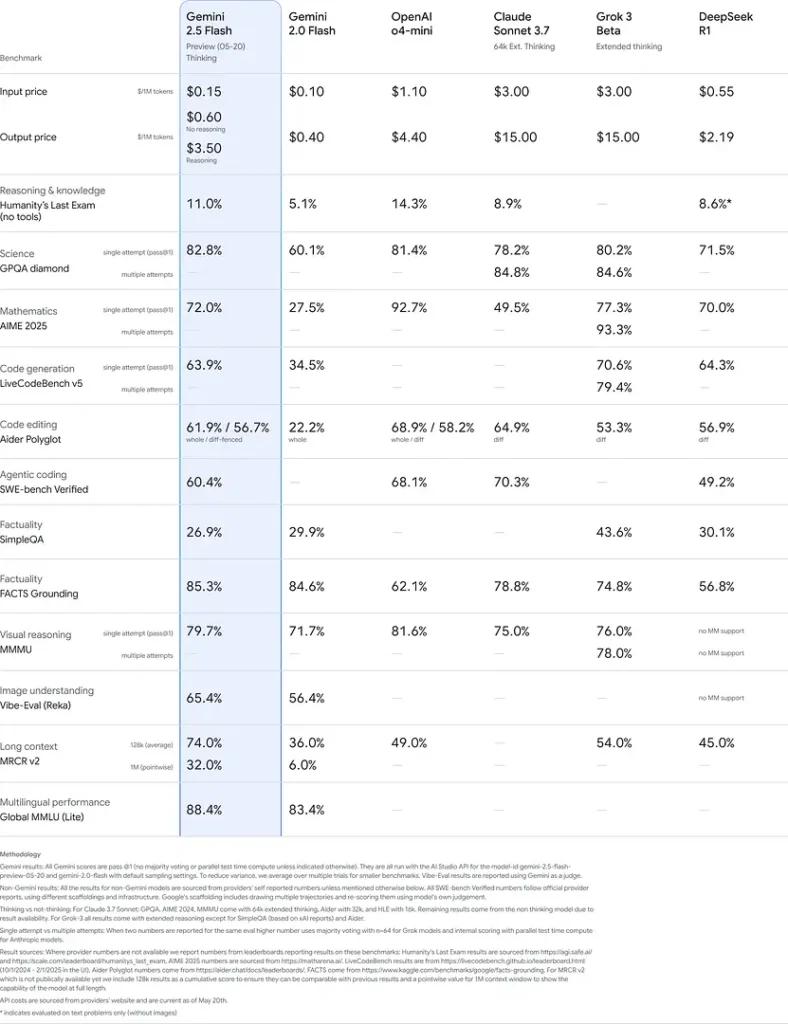
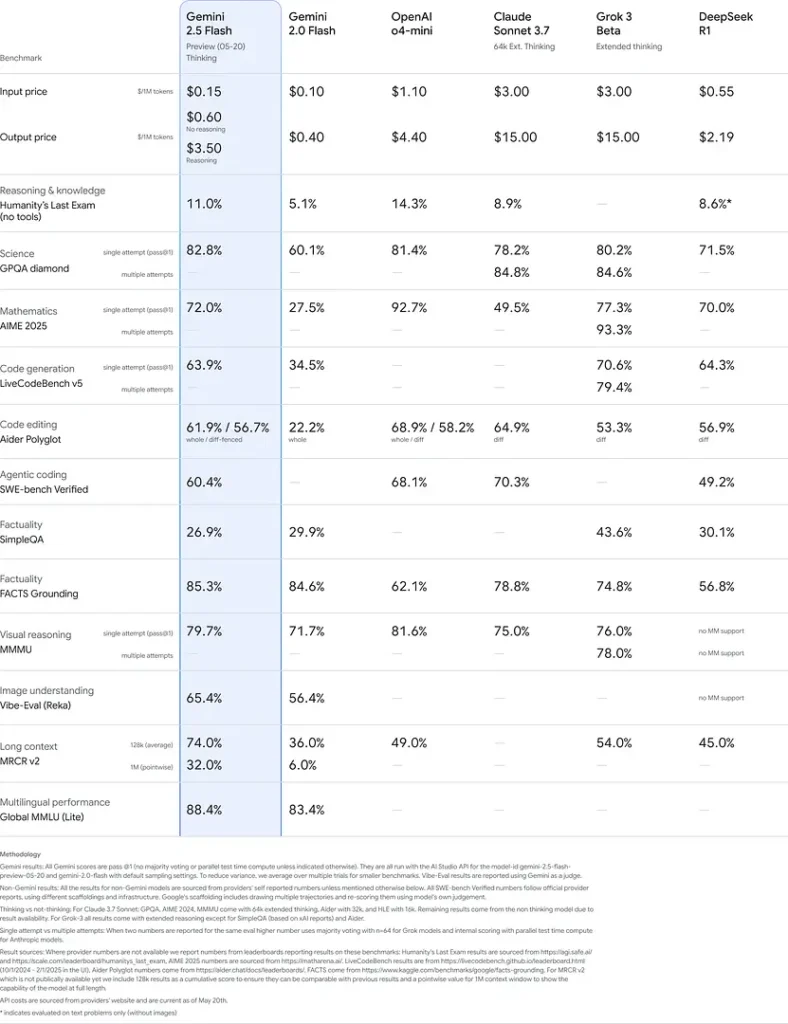
Kinerja Tolok Ukur
Dalam evaluasi yang ketat, Gemini 2.5 Flash menunjukkan industri terkemuka kinerja:
- Prompt Keras LMArena: Dinilai kedua setelah 2.5 Pro pada tolok ukur Hard Prompts yang menantang, menampilkan kemampuan penalaran multi-langkah yang kuat.
- Skor MMLU 0.809:Melebihi kinerja model rata-rata dengan 0.809 Keakuratan MMLU, mencerminkan pengetahuan domain yang luas dan kecakapan penalarannya.
- Latensi dan Throughput: Mencapai 271.4 token/detik kecepatan decoding dengan 0.29 dtk Waktu-ke-Token-Pertama, membuatnya ideal untuk beban kerja yang sensitif terhadap latensi.
- Pemimpin Harga-ke-Kinerja: Di $0.26/1 juta token, Flash mengalahkan banyak pesaingnya namun menyamai atau melampaui mereka pada tolok ukur utama.
Hasil ini menunjukkan keunggulan kompetitif Gemini 2.5 Flash dalam penalaran, pemahaman ilmiah, pemecahan masalah matematika, pengkodean, interpretasi visual, dan kemampuan multibahasa:
keterbatasan
Meskipun bertenaga, Gemini 2.5 Flash membawa beberapa keterbatasan:
- Risiko Keamanan:Model tersebut dapat menunjukkan nada “mengkhotbahi” dan mungkin menghasilkan keluaran yang terdengar masuk akal tetapi salah atau bias (halusinasi), terutama pada kueri kasus khusus. Pengawasan manusia yang ketat tetap penting.
- Batasan Tarif: Penggunaan API dibatasi oleh batas kecepatan (10 RPM, 250,000 TPM, 250 RPD pada tingkatan default), yang dapat memengaruhi pemrosesan batch atau aplikasi bervolume tinggi.
- Lantai Intelijen:Meskipun sangat mampu untuk flash modelnya, namun tetap kurang akurat dibandingkan 2.5 Pro pada tugas agen yang paling menantang seperti pengkodean tingkat lanjut atau koordinasi multi-agen.
- Pertukaran Biaya:Meskipun menawarkan yang terbaik harga-kinerja, penggunaan yang luas dari pikir mode meningkatkan konsumsi token secara keseluruhan, meningkatkan biaya untuk perintah penalaran yang mendalam.
Lihat Juga Gemini 2.5 Pro API
Kesimpulan
Gemini 2.5 Flash merupakan bukti komitmen Google untuk memajukan teknologi AI. Dengan kinerja yang tangguh, kemampuan multimoda, dan manajemen sumber daya yang efisien, ia menawarkan solusi komprehensif bagi pengembang dan organisasi yang ingin memanfaatkan kekuatan kecerdasan buatan dalam operasi mereka.
Bagaimana cara menelepon Gemini 2.5 Flash API dari CometAPI
Gemini 2.5 Flash Harga API di CometAPI, diskon 20% dari harga resmi:
- Token Masukan: $0.24 / Jt token
- Token Keluaran: $0.96/M token
Langkah-langkah yang Diperlukan
- Masuk ke cometapi.comJika Anda belum menjadi pengguna kami, silakan mendaftar terlebih dahulu
- Dapatkan kunci API kredensial akses antarmuka. Klik “Tambahkan Token” pada token API di pusat personal, dapatkan kunci token: sk-xxxxx dan kirimkan.
- Dapatkan url situs ini: https://api.cometapi.com/
Metode Penggunaan
- Pilih "
gemini-2.5-flash” untuk mengirim permintaan API dan mengatur isi permintaan. Metode permintaan dan isi permintaan diperoleh dari dokumen API situs web kami. Situs web kami juga menyediakan pengujian Apifox demi kenyamanan Anda. - Mengganti dengan kunci CometAPI Anda yang sebenarnya dari akun Anda.
- Masukkan pertanyaan atau permintaan Anda ke dalam kolom konten—inilah yang akan ditanggapi oleh model.
- Memproses respons API untuk mendapatkan jawaban yang dihasilkan.
Untuk informasi Model yang diluncurkan di Comet API silakan lihat https://api.cometapi.com/new-model.
Untuk informasi Harga Model di Comet API silakan lihat https://api.cometapi.com/pricing.
Contoh Penggunaan API
Pengembang dapat berinteraksi dengan gemini-2.5-kilat melalui API CometAPI, yang memungkinkan integrasi ke berbagai aplikasi. Berikut adalah contoh Python:
import os
from openai import OpenAI
client = OpenAI(
base_url="
https://api.cometapi.com/v1/chat/completions",
api_key="<YOUR_API_KEY>",
)
response = openai.ChatCompletion.create(
model="gemini-2.5-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the concept of quantum entanglement."}
]
)
print(response)
Skrip ini mengirimkan prompt ke Gemini 2.5 Flash model dan mencetak respons yang dihasilkan, menunjukkan cara memanfaatkan Gemini 2.5 Flash untuk penjelasan yang rumit.